






一、过拟合:剪枝参数与回归模型调参
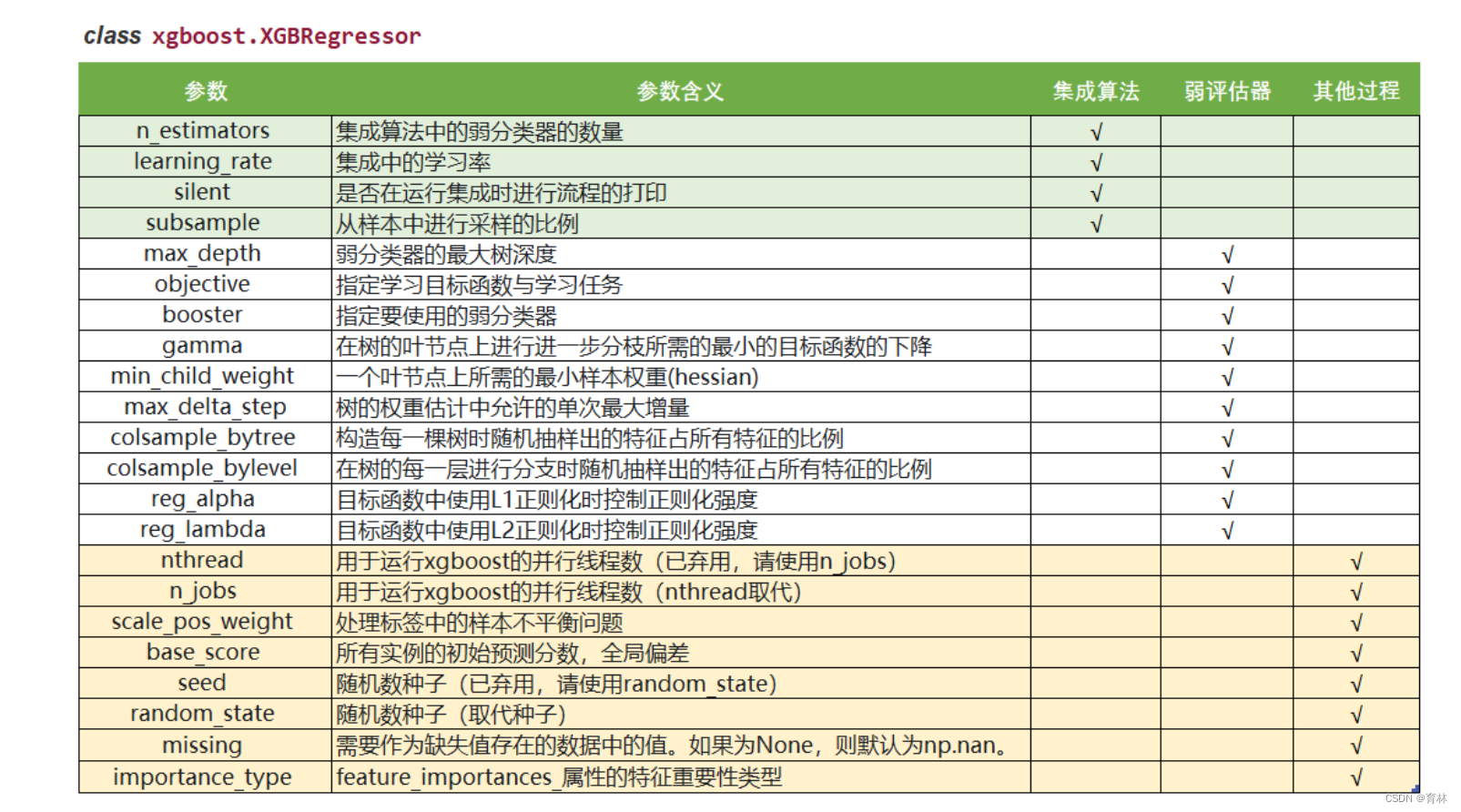
class xgboost.XGBRegressor (max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective=‘reg:linear’, booster=‘gbtree’, n_jobs=1, nthread=None, gamma=0, min_child_weight=1,
max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, importance_type=‘gain’, kwargs)
