







Unified Generative Adversarial Networks for Controllable Image-to-Image Translation
主要贡献:
提出了一种用于可控图像到图像翻译任务的统一 GAN 模型,该模型可以在野外生成具有任意姿势、大小、结构和位置的目标图像。
提出了三个新的目标函数来更好地优化所提出的 GAN 模型,即颜色损失、可控结构引导循环一致性损失和自我内容保留损失。
提出了一种高效的Fréchet ResNet Distance (FRD) 度量来评估真实图像和生成图像的相似性,这更符合人类的判断。
定性和定量结果表明,在具有四个数据集的两个具有挑战性的可控图像翻译任务(即手势到手势翻译和跨视图图像翻译)上,所提出的 GAN 模型相对于最先进的方法具有优越性。
模型:
模型
可控结构引导生成器
我们将来自源域的输入条件图像x和来自目标域的可控结构Cy输入到生成器G中并合成目标图像y = G(x, Cy) 这样,GT可控结构Cy提供了更强的监督和结构信息来指导深层网络中图像到图像的转换,而条件图像x提供了外观信息以产生最终结果y。
可控结构引导循环
在可控结构Cy的引导下,我们的生成器可以产生相应的图像y。 我们同时考虑图像平移过程和图像重建过程,即从源域到目标域以及从目标域回到源域。
可控结构引导循环一致性损失
介绍了配对图像到图像翻译任务的可控结构引导循环一致性损失。 这种损失保证了源图像和重建图像之间的一致性
![]()
损失函数:
颜色损失:
传统的L1或L2损失计算过程中,三个通道的损失一起算,一个通道总是受到其他通道误差的影响。 本文独立计算每个通道的损失,可以避免这种影响。 这样,一个通道的错误就不会影响其他通道。 这种新颖的损失可以提高我们实验部分的图像质量。
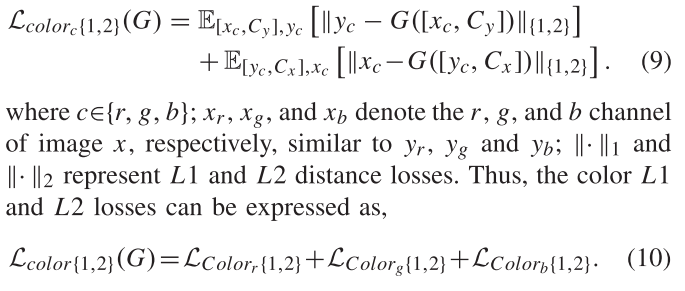
可控结构引导的自我内容保存损失:
这个就是当输入条件是自我内容(self-content)时生成的图片应该是输入图片自己。
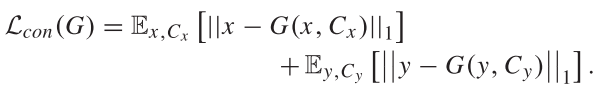
感知损失:
测量生成图片和原始图片在高级特征空间中的感知相似性
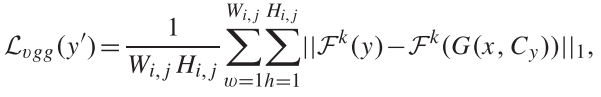
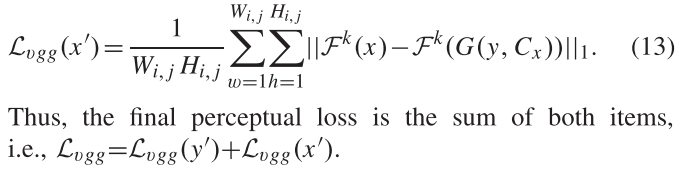
总变异损失:
缓解GAN模型合成的图像的伪影
通过使平移后的生成图片和原始图片差值为0来实现。
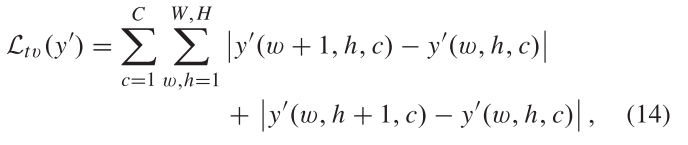
生成器:来自 《Perceptual losses for real-time style transfer and super-resolution》
判别器:PatchGAN
提出了新的度量方式:Fréchet ResNet Distance (FRD)
实验
在手势到手势变换任务上,模型始终生成更清晰的图像,并具有令人信服的细节。 我们还注意到,所提出的 GAN 模型比现有方法更稳健
在跨视图图像变换任务上:我们的方法在生成的地面图像中比 SelectionGAN 生成了更清晰的物体/场景(如道路、树木和云)细节。 对于生成的航拍图像,我们可以观察到草、树和房屋屋顶与其他图像相比渲染得很好。 此外,我们的方法生成的结果在布局和结构上更接近真实情况。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









