






1. XGBoost简介
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其它许多机器学习竞赛中并取得不错的成绩。
2. XGBoost与GBDT的区别与联系
原始的GBDT算法基于经验损失函数的负梯度来构造新的决策树,在决策树构建完成后再进行剪枝。而XGBoost在决策树构建阶段就加入正则项,损失函数为:
L
t
=
∑
i
N
l
(
y
i
,
F
t
−
1
(
x
i
)
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
L_t=\sum_{i}^{N} l\left (y_i,F_{t-1}(x_i)+f_t(x_i) \right ) +\Omega (f_t)
Lt=i∑Nl(yi,Ft−1(xi)+ft(xi))+Ω(ft)
其中,
F
t
−
1
(
x
i
)
F_{t-1}(x_i)
Ft−1(xi) 表示现有
t
−
1
t-1
t−1 棵树最优价。关于树结构的正则项定义为:
Ω
(
f
t
)
=
γ
T
+
1
2
λ
∑
j
=
1
T
w
j
2
\Omega(f_t)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_j^2
Ω(ft)=γT+21λj=1∑Twj2
其中
T
T
T 为叶子节点个数,
w
j
w_j
wj 表示第
j
j
j 个叶子节点的预测值。对该损失函数在
F
t
−
1
F_{t-1}
Ft−1 处进行二阶泰勒展开可以推导出:
L
t
≈
L
~
t
=
∑
j
=
1
T
[
G
i
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
L_t\approx \tilde{L} _t=\sum_{j=1}^{T} \left [G_iw_j+ \frac{1}{2} (H_j+\lambda)w_j^2 \right ]+\gamma T
Lt≈L~t=j=1∑T[Giwj+21(Hj+λ)wj2]+γT
其中,
T
T
T 为决策树
f
t
f_t
ft 中叶子节点的个数,
G
j
=
∑
i
∈
I
j
∇
F
t
−
1
l
(
y
i
,
F
t
−
1
(
x
i
)
)
G_j=\sum_{i\in I_j }^{} \nabla_{F_{t-1}}l\left (y_i,F_{t-1}(x_i) \right )
Gj=i∈Ij∑∇Ft−1l(yi,Ft−1(xi))
H
j
=
∑
i
∈
I
j
∇
F
t
−
1
2
l
(
y
i
,
F
t
−
1
(
x
i
)
)
H_j=\sum_{i\in I_j }^{} \nabla_{F_{t-1}}^2l\left (y_i,F_{t-1}(x_i) \right )
Hj=i∈Ij∑∇Ft−12l(yi,Ft−1(xi))
I
j
I_j
Ij 表示所有属于叶子节点
j
j
j 的样本的索引的结合。
假设决策树的结构已知,令损失函数相对于
w
j
w_j
wj 的导数为0,可以求出在最小化损失函数情况下各个叶子节点上的预测值:
w
j
∗
=
−
G
j
H
j
+
λ
w_j^*=-\frac{G_j}{H_j+\lambda }
wj∗=−Hj+λGj
通过将预测值代入到损失函数中可求得损失函数的最小值:
L
~
t
∗
=
−
1
2
∑
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
\tilde{L}_t^*=-\frac{1}{2} \sum_{j=1}^{T} \frac{G_j^2}{H_j+\lambda } +\gamma T
L~t∗=−21j=1∑THj+λGj2+γT
可以计算出分裂前后损失函数的差值为:
G
a
i
n
=
G
L
2
H
L
+
λ
+
G
R
2
H
R
+
λ
−
(
G
L
+
G
R
)
2
H
L
+
H
R
+
λ
−
γ
Gain=\frac{G_L^2}{H_L+\lambda } +\frac{G_R^2}{H_R+\lambda }-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda }-\gamma
Gain=HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2−γ
XGBoost采用最大化分裂前后损失函数的差值的准则来进行决策树的构建,通过遍历所有特征的所有取值,寻找最佳的分裂方式。由于分列前后损失函数差值为正的限制,
γ
\gamma
γ 起到了预剪枝的效果。
XGBoost算法的主要优点:
(1)XGBoost显示地加入正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力;
(2)GBDT在模型训练时只使用代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。
3. XGBoost 的参数详解
在运行 XGBoost 之前,我们必须设置三种类型的参数: 常规参数、提升器参数和任务参数。
常规参数涉及使用哪种基模型,包括树模型或线性模型。
提升器参数取决于选择了哪种模型作为基模型。
学习任务参数取决于学习场景。
命令行参数与 XGBoost 的 CLI 版本的行为相关。
一、全局配置
可以使用 xgb.config _ context ()(Python)或 xgb.set.config ()( R )在全局范围内设置以下参数:
- verbosity:打印消息的冗长性。有效值为0(静音)、1(警告)、2(信息)和3(调试)。
- user_rmm:是否使用 RAPIDS 内存管理器(RMM)来分配 GPU 内存。此选项仅在启用 RMM 插件构建(编译) XGBoost 时适用。有效值为 true 和 false。
二 、常规参数
- booster [default = gbtree]:使用哪种基模型。可以是 gbtree,gbllinear 或者 dart; gbtree 和 dart 使用基于树的模型,而 gbllinear 使用线性函数。
- verbosity [default = 1]:冗长的打印信息。有效值为0(静音) ,1(警告) ,2(信息) ,3(调试)。有时 XGBoost 尝试基于启发式方法更改配置,这会显示为警告消息。如果有意想不到的行为,请尽量增加冗长值。
