






大数据之Hbase
在上篇主要分析了Hadoop的有关概念,详见大数据系列
这节主要来看下Hbase数据库。
先来看官网给出的概念:
HBase(Hadoop Database):Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
主要由以下几点:
1.the Hadoop database:HBase是基于Hadoop的数据库,所以跟Hadoop是有强依赖关系的,而实际上,我们的HBase底层是要依赖于HDFS的,我们HBase上的数据,其实就是存放在HDFS上。
2.a distributed:是一个分布式的,HBase结构也是主从结构,类似于HDFS的主从结构,主从结构有利于对表、对数据进行处理。
3.scalable:可扩展的,自然而然,HBase的数据存储在HDFS上,HDFS可以部署在廉价的机器上,而且理论上可以无限扩展。所以,HBase其实是具有这个特点的。
4.big data store:大数据量的存储,说明HBase可以存储很大的数据量,一张表可以达到数百万列,数十亿行,而传统数据库,在达到上百万行的时候,就要考虑进行读写分离、分库分表等操作。
Hbase产生的背景
假如,要开发一个网站,开发完成后要将这个项目打包到服务器上去执行,而在网站运行之前,应该先在服务器上装好数据库如:MySQL、Redis、Oracle等等。
我们的网站程序里面,我们的数据是以表的形式来存储和读取的,而这些表,就是我们数据类型里面的结构化数据。如果没有数据库,其实网站程序相关的数据也是可以存放在服务器系统上的,只是,会发现特别麻烦,如果直接存到Linux,你可以通过简单的Select语句检索出你想要的数据吗?你能简单地用一句Update就修改里面相关条件的内容吗?你能够通过简单的聚合函数就做一些简单的分析吗?明显是不太容易操作的,当然也还有很多原因,只是简单地列举一下。
现在回到我们的大数据相关知识。到目前为止,我们已经学过了HDFS,是一个分布式文件系统,我们的数据可以存放到我们的HDFS上。但是,如果我们要对数据进行一些快速查询、聚合分析等操作的时候,也一样是非常困难的,这点跟我们上面分析的场景相类似。
HDFS与Hbase场景分析
1.HDFS不适合大量小文件的存储。因为它存储的元数据是在Namenode所在的机器内存中的,HDFS中的每个文件、目录、数据块占用150个字节左右,
如果存放1百万的文件则至少需要消耗300MB内存,当然如果是几十个亿,例如10亿,这个时候的内存就显得非常局限了,当然,这也是相对的,如果是几万个小文件,那当然就没有问题。
2.适合用于高吞吐量的访问,而不适合低延迟访问,它做不到低延迟访问,操作时不是简单地在本地就可以实现,是需要联系多台服务器的,索引等等也是一个限制。所以,**为了提高HDFS的性能,这里边就有了一个原则:尽可能地去移动计算而不是移动数据。**在吞吐量很大的时候,计算就相对更小,此时当然是移动计算程序去其他节点会更节省资源。
3.适合流式数据访问,一个文件只能被一个用户写,不支持随机写入,只能在文件末尾append进去,或者直接覆盖掉。此外,用户最好就是在访问的时候,尽量减少断开连接、建立连接的操作,因为此操作也是需要消耗性能的,最好就是做到一次建立了连接,一直访问、操作就好。流式数据访问,可以理解为就是一直都在访问,即一直都连接。
4.适合用于一次写入,多次读取,而且不适应用于低时间的访问。在进行写文件的时候需要涉及到多台服务器,那就存放RPC、数据传输等操作,非常消耗性能,所以最好就是存好在HDFS了就最好不要乱动了。而且有一点,HDFS的读取是按顺序读取的,不利于检索。
Hbase场景分析