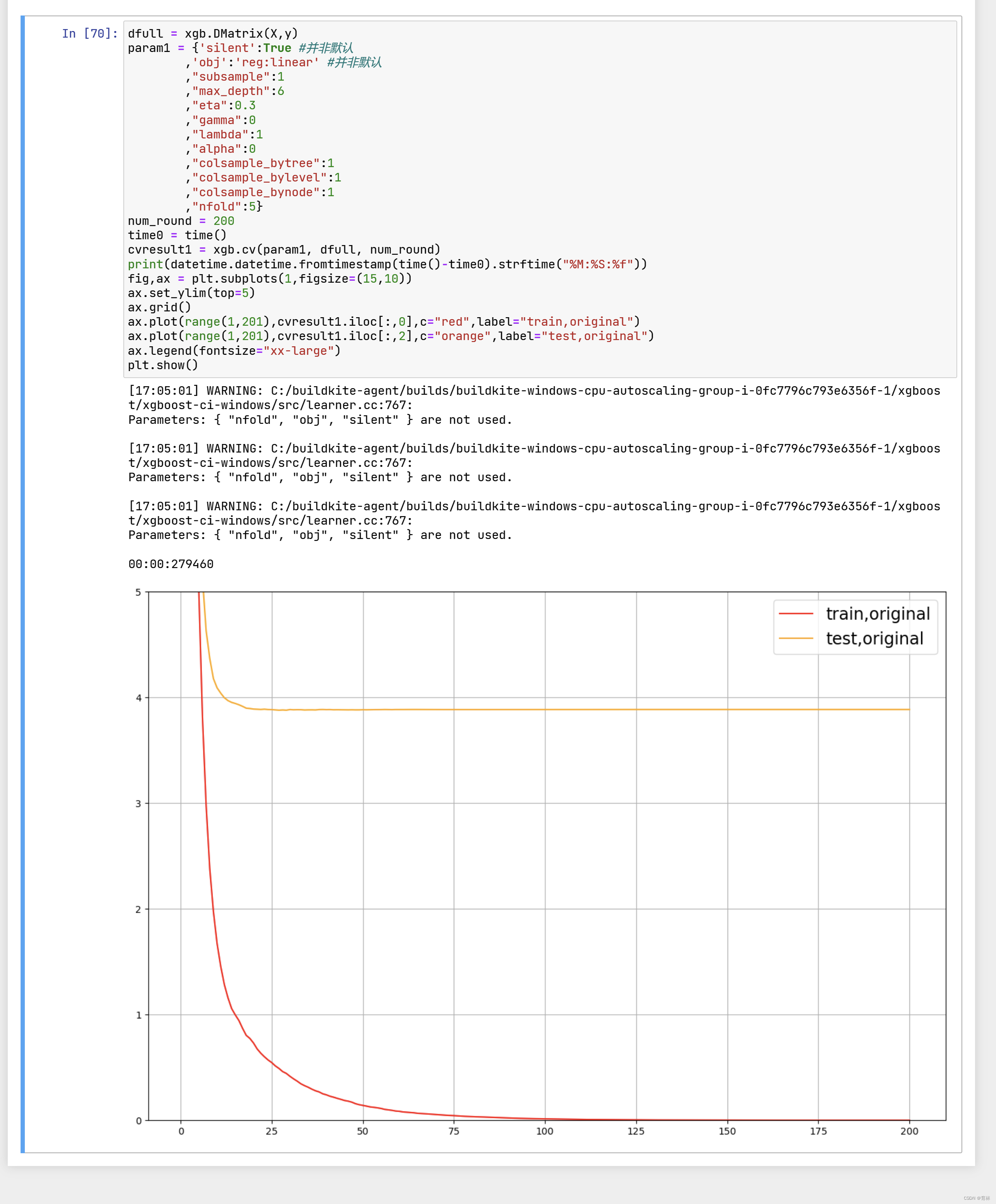
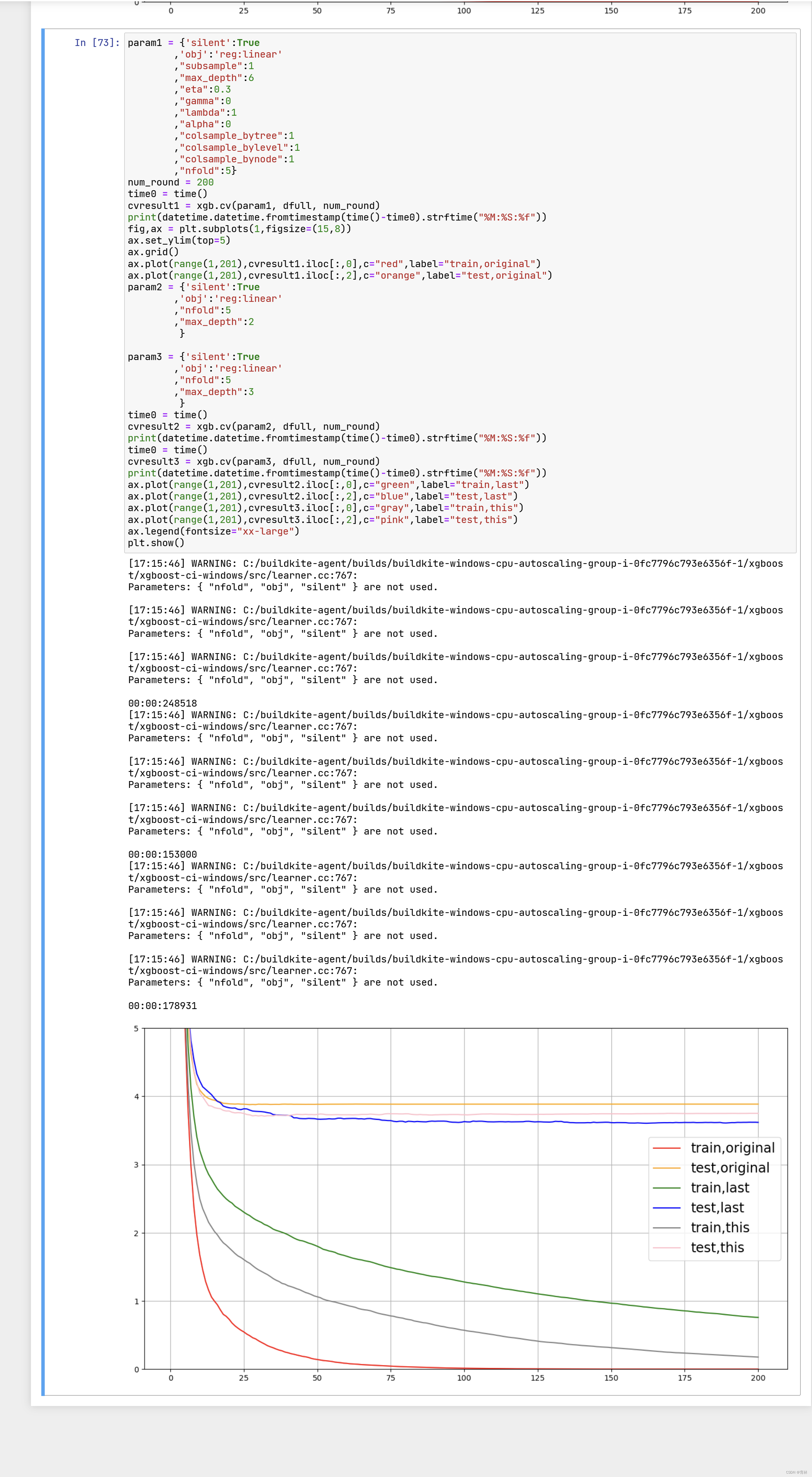
从曲线上可以看出,模型现在处于过拟合的状态。我们决定要进行剪枝。我们的目标是:训练集和测试集的结果尽量
接近,如果测试集上的结果不能上升,那训练集上的结果降下来也是不错的选择(让模型不那么具体到训练数据,增
加泛化能力)。在这里,我们要使用三组曲线。一组用于展示原始数据上的结果,一组用于展示上一个参数调节完毕
