







Hadoop:MapReduce进阶编程(WritableComparable和cleanup的使用)
一、案例要求
实验内容 1,自定义类型
1)已知数据格式如下(用户名\t 收入\t 支出\t 日期);PS:实际是按空格,如下面的数据
zhangsan 6000 0 2016-05-01
lisi 2000 0 2016-05-01
lisi 0 100 2016-05-01
zhangsan 3000 0 2016-05-01
wangwu 9000 0 2016-05-01
wangwu 0 200 2016-05-01
zhangsan 200 400 2016-05-01
2)要求,计算每个用户的收入、支出及利润情况,并优
先显示利润最大的用户(按利润降序、如果利润相同则按收
入降序),如:
zhangsan 9200 400 8800
wangwu 9000 200 8800
lisi 2000 100 1900
3)实验说明
(1)Hadoop WritableComparable 接口
Writable 接口是一个实现了序列化协议的序列化对象。在 Hadoop 中定义一个结构化对象都要实现 Writable 接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。那 WritableComparable 接口是可序列化并且可比较的接口。 MapReduce 中所有的 key 值类型都必须实现这个接口,既然是可序列化的那就必须得实现readFields()和 write()这两个序列化和反序列化函数;既然是可比较的就必须实现 compareTo()函数,该函数即是比较和排序规则的实现。这样 MR 中的 key 值就既能可序列化又是可比较的。
(2)计划设计 MR 的步骤
A,自定义类 TradeBean(每一笔交易记录),并实现 write、readFields、compareTo、toString 方法以及各成员的 get、set 方法;
B, 读取步骤(Map 阶段),取出用户的每一笔收入和支出情况,输出阶段以用户名为 key,value 为 TradeBean 类型;
C, 求和步骤(Reduce 阶段),并统计每个用户的多笔收入支出记录,输出(TradeBean,NullWritable)即可。此时的 TradeBean 表示某用户的汇总统计结果。
实验内容 2,Top N 求解
已知文件数据如下,每行只有一个整数数据。
例如,mfile1 文件:
4
56
7
89
1234
56
789
666
1500
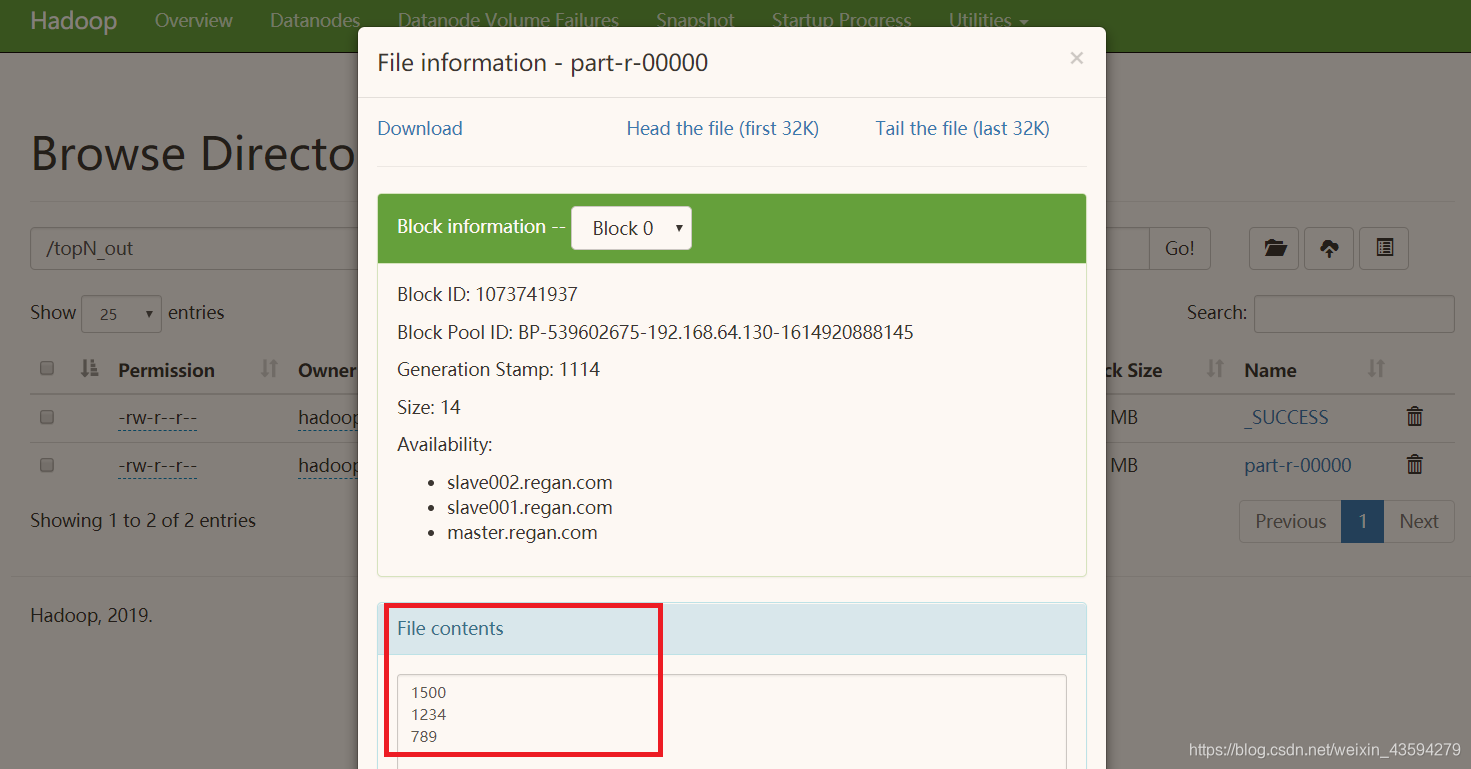
求所有这些文件中数值的最大三个值( Top 3 ),并按降序输出;
解题思路: 为避免所有数据都集中到 Reduce 阶段进行排序求最大三个值,要求在 Mapper 之后的 Combiner 阶段,对当前数据块的数值,预先获取“小数据集” 的三个最大值,然后再交给 Reducer 阶段求“所有数据集”的三个最大值。即需要编写 Mapper 类、Combiner 类、Reducer 类;
实验简析
其实这两个子实验是属于同一性质的实验,都需要用到重写cleanup函数,cleanup函数会在当前上下文管理结束的时候被调用一次,而且在整个程序运行也只会最多被调用一次。对于第一个实验,读者会发现依照题目要求继承WritableComparable 接口编写TradeBean最后还是没法实现降序排列,那是因为MapReduce默认只对Key排序,而我们将Bean放到了Value中,故只能我们手动添加排序,详情请见下文代码。