- validate_parameters [default to false, except for Python, R and CLI interface]:当设置为 True 时,XGBoost 将执行输入参数的验证,以检查是否使用了参数。该功能仍处于试验阶段。预计会有一些假阳性。
- nthread [default to maximum number of threads available if not set]:用于运行 XGBoost 的并行线程的数量。在选择它时,请记住线程争用和超线程。
- disable_default_eval_metric [default=
false]:标志用于禁用默认指标。设置为1或 true 用于禁用。 - num_pbuffer [set automatically by XGBoost, no need to be set by user]:预测缓冲区的大小,通常设置为训练实例的数量。利用缓冲器保存最后一个提升步骤的预测结果。
- num_feature [set automatically by XGBoost, no need to be set by user]:特征维度用于提升,设置为特征的最大维度。
(1)基模型为树模型的参数
- eta [default=0.3, alias: learning_rate]:学习率用于更新,以防止过拟合。在每一个提升步骤之后,我们可以直接得到新特性的权重,eta 缩小特性的权重,使提升过程更加保守。取值范围:[0,1]。
- gamma [default=0, alias: min_split_loss]:在树的叶节点上进一步划分所需的最小损失减少。gamma 越大,算法就越保守。取值范围: [0,∞]。
- max_depth [default=6]:树的最大深度。增加这个值将使模型更加复杂,并且更有可能过拟合。0只有在树方法被设置为 hist 或 gpu hist 时才能被接受,并且它表示没有深度限制。注意,在训练深度树时,XGBoost 会大量消耗内存。取值范围: [0,∞]。
- min_child_weight [default=1]:一个子节点所需的最小实例权重总和。如果树分区步骤导致叶节点的实例权重之和小于 min _ child _ weight,那么构建过程将放弃进一步的分区。在线性回归任务中,这仅仅对应于每个节点所需的最小数量。最小子权值越大,算法就越保守。取值范围: [0,∞]。
- max_delta_step [default=0]:允许每片叶子输出的最大步长。如果该值设置为0,则意味着没有约束。如果将其设置为正值,则有助于使更新步骤更加保守。通常这个参数是不需要的,但是在类极度不平衡的情况下,这个参数可能会有所帮助,因为这个参数可以帮助我们改进逻辑回归。将其设置为1-10可能有助于控制更新。取值范围: [0,∞]。
- subsample [default=1]:训练实例的子样本比率。将其设置为0.5意味着 XGBoost 会在树木生长之前随机抽取一半的训练数据。这样就不会过拟合。每次增强迭代中都会发生一次子采样。取值范围:(0,1]。
- sampling_method [default= uniform]:对训练实例进行抽样的方法。uniform: 每个训练实例被选中的概率相等。通常设置subsample > = 0.5以获得好的结果。gradient_based: 每个训练实例的选择概率与梯度的正则化绝对值成正比。subsample可以设置为低至0.1,而不会损失模型的准确性。注意,只有当 tree _ method 设置为 gpu _ hist 时才支持这种抽样方法; 其他树方法只支持均匀抽样。
- colsample_bytree, colsample_bylevel, colsample_bynode [default=1]:这是一组用于对列进行次抽样的参数。所有 colsample _ by * 参数的范围为(0,1] ,默认值为1,并指定要子采样的列的比例。Colsample _ bytree 是构造每棵树时列的子采样比率。对于构造的每棵树,子采样只进行一次。Colsample _ bylevel 是每层的列的子采样比率。对于树中每达到一个新的深度水平,就会进行一次子采样。从为当前树选择的列集中对列进行子抽样。Colsample _ bynode 是每个节点的列的子抽样比率。每次计算新的分割时,都会发生一次子采样。从为当前层选择的列集中对列进行子抽样。colsample_by* 参数会累积产生效果。例如,组合{‘ colsample bytree’: 0.5,‘ colsample bylevel’: 0.5,‘ colsample bynode’: 0.5}和64个特性将在每个分割点留下8个可供选择的特性。在 Python 接口,当使用 hist、 gpu hist 或者精确树方法时,可以设置 DMatrix 的特征权重来定义列抽样时每个特征被选择的概率。
- lambda [default=1, alias: reg_lambda]:权值的L2正则化项。增加这个值会使模型更加保守。
- alpha [default=0, alias: reg_alpha]:权值的L1正则化项。增加这个值会使模型更加保守。
- tree_method string [default= auto]:XGBoost 中的树构造算法。XGBoost 支持 approx,hist 和 gpu hist 来进行分布式培训。对外部内存的实验支持可用于 approx 和 gpu hist。选择: auto,exact,approx,hist,gpu hist,这是常用的更新程序的组合。对于像 refresh 这样的其他更新器,可以直接设置参数 updater。auto:使用启发式选择最快的方法。对于小数据集,将使用精确的贪婪(精确)。对于较大的数据集,将选择近似算法(大约)。建议尝试 hist 和 gpu hist 以获得更高的大数据集性能。(gpu hist)支持外部内存。由于原有的行为在单机上总是使用精确贪婪策略,用户在选择近似算法时会得到一条消息通知这个选择。exact: 精确的贪婪算法。列举所有分裂的候选者。approx: 近似贪婪算法使用分位数草图和梯度直方图。hist:快速的直方图优化近似贪婪算法。gpu_hist: hist 算法的 GPU 实现。
- sketch_eps [default=0.03]:仅用于 tree _ method = approx。这大致可以转换为 O (1/sketch _ eps)的箱子数。与直接选择箱子的数量相比,这在理论上保证了草图的准确性。通常用户不需要对此进行调优。但是为了更准确地枚举分裂候选值,可以考虑设置较低的数字。取值范围: (0, 1)。
