







 文章介绍了在李宏毅老师的课程中,Q-learning算法中调整动作概率的方法,强调了为何需要除以概率值进行归一化,以及在R值为正时如何考虑出现频率和基线问题。该方法涉及对动作进行加权更新,确保模型不会过度偏好高频动作。
文章介绍了在李宏毅老师的课程中,Q-learning算法中调整动作概率的方法,强调了为何需要除以概率值进行归一化,以及在R值为正时如何考虑出现频率和基线问题。该方法涉及对动作进行加权更新,确保模型不会过度偏好高频动作。
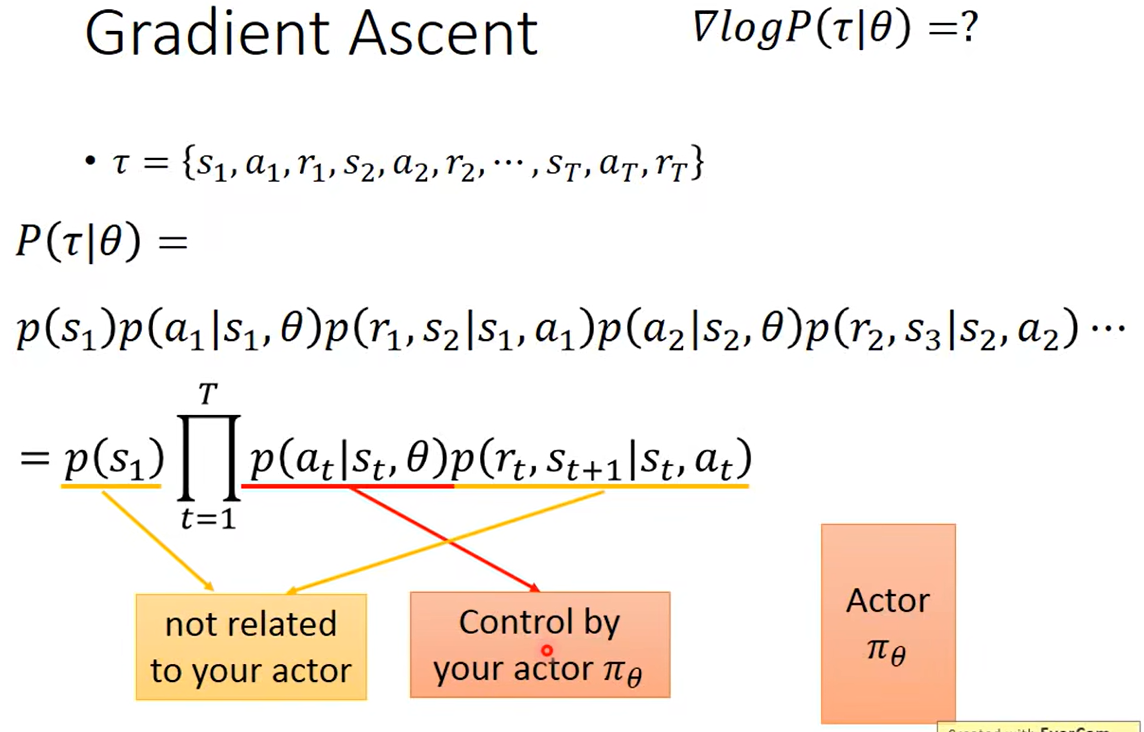
李宏毅老师的课件
https://www.bilibili.com/video/BV1XP4y1d7Bk/?spm_id_from=333.337.search-card.all.click&vd_source=e7939b5cb7bc219a05ee9941cd297ade




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+
05-05

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