二、实现过程
1.IntelliJ IDEA 创建Maven工程
项目层次结构如图:
2.完整代码
首先配置pom文件,跟前一个案例一样,读者可查看Hadoop:MapReduce之倒排索引(Combiner和Partitioner的使用)并复制
然后接下来将挨个实验介绍!
子实验1
TradeBean.java
package subExp1;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class TradeBean implements WritableComparable<TradeBean>{
private String username;
private int income;
private int outcome;
private int profit;
public TradeBean(){}
//Getter & Setter
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public int getIncome() {
return income;
}
public int getOutcome() {
return outcome;
}
public int getProfit() {
return profit;
}
public void setIncome(int income) {
this.income = income;
}
public void setOutcome(int outcome) {
this.outcome = outcome;
}
public void setProfit(int profit) {
this.profit = profit;
}
@Override
public String toString() {
//重写toString方法,这是必要的,因为这直接决定TradeBean输出到最终文件的结果
return username + "\t" +
"\t" + income +
"\t" + outcome +
"\t" + profit;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
//顺序跟定义字段时的顺序保持一致以便序列化
dataOutput.writeUTF(username);
dataOutput.writeInt(income);
dataOutput.writeInt(outcome);
dataOutput.writeInt(profit);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
//顺序跟定义的顺序保持一致以便反序列化
this.username=dataInput.readUTF();
this.income=dataInput.readInt();
this.outcome=dataInput.readInt();
this.profit=dataInput.readInt();
}
@Override
public int compareTo(TradeBean bean) {
/**
重写比较方法,可以是>0 return 1,<0 return -1这种形式也可以是下面这种,
直接拿比较对象和本对象属性进行相减的比较。
