




此处附上一个实践代码,来源:b站刘二大人第十三讲。
'''
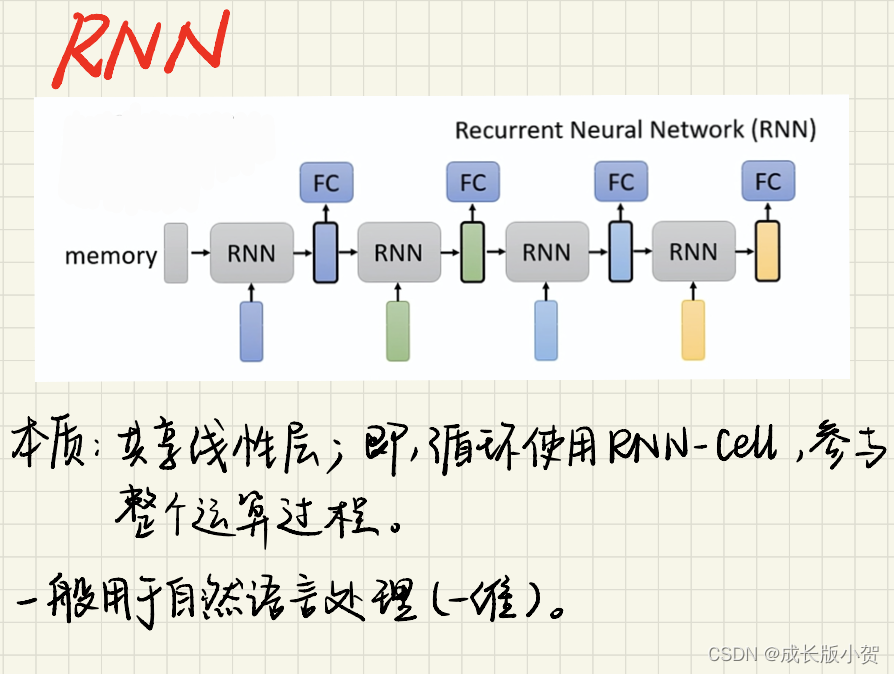
处理自然语言:
字/词 --> one-hot向量(太过稀疏松散)--> 通过EmbeddingLayer嵌入层转为低维稠密的向量 --> RNN --> 通过LinearLayer线性层转化成想要的输出维度
'''
'''
e.g. 给出国家名称,判断使用哪个语言。
结构: Embedding Layer - GPU Layer - Linear Layer
'''
'''
1.处理国家名字name:
序列 --> 列表;
做词典;
列表 -(根据词典)-> 数值列表(这里面的数字代表一个 one-hot vector);
因为数值列表长短不一、无法构成矩阵、不能构成张量,所以做一个padding(根据最长序列填充)。
2.处理语言名字country --> 索引标签(用作分类的label)
做词典。
'''
import torch
import time
import math
import csv
import gzip
from torch.utils.data import DataLoader
import datetime
import matplotlib.pyplot as plt
import numpy as np
HIDDEN_SIZE=100
BATCH_SIZE=256
N_LAYER=2
N_EPOCHS=200
N_CHARS=128
USE_GPU=False
class NameDataset():
def __init__(self,is_train_set=True):
filename = 'names_train.csv.gz' if is_train_set else 'names_test.csv.gz' # 因为数据集小,一次性全部读入。
with gzip.open(filename, 'rt') as f: # 打开压缩文件并将变量名设为为f
reader = csv.reader(f) # 读取表格文件
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries))) # set:list --> 集合,可以去重复;sorted:排序。
self.country_dict = self.getCountryDict() # 转变成词典。
self.country_num = len(self.country_list)
def __getitem__(self,index):
return self.names[in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3371
3371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