1、有利于处理各种类型的数据,如结构化数据、半结构化或者非半结构数据。
2、HBase是以稀疏的结构存储数据的,数据是按列进行存储的,如果某一行的这一列没有数据,则不占用空间。
3、HBase支持多版本存储,默认是只存储一个版本,但是可以设置存多个版本,这个版本的索引是时间戳。
4、HBase支持随机读写,而HDFS只支持追加或者覆盖。
到目前为止,简单总结一下HBase的产生背景,HDFS与HBase都是用来存储数据的,而HBase的出现,主要也是为了做一些HDFS做不到的。
Hbase的存储结构
先来看一下百度百科里面的一句话:
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。
——来自百度百科
高可靠性、高性能、可伸缩我们此处不做叙述,主要开一下面向列这一特性。传统的数据库,比如说MySQL、Oracle,这些数据库都是按行存储的,而这里的HBase,是按列进行存储的。
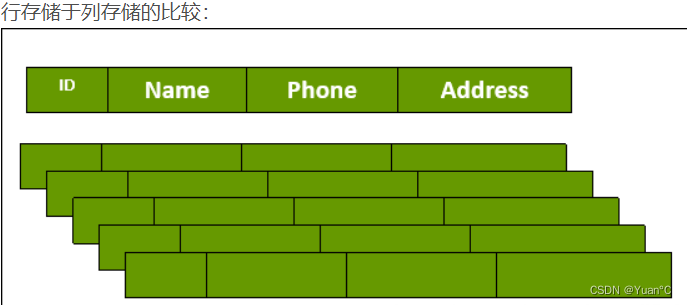
行存储是数据按行的方式存储在底层文件中,通常,每一行会自动的分配一个固定的空间。假如在上图:数据库里没有存储我的Phone和Address,只存储了我的ID和Name,那么没存的这两个字段Phone和Address也在占用空间。如果是Hbase的话,对于没有的信息,他是可以为空的,并且不占用空间。
优点是:利于增加,修改,整行记录等操作,也有利于整行数据的读取。
缺点是:单列查询时,会读取一些不必要的数据,例如:查找出数据库里面所有人的名字,则需要将所有数据都读取出来,然后将名字这一列检索出来。
再来看列存储:
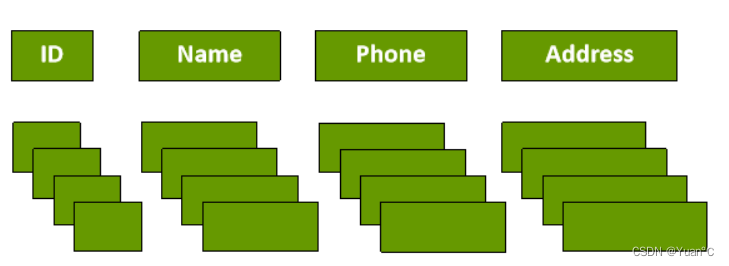
数据以列为单位,列是按照文件夹这样的方式存储的,所以此时如果要在读取Name这一列,就可以直接读取Name之一列就行,无关的数据不用读就行了。如果Address某一个人的信息不知道,就可以把它为空,并且也不占用空间。
列存储的优缺点:
优点:有利于面向单列数据的读取、统计等操作。
缺点:整行读取时,可能需要多次I/O操作。
Hbase表的结构
HBase 逻辑结构

HBase 物理结构

数据模型:
-
Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase 有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。 -
Region
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。 -
Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。 -
Column
HBase 中的每个列都由 Column Family (列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。 -
Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。 -
Cell
由{rowkey, column Family:column Qualifier, time Stamp}唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存储。
开始演示:
需要注意,开启Hbase需要提前搭建好Hadoop环境和Zookeeper集群(因为Hbase是利用zookeeper来管理的,后续会具体介绍)。关于Hbase集群,Hadoop的搭建以及Zookeeper的环境具体请看:
Hbase搭建
Hadoop搭建