后的结果,最后一组用于展示现在我们在调节的参数的结果。具体怎样使用,我们来看:

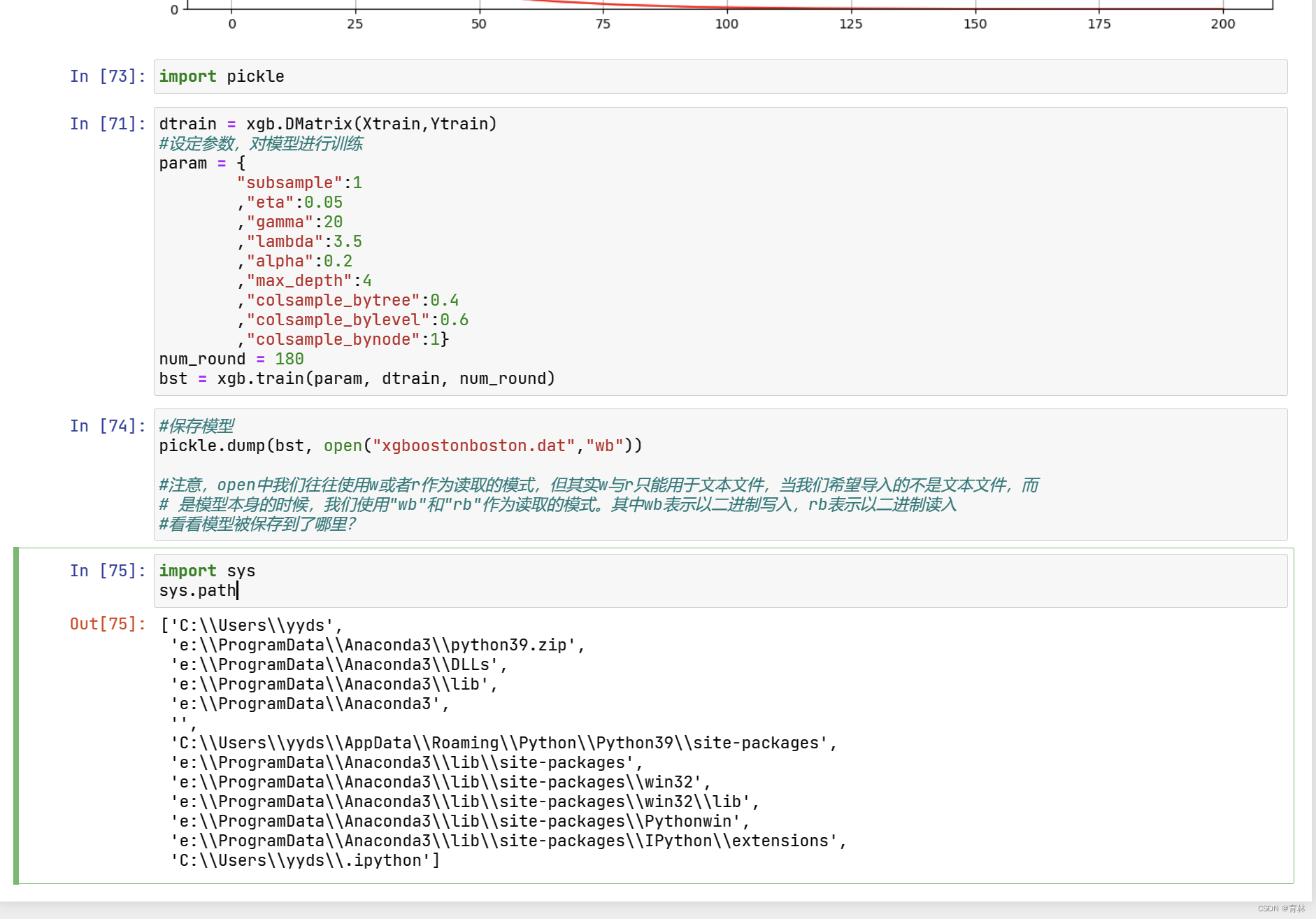
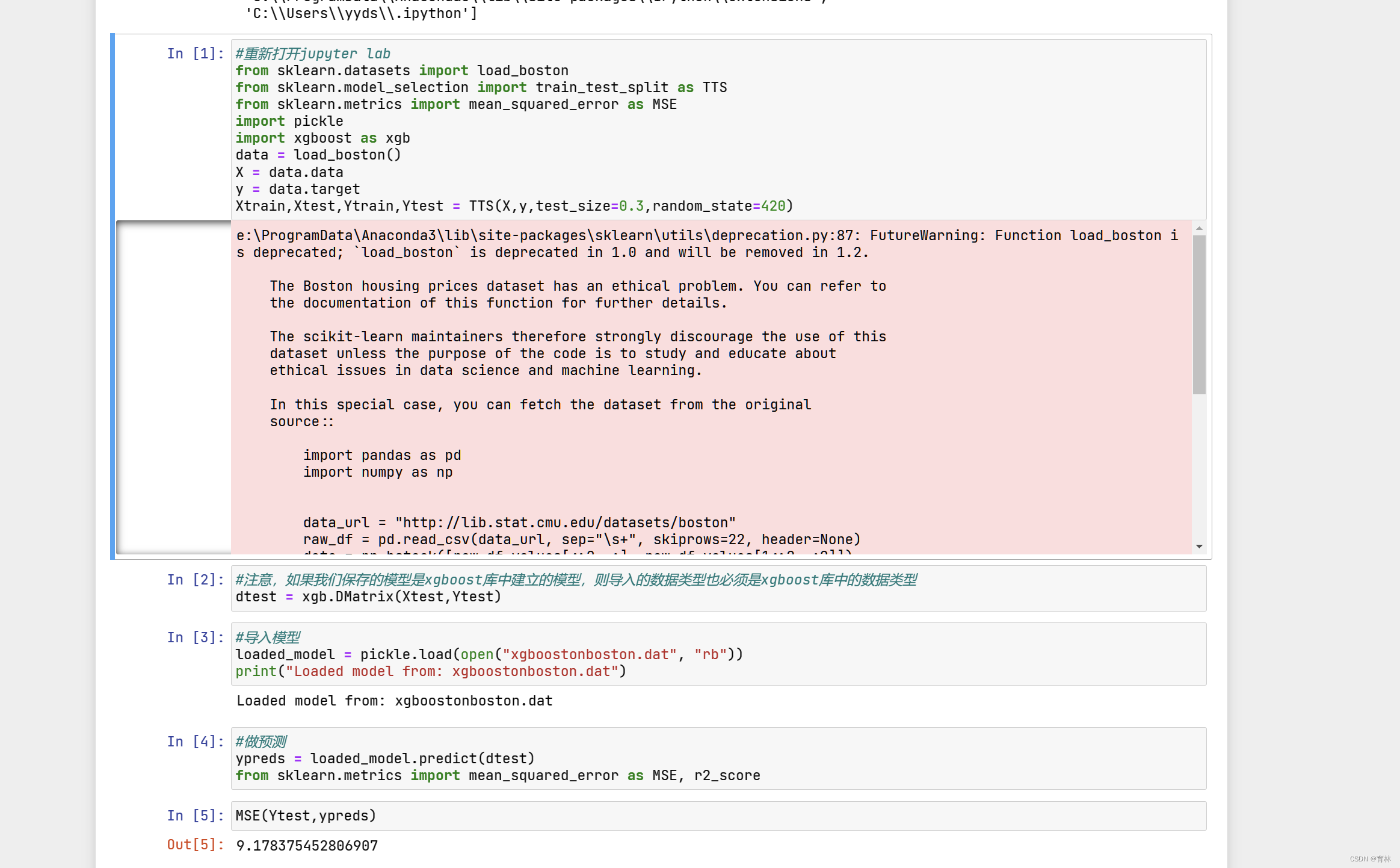
二、XGBoost模型的保存和调用
pickle是python编程中比较标准的一个保存和调用模型的库,我们可以使用pickle和open函数的连用,来将我们的模
型保存到本地。以刚才我们已经调整好的参数和训练好的模型为例,我们可以这样来使用pickle:
使用Joblib保存和调用模型
三、分类案例:XGB中的样本不均衡问题
