







用户可以通过spark.udf功能添加自定义函数,实现自定义功能
1.UDF
步骤:
- 创建DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
- 注册UDF
scala> spark.udf.register("addName",(x:String)=> "Name:"+x)
res9: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,StringType,Some(List(StringType)))
- 创建临时表
scala> df.createOrReplaceTempView("people")
- 应用UDF
scala> spark.sql("Select addName(name),age from people").show()
2 UDAF
2.1 UDAF原理
需求:计算平均工资
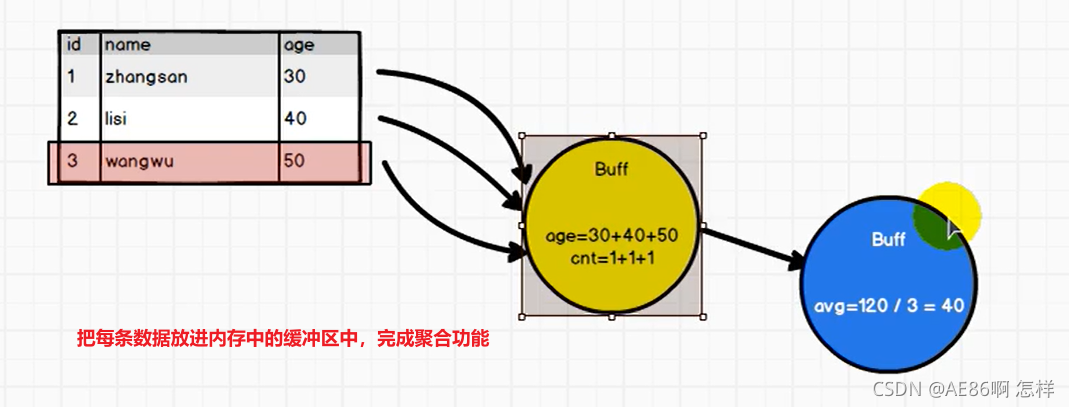
一个需求可以采用很多种不同的方法实现需求
1) 实现方式 - RDD
val conf: SparkConf = new SparkConf().setAppName("app").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val res: (Int, Int) = sc.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangw", 40))).map {
case (name, age) => {
(age, 1)
}
}.reduce {
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
}
println(res._1/res._2)
// 关闭连接
sc.stop()
2) 实现方式 - 累加器
class MyAC extends AccumulatorV2[Int,Int]{
var sum:Int = 0
var count:Int = 0
override def isZero: Boolean = {
return sum ==0 && count == 0
}
override def copy(): AccumulatorV2[Int, Int] = {
val newMyAc = new MyAC
newMyAc.sum = this.sum
newMyAc.count = this.count
newMyAc
}
override def reset(): Unit = {
sum =0
count = 0
}
override def add(v: Int): Unit = {
sum += v
count += 1
}
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
other match {
case o:MyAC=>{
sum += o.sum
count += o.count
}
case _=>
}
}
override def value: Int = sum/count
}
3) 实现方式 - UDAF - 弱类型
强类型的Dataset和弱类型的DataFrame都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。
- 通过继承
UserDefinedAggregateFunction来实现用户自定义弱类型聚合函数。 - 从Spark3.0版本后,
UserDefinedAggregateFunction已经不推荐使用了。可以统一采用强类型聚合函数Aggregator - 弱类型的特点就是只能通过ROW的索引获取对应的字段,强类型可以直接通过类的属性获取
/*
定义类继承UserDefinedAggregateFunction,并重写其中方法
*/
class MyAveragUDAF extends UserDefinedAggregateFunction {
// 聚合函数输入参数的数据类型
def inputSchema: StructType = StructType(Array(StructField("age",IntegerType)))
// 聚合函数缓冲区中值的数据类型(age,count)
def bufferSchema: StructType = {
StructType(Array(StructField("sum",LongType),StructField("count",LongType)))
}
// 函数返回值的数据类型
def dataType: DataType = DoubleType
// 稳定性:对于相同的输入是否一直返回相同的输出。
def deterministic: Boolean = true
// 函数缓冲区初始化
def initialize(buffer: MutableAggregationBuffer): Unit = {
// 存年龄的总和
buffer(0) = 0L
// 存年龄的个数
buffer(1) = 0L
}
// 更新缓冲区中的数据
def update(buffer: MutableAggregationBuffer,input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getInt(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 合并缓冲区
def merge(buffer1: MutableAggregationBuffer,buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
。。。
//创建聚合函数
var myAverage = new MyAveragUDAF
//在spark中注册聚合函数
spark.udf.register("avgAge",myAverage)
spark.sql("select avgAge(age) from user").show()
4) 实现方式 - UDAF - 强类型
package SparkSQL
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.Aggregator
object _03_UDAF {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val df: DataFrame = spark.read.json("input/user.json")
df.createOrReplaceTempView("user")
//todo 注册自定义函数
//sql不关注类型,所以将强类型操作转换为弱类型
spark.udf.register("ageAvg",functions.udaf(new MyAvgUDAF()))
spark.sql("select ageAvg(age) from user").show
//+--------------+
//|myavgudaf(age)|
//+--------------+
//| 20|
//+--------------+
spark.close()
}
}
//todo 1.自定义聚合函数:计算年龄平均值
//1.继承org.apache.spark.sql.expressions.Aggregator
//2.泛型 IN:输入数据类型 BUF:buffer中的数据类型 OUT:输出的数据类型
case class Buff(var total:Long,var count:Long)
//用样例类作为缓冲区的数据类型,total是总的薪资,count是个数
//用var修饰属性,是因为银行里类默认是val不能修改
class MyAvgUDAF extends Aggregator[Long,Buff,Long] {
//todo 3.缓冲区初始化
override def zero: Buff = Buff(0L,0L)
//todo 4.根据输入的数据更新缓冲区中的数据
override def reduce(buff: Buff, in: Long): Buff = {
buff.total = buff.total + in
buff.count = buff.count + 1
buff
}
//todo 5.合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//todo 6.计算结果
override def finish(buff: Buff): Long = {
buff.total/buff.count
}
//todo 7.分布式计算 需要将数据进行网络中传输,所以涉及缓冲区序列化和编码问题
//缓冲区的编码操作 自定义类就用这个Encoders.product
override def bufferEncoder: Encoder[Buff] = Encoders.product
//输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}















 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









