







ScanQA: 3D Question Answering for Spatial Scene Understanding
输入:点云P和问题Q,输出:答案A
点云p由三维坐标点组成。本文模型使用额外的点云特征:点云高度、颜色、法线和多视图图像特征,这些特征将 2D 外观特征投影到点云上。将上面这些特征结合,作为模型的3d特征。
ScanQA model网络结构:
模型包括3D &language encoder, 3D & language fusion, and object localization & QA layers
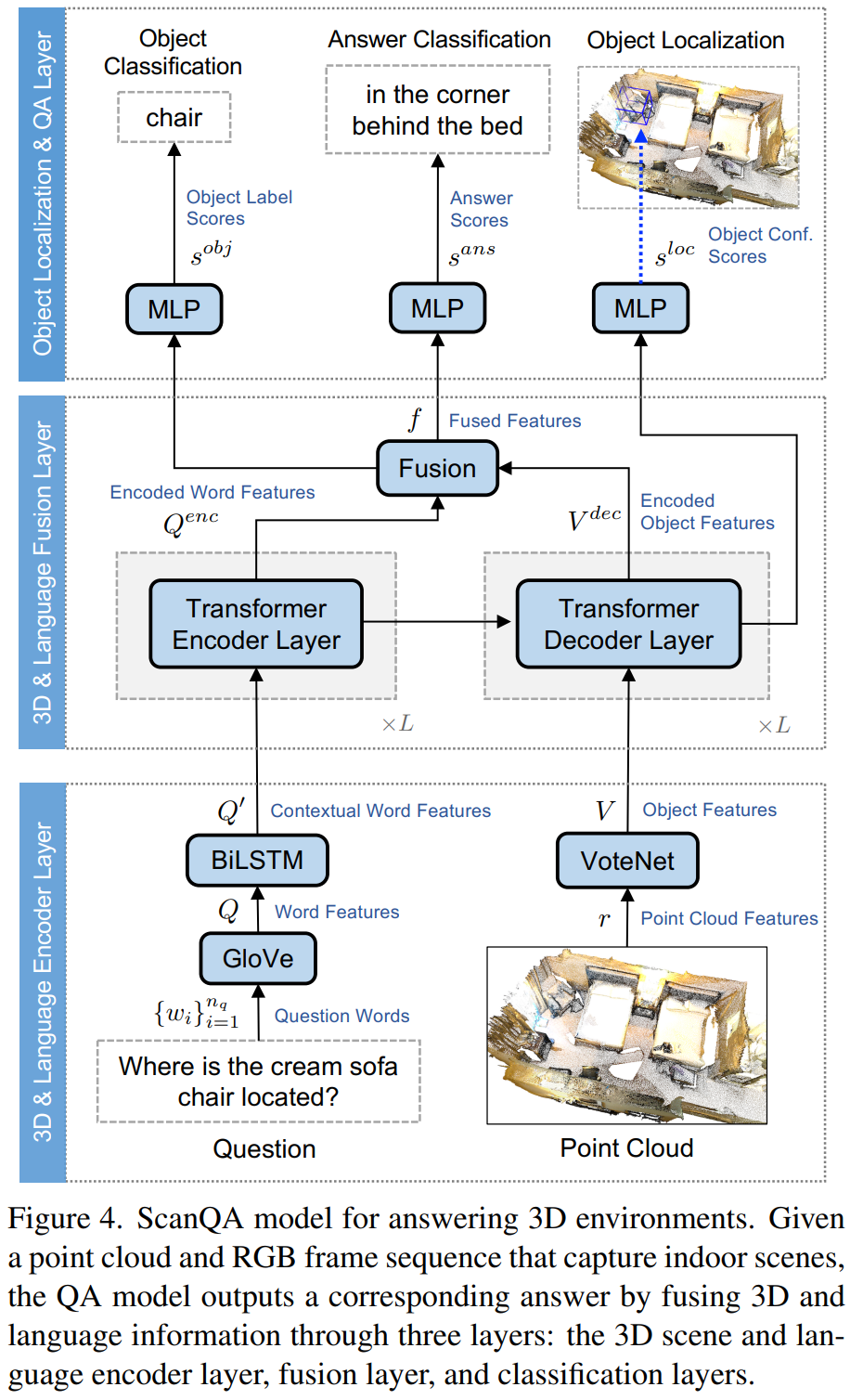
VoteNet的骨干网络是PointNet++,VoteNet的输入是3d特征,输出的是物体候选区域,然后使用非线性层候选物体的表示。
transformer encoder提供K和V
Fusion是一个带有注意力的两层MLP
最上面一层目标定位Object localization module模块是用于决定VoteNet输出的目标框属于该问题的最大似然,也就是,网络会生成很多框,但是只有一部分是和问题相关的,这个模块要把它选出来。使用CEloss。
Object classification module预测了什么物体是和问题有关系的。CEloss。
Answer classification module预测问题的答案。
LOSS:
VoteNet有个检测损失Ldet,还有最上面三个模块的定位损失Lloc,分类损失Lobj,答案损失Lans,四者相加。L = Lans + Lobj + Lloc + Ldet


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