- scale_pos_weight [default=1]:控制正负权值的平衡,对不平衡的类别有用。需要考虑的典型值: sum (负实例)/sum (正实例)。
- updater [default= grow_colmaker,prune]:用逗号分隔的字符串定义要运行的树更新程序序列,提供了构造和修改树的模块化方法。这是一个高级参数,通常根据其他参数自动设置。但是,它也可以由用户显式地设置。存在以下更新方法。grow_colmaker:非分布式基于列的树结构。grow_histmaker:基于全局直方图计数方法的分布式行数据分割树构造。grow_local_histmaker:基于局部直方图计数。grow_quantile_histmaker:使用量化直方图生长树。grow_gpu_hist:使用 GPU 生长树。sync:同步所有分布式节点中的树。refresh:刷新树的统计数据和/或基于当前数据的叶值。注意,没有对数据行执行任意的子抽样。prune:去除损失 < min _ split _ loss (或 gamma)的分裂。在分布式设置中,隐式的更新序列值将被调整为 grow _ histmaker,默认情况下修剪,并且可以将 tree _ method 设置为 hist 以使用 grow _ histmaker。
- refresh_leaf [default=1]:这是刷新更新器的一个参数。当这个标志为1时,树叶和树节点的状态都会被更新。当它为0时,只更新节点状态。
- process_type [default= default]:提升过程的种类。选择:default, update。default:创建新树的正常增强过程。update:从现有的模型开始,只更新它的树。在每次升级迭代中,取出初始模型中的一棵树,为该树运行指定的更新程序序列,并向新模型添加修改后的树。根据执行的增强迭代次数的不同,新模型将拥有相同或更少的树。目前,下面的内置更新程序可以有意义地用于这种流程类型: 刷新、修改。对于 process _ type = update,不能通过创建新树更新。
- grow_policy [default= depthwise]:控制向树中添加新节点的方式。当前只支持将 tree _ method 设置为 hist 或 gpu _ hist。选择:depthwise, lossguide。depthwise:在最靠近根的节点处分裂。lossguide:在损失变化最大的节点处分裂。
- max_leaves [default=0]:要添加的最大节点数。只有在设置 grow _ policy = lossguide 时才相关。
- max_bin, [default=256]:仅当 tree _ method 设置为 hist 或 gpu _ hist 时才使用。连续特征的最大离散箱子数。增加这个数字可以以更高的计算时间为代价来提高分裂的最优性。
- predictor, [default=
auto]:auto:基于启发式方法配置预测器。cpu_predictor:多核 CPU 预测算法。gpu_predictor:使用 GPU 进行预测。当 tree _ method 为 gpu _ hist 时使用。当预测器设置为自动默认值时,GPU 的 hist 树方法能够提供基于 GPU 的预测,而不需要将训练数据复制到 GPU 内存中。如果显式指定了 GPU 预测器,那么所有的数据都会被复制到 GPU 中,只有在执行预测任务时才推荐使用 GPU。 - num_parallel_tree, [default=1]:每次迭代中构建的并行树的数量。此选项用于支持增强的随机森林。
- monotone_constraints:变量单调性约束。
- interaction_constraints:表示允许交互的约束。约束必须以嵌套列表的形式指定,例如[[0,1] ,[2,3,4]] ,其中每个内部列表是一组允许相互交互的特性索引。
(2)Hist 和 gpu _ hist 树方法的附加参数
single_precision_histogram, [default=false]:使用单精度来构建直方图,而不是双精度。
(3)Gpu _ hist 树方法的附加参数
deterministic_histogram, [default=true]:确定性地在 GPU 上建立直方图。由于浮点求和的非关联性,直方图的构建是不确定的。我们采用了一个预四舍五入的程序来减轻这个问题,这可能会导致略低的准确度。设置为 false 以禁用它
(4)Dart Booster 的附加参数
- sample_type [default= uniform]:抽样算法的类型。uniform:均匀地丢弃树。weighted:根据权值比例丢弃树。
- normalize_type [default= tree]:归一化算法的类型。tree:新树的权值等于每棵丢弃的树。forest:新树的权值相当于丢弃的树(森林)的权值。
- rate_drop [default=0.0]:丢弃率。取值范围:[0.0, 1.0]。
- one_drop [default=0]:当这个标志被启用时,至少有一棵树在丢失过程中被丢失。
- skip_drop [default=0.0]:在提升迭代中跳过 dropout 程序的概率。如果跳过 dropout ,则以与 gbtree 相同的方式添加新树。注意,非零 skip _ drop 的优先级高于 rate _ drop 或 one _ drop。取值范围:[0.0, 1.0]。
(5)线性基模型的参数
- lambda [default=0, alias: reg_lambda]:L2正则化项的权重。增加这个值将使模型更加保守。
- alpha [default=0, alias: reg_alpha]:L1正则化项对权值的影响。增加这个值会使模型更加保守。
- updater [default= shotgun]:线性模型拟合算法的选择。shotgun:基于霰弹枪算法的并行坐标下降法算法,使用 hogwild 并行性,因此在每次运行时产生不确定性解决方案。coord_descent:传统的 coord_descent的 算法也是多线程的,但是仍然可以产生确定性的解决坐标下降法。
- feature_selector [default= cyclic]:特征选择与排序方法。cyclic:通过一次循环一个特征进行确定性选择。shuffle:类似于循环,但在每次更新之前随机特征洗牌。random: 一个随机的(带有替换)坐标选择器。greedy:选择梯度大小最大的坐标。它具有 O (num _ feature ^ 2)复杂性。它是完全确定的。它允许通过设置 top _ k 参数,将选择限制为单变量权重变化幅度最大的每个组的 top _ k 特征。这样做可以将复杂性降低到 O (num _ feature * top _ k)。thrifty:节俭,近似贪婪的功能选择器。在循环更新之前,重新排序的特征是单变量权重变化的递减幅度。这个操作是多线程的,是线性复杂度近似于二次贪婪选择。它允许通过设置 top _ k 参数,将选择限制为单变量权重变化幅度最大的每个组的 top _ k 特征。