默认是升序,比较的本质原则就是将正数或者说较大的数放到较小数之后,所以this-bean>0则this会放到bean后面。
我们需要的是降序所以需要bean-this
*/
int result = bean.profit-this.profit; //按利润降序
if(result==0) //利润相等则按收入降序
return bean.income-this.income;
return result;
}
}
TradeMapper.java
package subExp1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TradeMapper extends Mapper<LongWritable, Text,Text,TradeBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
TradeBean bean = new TradeBean();
//只提取收入和支出,忽略掉时间
int income = Integer.parseInt(words[1]);
int outcome = Integer.parseInt(words[2]);
bean.setUsername(words[0]);
bean.setIncome(income);
bean.setOutcome(outcome);
bean.setProfit(income-outcome);
context.write(new Text(words[0]),bean);
}
}
TradeReducer.java
package subExp1;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.TreeMap;
public class TradeReducer extends Reducer<Text, TradeBean,TradeBean, NullWritable> {
TreeMap<TradeBean,String> treeMap = new TreeMap<>(); //使用TreeMap自动排序的特性,其他数据结构均可
@Override
protected void reduce(Text key, Iterable<TradeBean> values, Context context) throws IOException, InterruptedException {
int income = 0;
int outcome = 0;
int profit = 0;
//整合同用户的收入和支出
for (TradeBean bean : values) {
income+=bean.getIncome();
outcome+=bean.getOutcome();
profit+=bean.getProfit();
}
TradeBean tradeBean = new TradeBean();
tradeBean.setUsername(key.toString());
tradeBean.setIncome(income);
tradeBean.setOutcome(outcome);
tradeBean.setProfit(profit);
treeMap.put(tradeBean,""); //由于只对tradeBean排序,所以treeMap的value值无所谓,所以填了""
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//foreach 将排好序的tradeBean写入上下文