Zookeeper搭建
如图,确保三个节点集群服务都能正常启动:
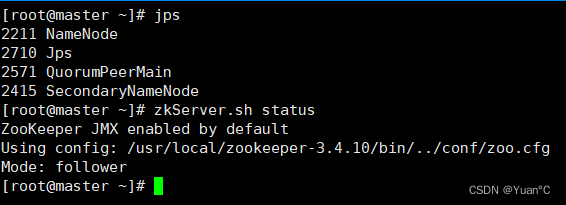
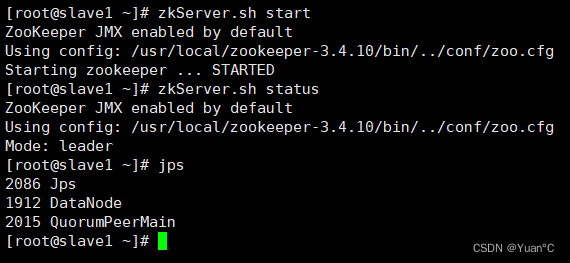
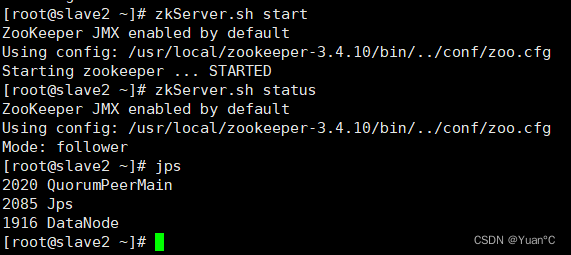
3台服务都要分别去启动zookeeper,可以看出zookeeper有一个功能,master节点的zookeeper的Mode为:follower;slave1节点的zookeeper的Mode为:leader;slave2节点的zookeeper的Mode为:follower;这是zookeeper的选举机制,选举有特定的算法。
然后在master节点开启Hbase集群:
start-hbase.sh
hbase shell

list命令就理解为Mysql中的show databases;
在这里意为:查看所有的表
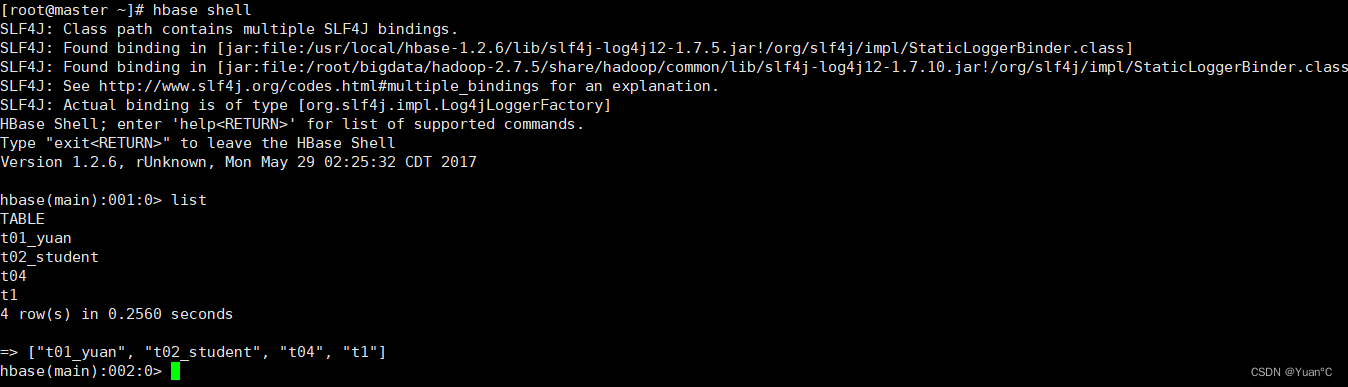
常用的一些命令:
list :查看所有的表
create ‘表名’,‘列族名’ :建表
put ‘表名’,‘Rowkey’,‘列族名:列名’,‘值’ :添加数据,修改数据(Hbase中修改的语法就是直接put他会覆盖上一条数据)
deleteadd ‘表名’,‘Rowkey’:删除一行数据
scan ‘表名’:扫描表的数据
get ‘表名’,‘Rowkey’:查看相关的Rowkey的数据
desc ‘表名’:查看建表的详细结构
当然命令不止这些,后续还有一些过滤的命令,会慢慢介绍~~
hbase(main):002:0> create 't2','bi'
0 row(s) in 2.5620 seconds
=> Hbase::Table - t2
hbase(main):003:0> list
TABLE
t01_yuan
t02_student
t04
t1
t2
5 row(s) in 0.0340 seconds
=> ["t01_yuan", "t02_student", "t04", "t1", "t2"]
hbase(main):004:0> put 't2','1001','bi:a0','yhh'
0 row(s) in 0.2120 seconds
hbase(main):005:0> put 't2','1002','bi:a1','24'
0 row(s) in 0.0130 seconds
hbase(main):006:0> put 't2','1003','bi:a2','male'
0 row(s) in 0.0150 seconds
hbase(main):007:0> scan 't2'
ROW COLUMN+CELL
1001 column=bi:a0, timestamp=1671084250140, value=yhh
1002 column=bi:a1, timestamp=1671084265430, value=24
1003 column=bi:a2, timestamp=1671084274616, value=male
3 row(s) in 0.0460 seconds
hbase(main):008:0> desc 't2'
Table t2 is ENABLED
t2
COLUMN FAMILIES DESCRIPTION
{NAME => 'bi', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_
VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.0630 seconds