在之前的学习中,我们一直以回归作为演示的例子,这是由于回归是XGB的常用领域的缘故。然而作为机器学习中的
大头,分类算法也是不可忽视的,XGB作为分类的例子自然也是非常多。存在分类,就会存在样本不平衡问题带来的
影响,XGB中存在着调节样本不平衡的参数scale_pos_weight,这个参数非常类似于之前随机森林和支持向量机中
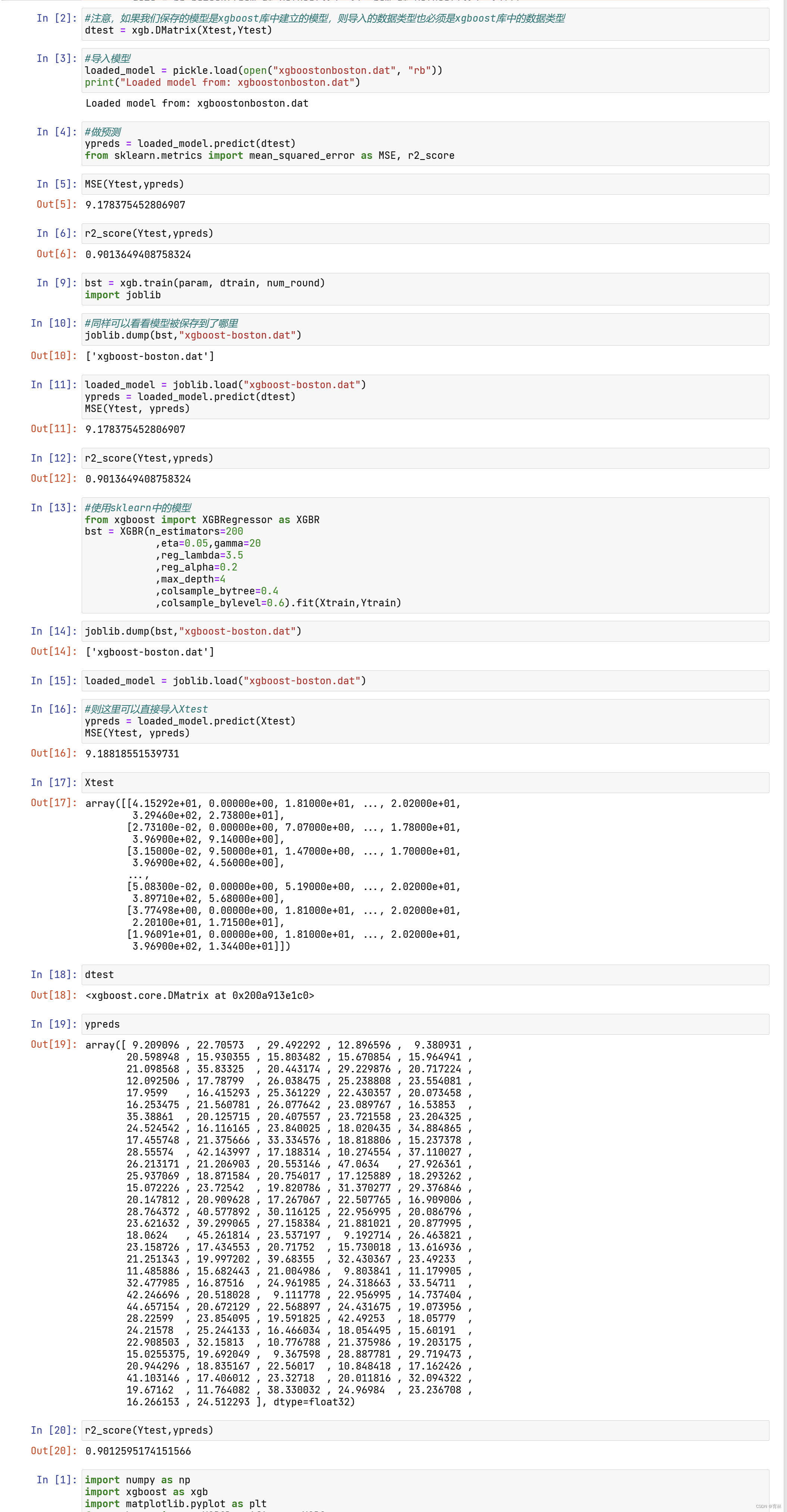
我们都使用到过的class_weight参数,通常我们在参数中输入的是负样本量与正样本量之比
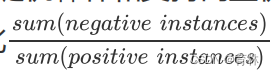

