







1.k-means的优缺点,其他分类方法
缺点:
(1)对于离群点和孤立点敏感; 离群点检测的LOF算法,通过去除离群点后再聚类,可以减少离群点和孤立点对于聚类效果的影响。
(2)k值选择;
(3)初始聚类中心的选择;
(4)只能发现球状簇。
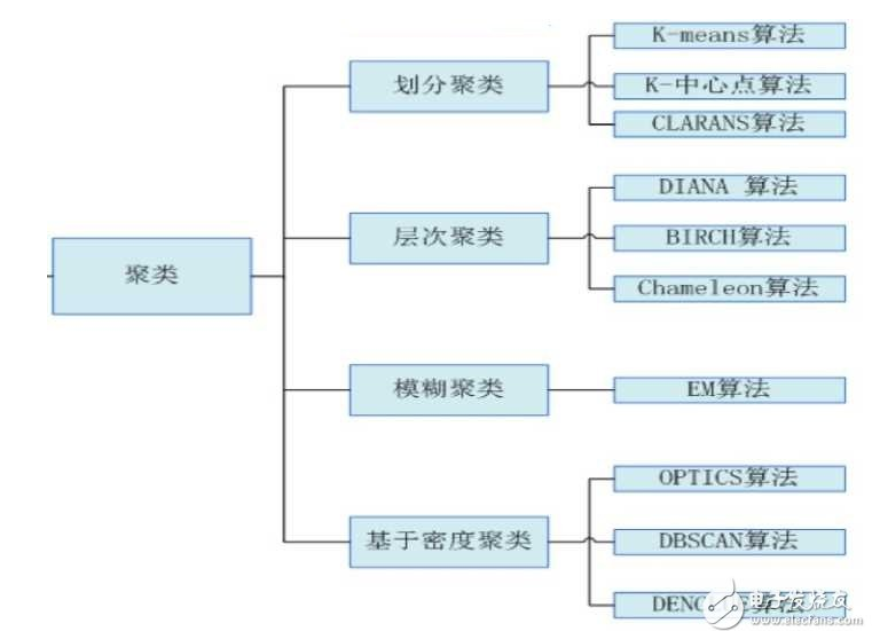
2.怎么样检查异常点?
马氏距离更适合来判断样本点与数据集的位置关系,判断其是否离群。正态概率图、箱形图、散点图都比较直观,容易判断出错,还有3detla原则(基于小概率事件不可能发生)。
箱型图提供了一个识别异常值的标准,即大于或小于箱型图设定的上下界的数值即为异常值。
3.当数据量很大的时候,怎么样检索新的数据在不在?
哈希表=散列表=字典
哈希表(Hash table,也叫散列表),具有像数组那样根据随机访问的特性,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
4.动态规划和贪心算法的区别
能采用动态规划求解的问题的一般要具有3个性质:
- 最优化子结构:如果问题的最优解所包含的子问题的解也是最优的。
- 无后效性:某状态以后的过程只与当前状态有关,贪心算法也是。
- 贪心算法是用所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
动态规划是通过挑选子问题的解找出最优解。
动态规划算法通常以自底向上(具体-抽象)的方式解各子问题,而贪心算法则通常以自顶向下(抽象-具体)的方式进行。
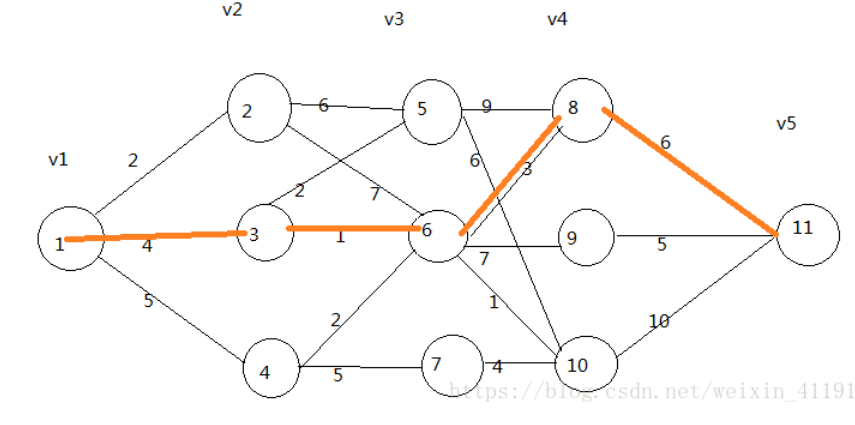
按照贪心算法的思路:v1到v2:1到2最短,所以选择2,总长s为2。v2到v3:2到5最短,所以选择5,总长为2+6=8。v3到v4:5到10最短,所以选择10,总长为8+6=14。v4到v5:10到11,总长为14+10=24。所以最短路径为1,2,5,10,11。
按照动态规划的思路:
v1到v2: 2,v1到v3:4 ,v1到v3: 5先记录下来,不做选择
v2到v5/v6: 6/7, v3到v5/v6: 2/1, v4到v6/v7: 2/5, 与第一层的连接,最短路径为1到3到6:5
同理,再与第三场联接与上一次的最优结果再做出选择:1到3到6到8:8
最终最短路径是:1,3,6,8,11。
5.样本不平衡怎么处理?
1.产生新数据型:过采样小样本(SMOTE),欠采样大样本。
2.通过组合集成方法解决:是指将多数类数据随机分成少数类数据的量N份,每一份与全部的少数类数据一起训练成为一个分类器,这样反复训练会生成很多的分类器。最后再用组合的方式(bagging或者boosting)对分类器进行组合,得到更好的预测效果。
3.更改权值:为少数类样本赋予更大的权值,为多数类样本赋予较小的权值。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









