







模型选择
1、训练误差和泛化误差
训练误差:指模型在训练数据集上表现出的误差。
泛化误差:指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
机器学习模型应关注降低泛化误差。
2、模型选择
验证数据集
预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
K折交叉验证
在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
过拟合和欠拟合
欠拟合:模型无法得到较低的训练误差
过拟合:模型的训练误差远小于它在测试数据集上的误差
解决方案
考虑模型复杂度和训练数据集大小。
模型复杂度
我们以多项式函数拟合为例。给定一个由标量数据特征 x和对应的标量标签 y组成的训练数据集,多项式函数拟合的目标是找一个 𝐾阶多项式函数
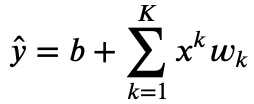
来近似 𝑦。在上式中, 𝑤𝑘是模型的权重参数, 𝑏是偏差参数。与线性回归相同,多项式函数拟合也使用平方损失函数。特别地,一阶多项式函数拟合又叫线性函数拟合。
给定训练数据集,模型复杂度和误差之间的关系:

训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
梯度消失、梯度爆炸
深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。


循环网络进阶
RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)
⻔控循环神经⽹络:捕捉时间序列中时间步距离较⼤的依赖关系
RNN:

GRU:

• 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
• 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