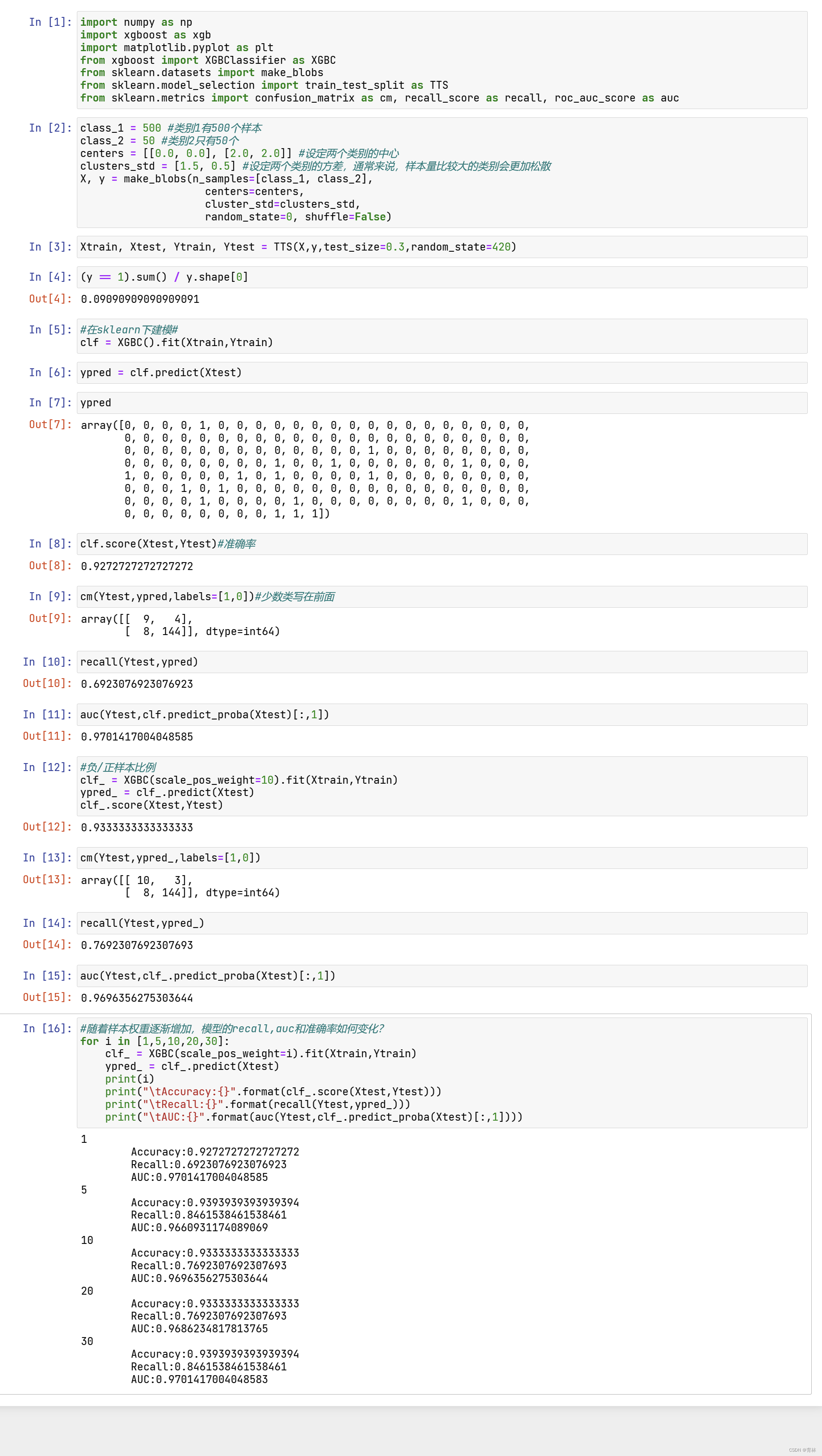
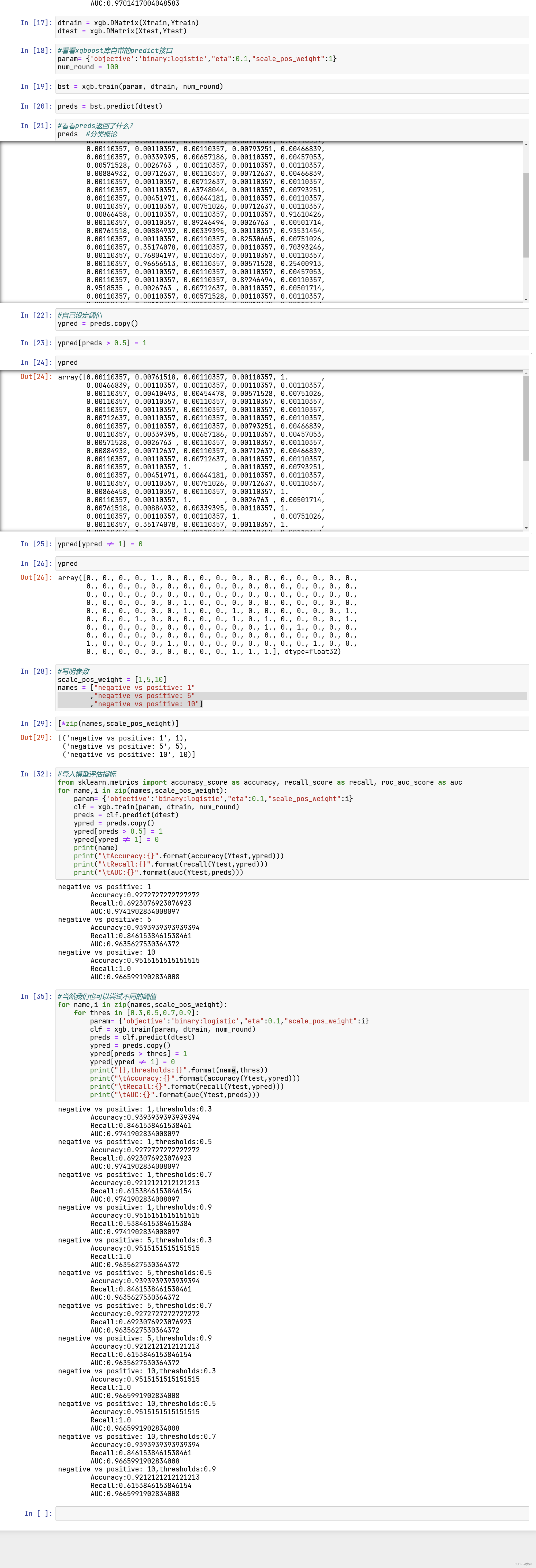
四、 XGBoost类中的其他参数和功能
更多计算资源:n_jobs
nthread和n_jobs都是算法运行所使用的线程,与sklearn中规则一样,输入整数表示使用的线程,输入-1表示使用计
算机全部的计算资源。如果我们的数据量很大,则我们可能需要这个参数来为我们调用更多线程。
降低学习难度:base_score
base_score是一个比较容易被混淆的参数,它被叫做全局偏差,在分类问题中,它是我们希望关注的分类的先验概