- top_k [default=0]:在贪婪和节俭功能选择顶部功能的数量。0的值意味着使用所有的特性。
(6)Tweedie 回归的参数
tweedie_variance_power [default=1.5]:控制 Tweedie 的方差的参数,取值范围: (1,2)。设置接近2倾向于伽玛分布,设置接近1倾向于泊松分布。
三、学习任务参数
指定学习任务和相应的学习目标。目标选项如下:
- objective [default=reg:squarederror]:reg:squarederror:平方损失回归。reg:squaredlogerror:对数损失平方回归 1 2 [ log ( p r e d + 1 ) − log ( l a b e l + 1 ) ] 2 \frac{1}{2} \left [ \log_{}{(pred+1)} -\log_{}{(label+1)} \right ]^2 21[log(pred+1)−log(label+1)]2 。所有输入标签都要求大于 -1。reg:logistic:逻辑回归模型。reg:pseudohubererror:拟胡伯损失回归,可以二次微分。binary:logistic:二分类逻辑回归,输出概率。binary:logitraw:二分类逻辑回归,转换成概率之前的输出得分。binary:hinge:二分类的 hinge 损失,预测的结果为0或1,而不是产生概率。count:poisson:计数数据的泊松回归,输出泊松分布的平均值。max _ delta _ step 在泊松回归中默认设置为0.7(用于保护优化)。survival:cox:考克斯回归的右删失生存时间数据(负值被认为是右删失)。survival:aft:删失生存时间数据的加速故障时间模型。aft_loss_distribution:以 survival:aft 为目标、aft-nloglik 为指标的概率密度函数。multi:softmax:使用 softmax 目标设置 XGBoost 执行多分类,还需要设置 num_class (类的数量)。multi:softprob:和 softmax 一样,但输出一个 ndata * nclass 的向量,可以进一步改造成 ndata * nclass 矩阵。结果包含每个数据点属于每个类别的预测概率。rank:pairwise:使用 LambdaMART 来执行成对排名,这样可以最小化成对的损失。rank:ndcg:使用 LambdaMART 来执行列表式的排名,其中规范化折扣累积收益(NDCG)最大化。rank:map:使用 LambdaMART 在平均精度(MAP)最大化的地方执行列表级别排序。reg:gamma:使用 log-link 的 γ 回归,产出是 γ 分布的平均值。例如,用于建模保险索赔严重性,或者用于任何可能是 γ 分布的结果。reg:tweedie:使用 log-link 的 Tweedie 回归。例如对保险中的总损失进行建模,或者对任何可能由 tweetie 分布的结果进行建模。自定义损失函数和评价指标:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- base_score [default=0.5]:所有实例的初始预测得分,全局偏差。对于足够的迭代次数,更改此值不会产生太大的影响。
- eval_metric [default according to objective]:验证数据的评估度量,将根据目标分配默认度量(回归的 rmse,分类的 logloss,排名的平均平均精度)。用户可以添加多个评估指标。Python 用户:记住将指标作为参数对列表而不是 map 传递,这样后者 eval _ metric 就不会覆盖前者。可以选择的评估度量:rmse:根均方误差。rmsle:根均方对数误差。这个度量减少了数据集中异常值产生的错误。但由于使用了对数函数,当预测值小于 -1时,rmsle 可能会输出 nan。mae:平均绝对误差。mape:平均绝对百分误差。mphe:平均伪 Huber 误差。logloss:负对数似然。error:二进制分类错误率。它被计算为 # (错误的情况)/# (所有情况)。对于预测,评价将预测值大于0.5的实例视为正实例,其他实例视为负实例。error@t:不同于0.5二进制分类阈值可以通过提供一个数值通过’t’指定。merror:多元分类错误率。它被计算为 # (错误情况)/# (所有情况)。mlogloss:多分类对数似然。auc: ROC曲线下面积,可用于分类和学习排序任务。二分类时,目标应该是二进制逻辑回归或类似输出概率的函数。当多分类时,目标函数应该是 softprob 而不是 multi:softmax,因为后者不能输出概率。如果输入数据集只包含负值或正值样本,则输出为 NaN。aucpr:在 PR 曲线下面积。可用于二进制分类和学习排序任务。ndcg:标准化折扣累积收益。map: Mean Average Precision。ndcg@n, map@n:“ n”可以作为一个整数分配,以便在评估列表中去掉最高的位置。ndcg-, map-, ndcg@n-, map@n-:在 XGBoost 中,NDCG 和 MAP 将评估一个名单的得分,而不包括任何为1的阳性样本。通过在评估指标 XGBoost 中添加“-”,可以将这些评分评估为0,以便在某些条件下保持一致。poisson-nloglik:泊松回归的负对数似然。gamma-nloglik: γ 回归的负对数似然。cox-nloglik:Cox 比例风险回归的负偏对数似然估计。gamma-deviance: γ 回归的残差。tweedie-nloglik:Tweedie 回归的负对数似然。aft-nloglik:加速失效时间模型的负对数似然。interval-regression-accuracy:预测标签落入区间删失标签的数据点的分数。仅适用于区间删失数据。
- seed [default=0]:随机数种子。
- seed_per_iteration [default=false]:种子 PRNG 通过迭代器号决定,这个选项将在分布式模式下自动打开。
4. XGBoost 的实例
(1)红酒分类