for (TradeBean bean:treeMap.keySet()){
context.write(bean,NullWritable.get());
}
}
}
TradeJobMain.java
package subExp1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TradeJobMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TradeJobMain.class);
job.setMapperClass(TradeMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TradeBean.class);
job.setReducerClass(TradeReducer.class);
job.setOutputKeyClass(TradeBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//如果本地安装了Hadoop,可以本机运行,无需到虚拟机集群上验证
// FileInputFormat.setInputPaths(job,new Path("file:///D:\\mapreduce\\input"));
// FileOutputFormat.setOutputPath(job,new Path("file:///D:\\mapreduce\\trade"));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
子实验2
TopMapper.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeSet;
public class TopMapper extends Mapper<LongWritable, Text,IntWritable, IntWritable> {
TreeSet<Integer> set= new TreeSet<>(); //使用TreeSet进行排序
IntWritable outKey = new IntWritable();
IntWritable one = new IntWritable(1); //这步是必要的,否则会报错
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
int num = Integer.parseInt(value.toString().trim());
set.add(-num); //负数细节,由于TreeSet是默认升序,所以将数值变相反数以达到降序目的
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
//这里完全可以用set 遍历前3条数据
set.stream().limit(3).forEach( (num)->{ //流的形式读取前3个到写入上下文中
outKey.set(num);
try {
context.write(outKey,one);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
});
}
}
TopCombiner.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TopCombiner extends Reducer<IntWritable, IntWritable,IntWritable,IntWritable> {