hbase(main):009:0> put 't2','1001','bi:a1','wu2'
0 row(s) in 0.0150 seconds
hbase(main):010:0> put 't2','1001','bi:a2','130123'
0 row(s) in 0.0120 seconds
hbase(main):011:0> get 't2','1001'
COLUMN CELL
bi:a0 timestamp=1671084250140, value=yhh
bi:a1 timestamp=1671084458981, value=wu2
bi:a2 timestamp=1671084466096, value=130123
3 row(s) in 0.0310 seconds
提示:在添加数据的时候,也就是put时,列族后边的列名是动态指定的,也就是说在建表时,只需声明出列族就行。
例如上图中的a1,a2…
Rowkey的设计
长度原则,唯一原则,排序原则,散列原则
如图:

当用Hbase插入数据的时候,顺序他会自己根据指定的算法去排序。
而这个时候来看Mysql,他根本不会给你排序,就直接候补:
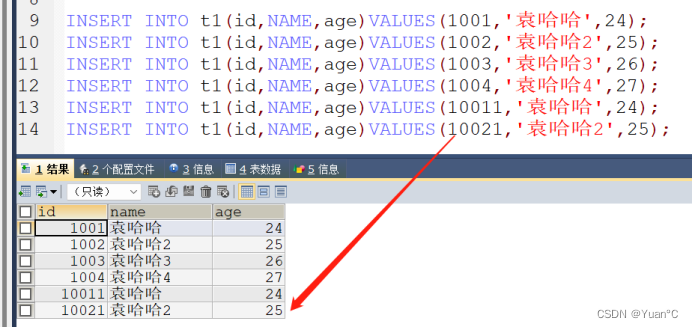
Rowkey的设计关键是非常有必要的。比如现在有这么一个案例:
第1个模板:证件更新。
第2个模板:新卡提醒。
就拿以上两个模板来说,怎样去合理的设计Rowkey呢,当然这得需要根据具体的业务场景来定。
比如,当我想查第1个模板的时候,我就得想,他叫证件更新,那么我得需要拿到证件号然后在拼接上模板的名字:Rowkey=证件号+模板名字,就是:1301231。
当我想查第2个模板的时候,我就得想,他叫新卡提醒,那么我得需要拿到证件号然后在拿上它的卡号最后在拼接上模板的名字:Rowkey=证件号+卡号+模板名字,就是:1301232432。
hbase(main):017:0> scan 't2'
ROW COLUMN+CELL
1001 column=bi:a0, timestamp=1671084250140, value=yhh
1001 column=bi:a1, timestamp=1671084458981, value=wu2
1001 column=bi:a2, timestamp=1671084466096, value=130123
1002 column=bi:a1, timestamp=1671084265430, value=24
1003 column=bi:a2, timestamp=1671084274616, value=male
1301231 column=bi:a0, timestamp=1671085427440, value=yuan
1301232 column=bi:a1, timestamp=1671085471158, value=yuan12
1301232432 column=bi:a0, timestamp=1671085446523, value=sdsd
6 row(s) in 0.0330 seconds
这样我把上图中的1301231和1301232432都存到了数据库中。为了区别下,我又添加了一条1301232,他自己追加到了1301231后边,并没有在1301232432下边。
这就符合了它的排序原则。
由于时间问题,本篇介绍的会有点仓促,不足之处,敬请指出,下期会继续介绍~~~















 6371
6371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