我们使用数据集里所有的特征。
设置参数:
多分类问题‘eval_metric’选择‘mlogloss’,不能选择‘auc’

训练:

保存模型:

加载保存的模型:

设置早停机制:
在第6540轮,训练停止,返回最佳模型参数。
预测:
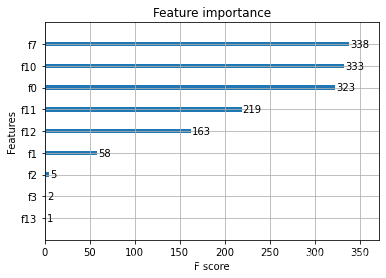
特征重要性绘图:
(2)鸢尾花分类
加载数据集并分割:

设定参数:

模型训练和预测:
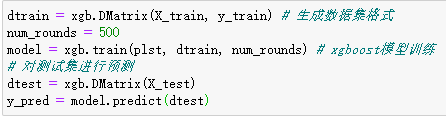
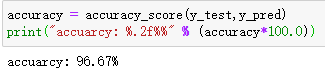
计算准确率:
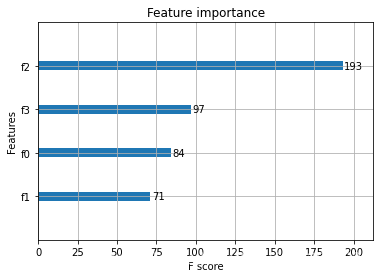
特征重要性绘图:

(3)波士顿房价回归
加载数据并训练:

预测并对特征重要性绘图:

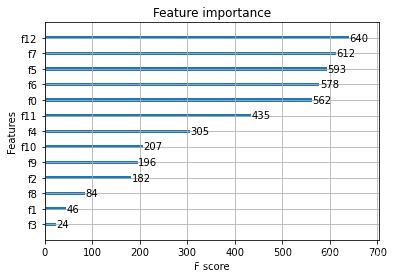
(4)XGBoost 调参
加载数据集并分割,设置调参范围:

创建模型:

因为网格搜索调参需要花费很长的时间,这里示例只对 ‘max_depth’ 单独进行了调参,结果如下:

(5)基于天气数据集的XGBoost分类实战
用到的天气数据包网址:https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/7XGBoost/train.csv
函数库导入:
本次我们选择天气数据集进行方法的尝试训练,现在有一些由气象站提供的每日降雨数据,我们需要根据历史降雨数据来预测明天会下雨的概率。样例涉及到的测试集数据test.csv与train.csv的格式完全相同,但其RainTomorrow未给出,为预测变量。
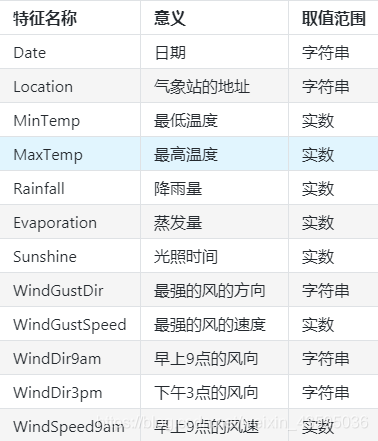
数据的各个特征描述如下:
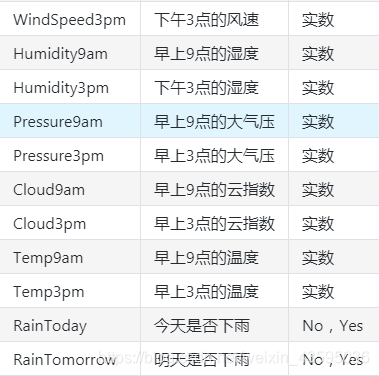
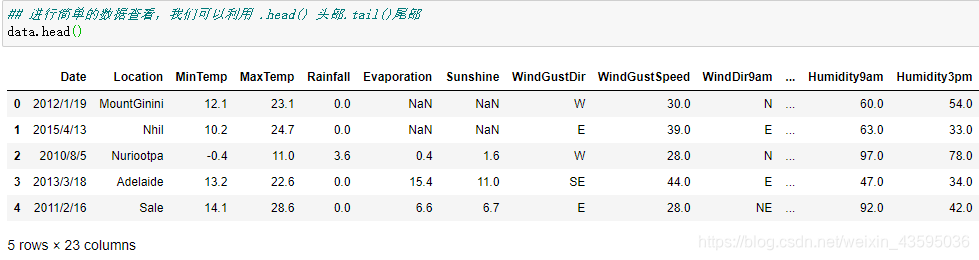
数据信息读取、载入和查看:

<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 106644 entries, 0 to 106643
Data columns (total 23 columns):
Column Non-Null Count Dtype
0 Date 106644 non-null object
1 Location 106644 non-null object
2 MinTemp 106183 non-null float64
3 MaxTemp 106413 non-null float64
4 Rainfall 105610 non-null float64
5 Evaporation 60974 non-null float64
6 Sunshine 55718 non-null float64
7 WindGustDir 99660 non-null object
8 WindGustSpeed 99702 non-null float64
9 WindDir9am 99166 non-null object
10 WindDir3pm 103788 non-null object
11 WindSpeed9am 105643 non-null float64
12 WindSpeed3pm 104653 non-null float64
13 Humidity9am 105327 non-null float64
14 Humidity3pm 103932 non-null float64
15 Pressure9am 96107 non-null float64
16 Pressure3pm 96123 non-null float64
17 Cloud9am 66303 non-null float64
18 Cloud3pm 63691 non-null float64
19 Temp9am 105983 non-null float64
20 Temp3pm 104599 non-null float64
21 RainToday 105610 non-null object
22 RainTomorrow 106644 non-null object
dtypes: float64(16), object(7)
memory usage: 18.7+ MB
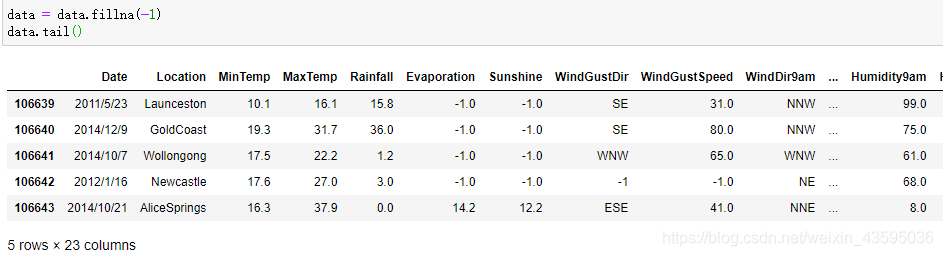
采用-1将缺失值进行填补:

