









1. 缺失值处理
处理原则:1.删除,2.以某种形式的值填充
1.1 缺失值的查看
info()可以查看缺失值

- isnull()可以判断哪个值是缺失值,如果是返回True,否返回False
1.2 缺失值的删除
# 只要某一行有缺失值就把这一行删除
df.dropna()
# 如果只想删除空白行
df.dropna(how=all)
1.3 缺失值的填充
#括号内填要填充的值
df.fillna()
# 按照不同的列填充
df.fillna({'列名1':'要填充的值1','列名2':'要填充的值2'})
2. 重复值处理
#对所有值进行重复值判断,且默认保留第一行的值
df.drop_duplicates()
#针对某些字段的值进行重复值判断,且默认保留第一行的值
#keep=first保留第一行,last最后一行,false重复值全删除
df.drop_duplicates(subset=['列名1','列名2'],keep='first')
3. 异常值的检测与处理
3.1 异常值的处理
异常值的检测可以用各种数学方法。
处理:筛选后再删除或者用replace()替换
4. 数据类型的转换

- 数据类型的查看:df.info()或者df.dtype
- 数据转换为int类型:df.astype(‘int’)
5. 索引设置
5.1 为无索引表添加索引


5.2 重新设置索引
将表中的指定列为新的行索引

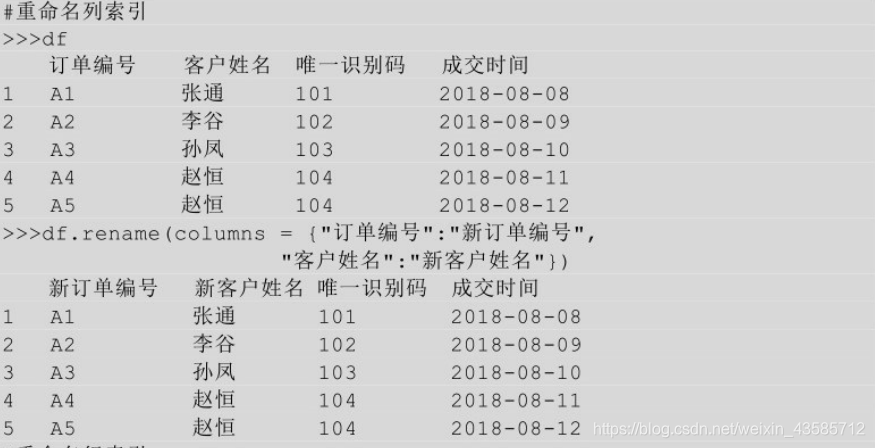
5.3 重命名索引
针对现有的索引进行修改,就是改字段名。

5.4 重置索引
重置索引主要用在层次化索引表中,重置索引是将索引列当作一个columns进行返回。
















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