率。比如说,如果我们有1000个样本,其中300个正样本,700个负样本,则base_score就是0.3。对于回归来说,
这个分数默认0.5,但其实这个分数在这种情况下并不有效。许多使用XGBoost的人已经提出,当使用回归的时候
base_score的默认应该是标签的均值,不过现在xgboost库尚未对此做出改进。使用这个参数,我们便是在告诉模型
一些我们了解但模型不一定能够从数据中学习到的信息。通常我们不会使用这个参数,但对于严重的样本不均衡问
题,设置一个正确的base_score取值是很有必要的。
生成树的随机模式:random_state
在xgb库和sklearn中,都存在空值生成树的随机模式的参数random_state。在之前的剪枝中,我们提到可以通过随
机抽样样本,随机抽样特征来减轻过拟合的影响,我们可以通过其他参数来影响随机抽样的比例,却无法对随机抽样
干涉更多,因此,真正的随机性还是由模型自己生成的。如果希望控制这种随机性,可以在random_state参数中输
入固定整数。需要注意的是,xgb库和sklearn库中,在random_state参数中输入同一个整数未必表示同一个随机模
式,不一定会得到相同的结果,因此导致模型的feature_importances也会不一致。
自动处理缺失值:missing
XGBoost被设计成是能够自动处理缺失值的模型,这个设计的初衷其实是为了让XGBoost能够处理稀疏矩阵。我们可
以在参数missing中输入一个对象,比如np.nan,或数据的任意取值,表示将所有含有这个对象的数据作为空值处
理。XGBoost会将所有的空值当作稀疏矩阵中的0来进行处理,因此在使用XGBoost的时候,我们也可以不处理缺失
值。当然,通常来说,如果我们了解业务并且了解缺失值的来源,我们还是希望手动填补缺失值。














 2381
2381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