int count = 0;
IntWritable outKey = new IntWritable();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
if (count <= 3) { //都只写入前三的数字
outKey.set(-key.get()); //这里要将数值的正负号反转,以便在Reducer阶段写入和原数值相同
context.write(outKey,values.iterator().next());
count++;
}
}
}
TopReducer.java
package subExp2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TopReducer extends Reducer<IntWritable, IntWritable,IntWritable, NullWritable> {
//和TopCombiner的代码几乎一致,逻辑上是相同的
int count = 0;
IntWritable outKey = new IntWritable();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
if (count <= 3) {
outKey.set(key.get());
context.write(outKey, NullWritable.get());
count++;
}
}
}
TopJobMain.java
package subExp2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class TopJobMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TopJobMain.class);
job.setMapperClass(TopMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setCombinerClass(TopCombiner.class);
job.setReducerClass(TopReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
3.Maven打包
略,如有需要请前往Hadoop:MapReduce之倒排索引(Combiner和Partitioner的使用)查看
4.Hadoop集群运行
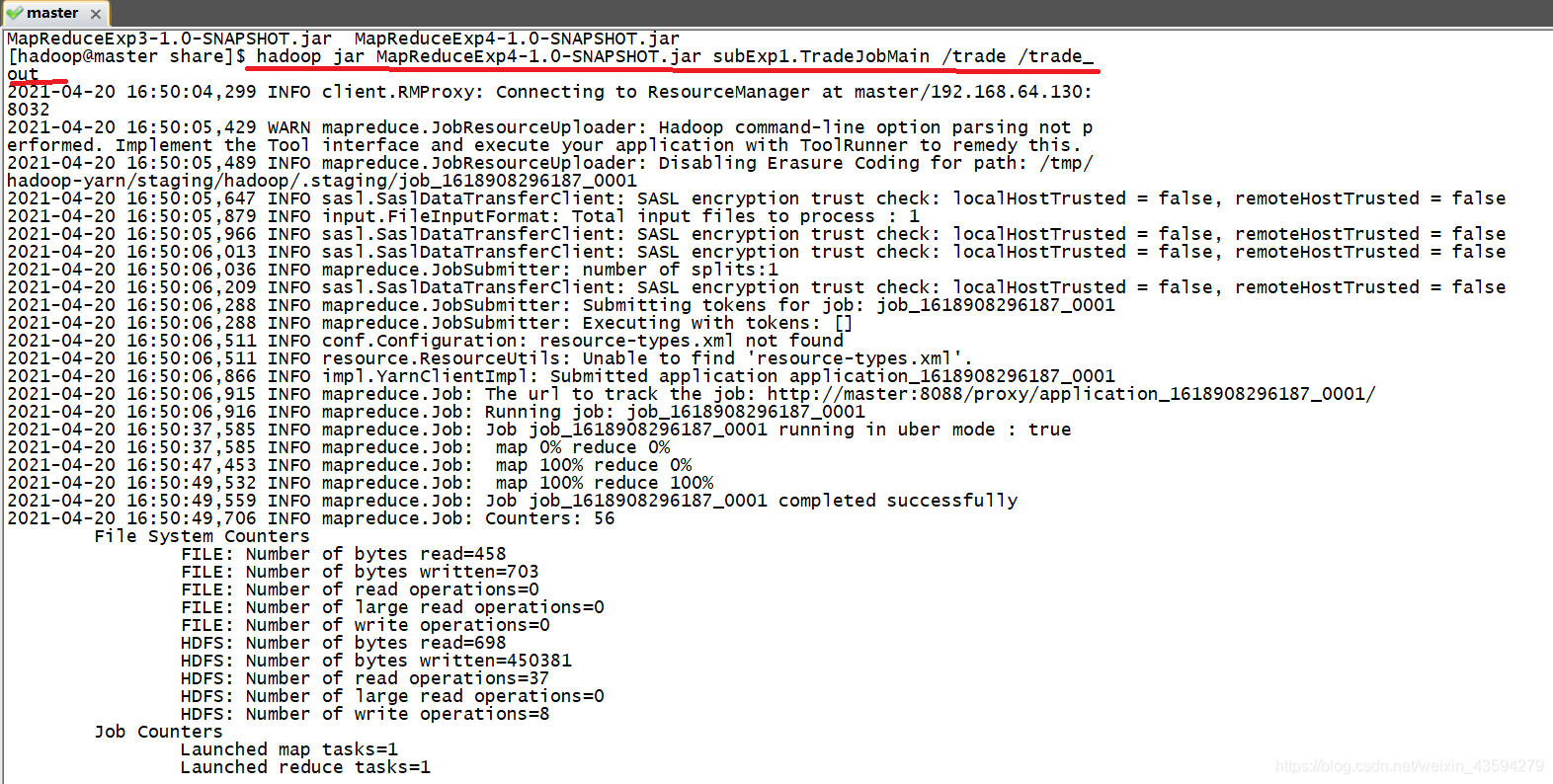
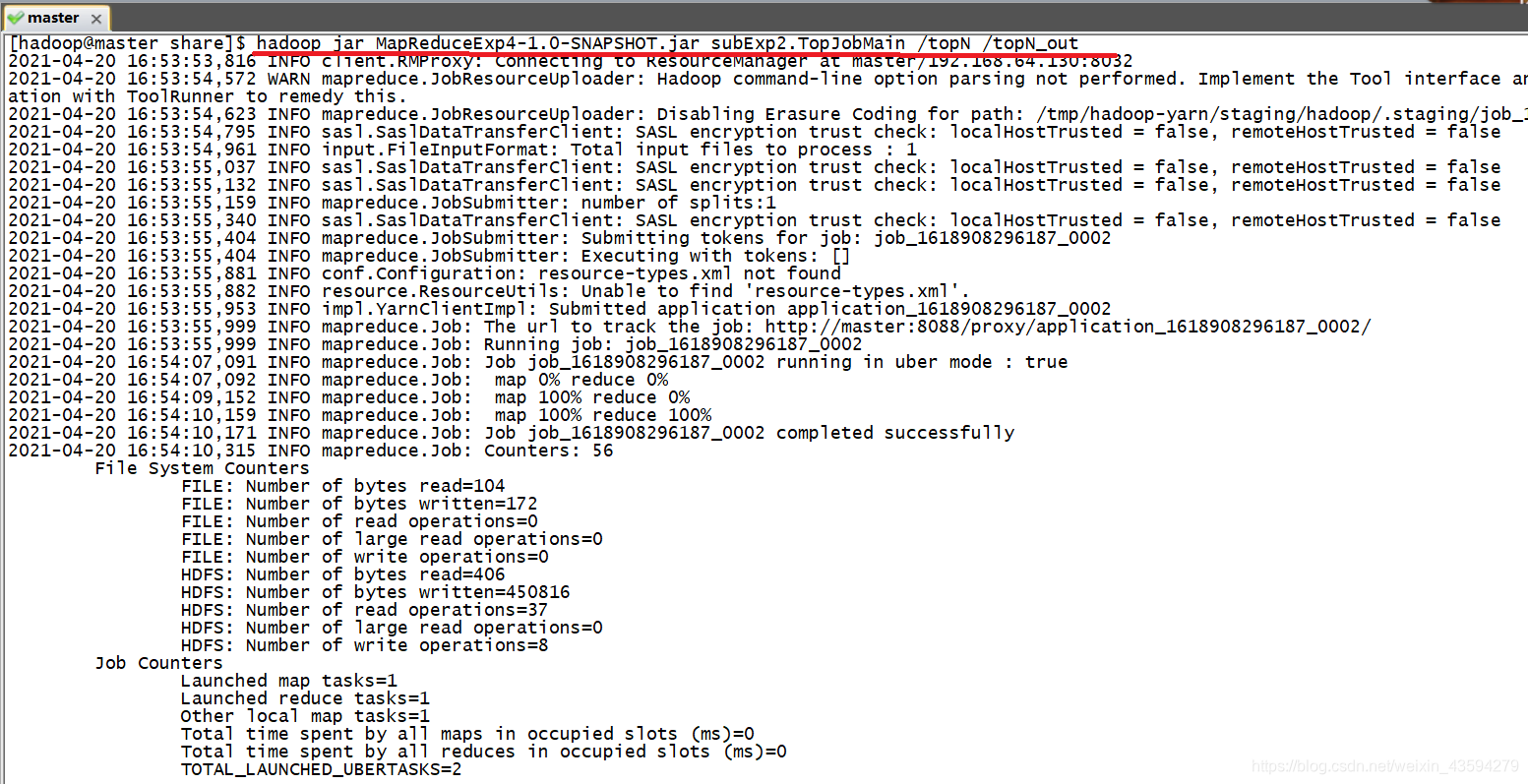
结果可以在浏览器点击上方的Head the file查看
参考网站及视频
[1] MapReduce使用cleanup()方法实现排序筛选后输出
[2] 100w条数据(数字) 每一行一个 求 这个文件中最大的3个数 设计mapreduce的实现方案 效率高一些
[3] MapReduce之二——收入支出数据处理与自定义排序
[4] 小破站视频:MapReduce自定义排序














 5199
5199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









