






一头黄色的小象(大数据系列)~~

Hadoop是大数据涵盖的一个生态体系,主要分为:HDFS(文件存储系统,就是存数据),MapReduce(分布式计算引擎,其实应该拆开来的Map和Reduce,下边会具体介绍),Yarn(资源调度矿建)。
在介绍之前先来简单的了解下“结构化数据”和“半结构化数据”和“非结构化数据”是什么?
结构化数据

暂时理解为结构化数据一般会存放在关系型数据库中的数据,如Mysql等。
非结构化数据
对比着来看什么是非结构化数据

非结构化数据并不像结构化数据那么有条理,有固定的类型。
半结构化数据
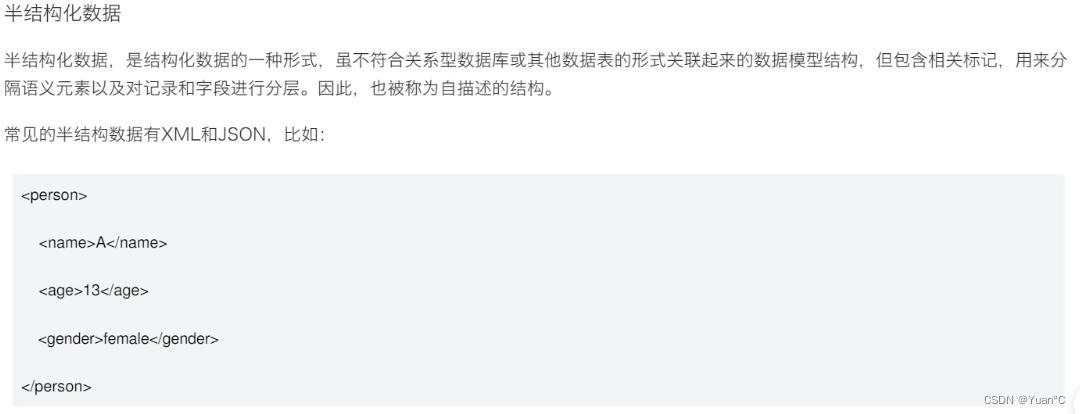
常见的XML格式和JSON格式就是半结构化数据的一种模型。
现在社会的发展越来越快,数据量也急剧上升,现在的数据,多半都是很多无规则的数据,并没有什么特定的格式或者类型,即非结构化数据,至于说把这些数据存放到哪里,那就需要按场景来去处理。
有问题就会有答案,那么HDFS也就应运而生了。
HDFS四个字去理解:分而治之。即把海量的数据,分到几台服务器上去存储,比如说,有一个文件,这个文件很大,把它切分成N块,让他遍布于每台服务器上,如果一台机器挂掉后,第三台挂了,还可以从其他节点上取回来,从第四台上取block4,第五台取block3,保证了高可用性。
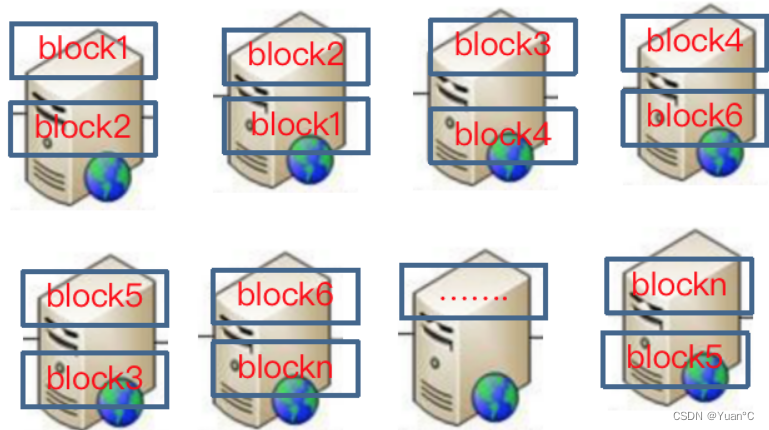
HDFS的两个特点:
1.数据分开的存储在其他服务器上。
2.数据块都是以多副本的形式存放到多台服务器上。
因为HDFS是采取分块的形式存储,并不像传统数据库表的形式存储,所以HDFS都适合以上三种数据类型:即结构化数据,非结构化数据,半结构化数据。
MapReduce
官网给出的是MapReduce是基于Yarn的用于为大数据集进行并行计算的系统,也可以说是引擎。
所以可以从官网看出MapReduce有以下特点:
1.是用于计算的。
这里的计算,通常指的是用来处理大数据集的,也就是统计类的。和以往的那些加减乘除不太一样。
2.并行计算。
上边说到,既然大数据是分布在多台机器上来存储的。那么要处理这些分布式的数据,就需要多台机器去协同处理,去统计这堆数据,也就是我们大家一起统计,简称“协同办公”。
3.基于Yarn。
Yarn是一个“资源调度者”,就是说他在其中是专门给分配任务的,专门给上边这些“协同办公”的服务器合理的去分配工作量,哪台能干就多干一点,不能干就少干一点。
理论归理论,上边的理论先混个眼熟,具体一实践自然也就明白了~
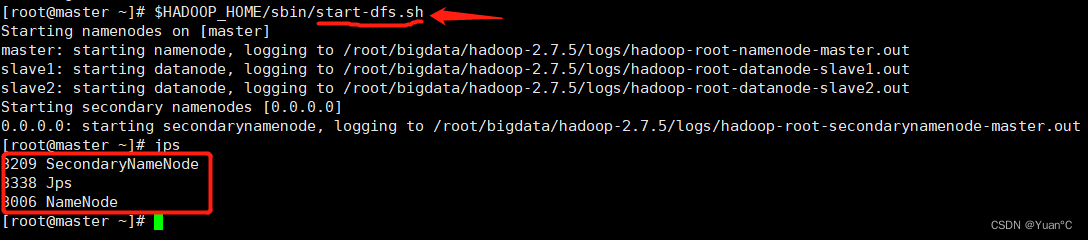
下边先看下Hadoop集群起来的一些进程!具体集群怎么搭建,去看其他作者的教程,这里给出网址:HDFS搭建教程
我这里是一主两从模式:开启主节点的HDFS,并查看进程
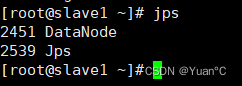
从节点slave1:
从节点slave2:
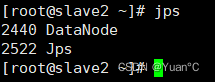
有一个对应关系:
datanode分别为从节点的信息,可以理解我的数据现在放在了slave1和slave2两台服务器上,而主节点master存放的信息就叫namenode,这个namenode没什么不同,就是换个名字。
namenode是负责管理文件系统的命名空间,维护系统的文件树以及所有的文件和和目录的元数据。


然后也就可以从Web端访问Hadoop端口:主节点ip:50070

完结,撒花~















 9817
9817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