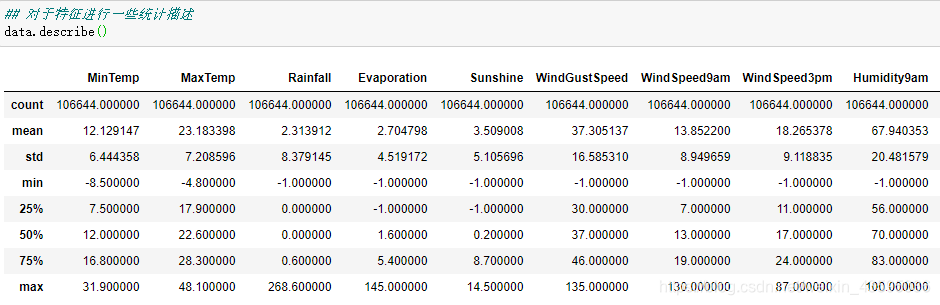
数据集中的负样本数量远大于正样本数量,属于数据类别不均衡问题。
数据可视化:

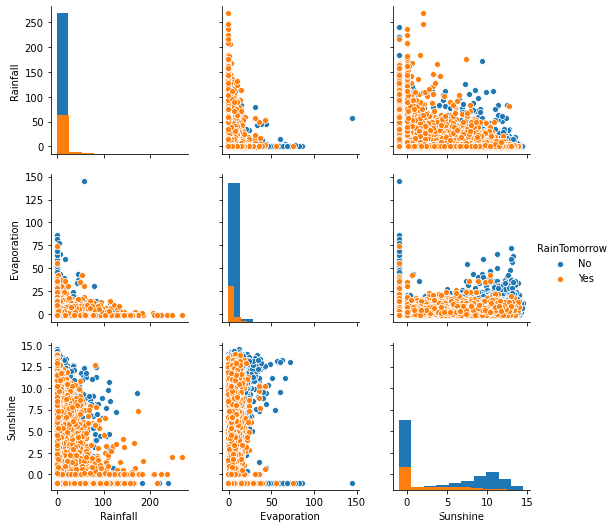
从上图可见2D情况下不同的特征组合对于第二天下雨与不下雨的散点分布,从而反映出区分能力。

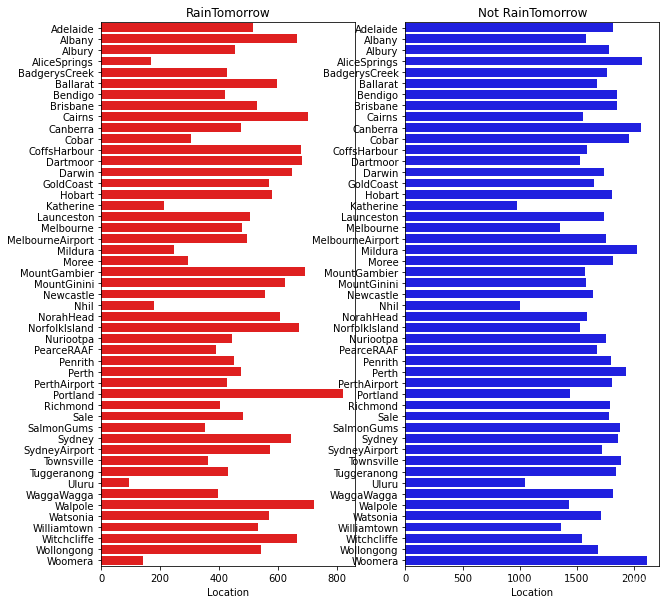
从上图可以发现不同地区降雨情况差别很大,有些地方明显更容易降雨。


上图我们可以发现,今天下雨明天不一定下雨,但今天不下雨,第二天大概率也不下雨。
对离散变量进行编码:
由于XGBoost无法处理字符串类型的数据,我们需要一些方法讲字符串数据转化为数据。一种最简单的方法是把所有的相同类别的特征编码成同一个值,所以最后编码的特征值是在 [0, 特征数量-1] 之间的整数。除此之外,还有独热编码、求和编码、留一法编码等等方法可以获得更好的效果。


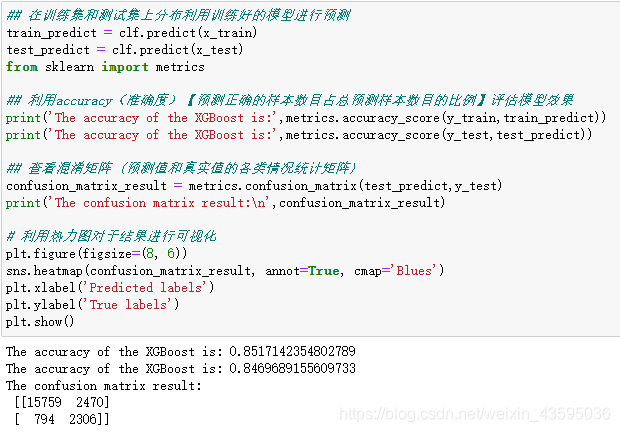
利用 XGBoost 进行训练与预测:

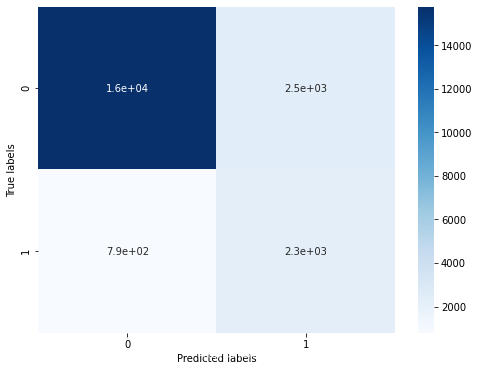
利用 XGBoost 进行特征选择:

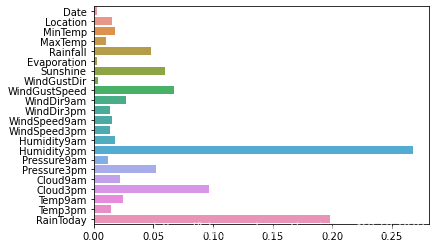
从图中我们可以发现下午3点的湿度与今天是否下雨是决定第二天是否下雨最重要的因素。
除此之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性。
- weight:是以特征用到的次数来评价
- gain:当利用特征做划分的时候的评价基尼指数
- cover:利用一个覆盖样本的指标二阶导数平均值来划分。
- total_gain:总基尼指数
- total_cover:总覆盖


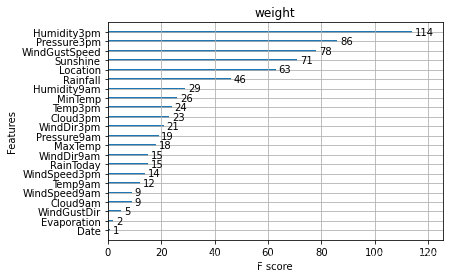
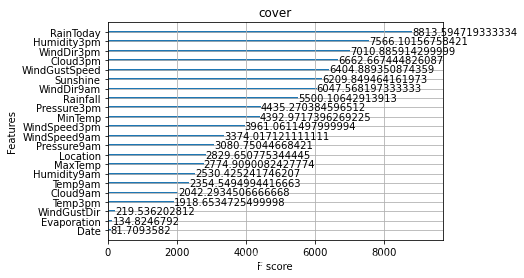
通过调整参数获得更好的效果:
XGBoost中包括但不限于下列对模型影响较大的参数:
- learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。
- subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合, 取值范围零到一。
- colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。
- max_depth:系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。
调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。


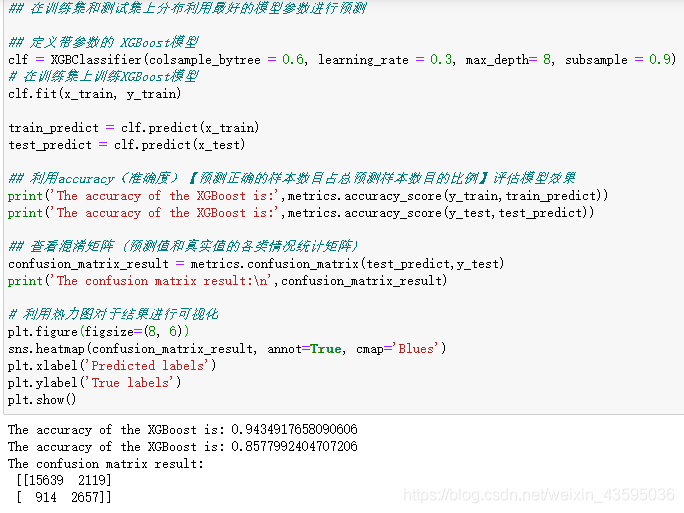
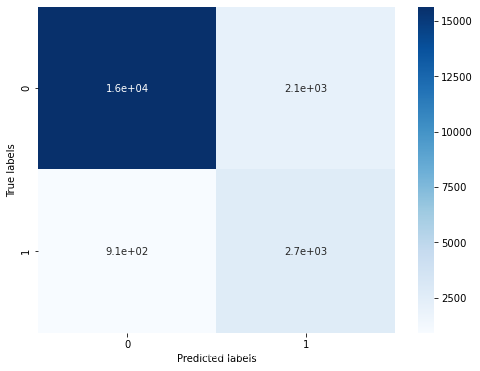
测试集正确率由84.7%提升到了85.8%,模型调参带来了明显的正确率提升。
本文实验部分来源于Datawhale的开源学习内容,链接是https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning
最后一个案例来自阿里云天池学习,链接是https://tianchi.aliyun.com/course/278/3423
感谢Datawhale对开源学习的贡献!

















 9954
9954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









