







[2020-AAAI] Not All Attention Is Needed: Gated Attention Network for Sequence Data
Abstract
传统的注意机制一般是全局的,它注意到句子中所有的单词,但有些注意权重可能很小。然而,通过对几个自然语言处理任务的研究,我们发现只有一小部分输入与输出目标相关。这也与我们的直觉一致,即不是所有的注意力都需要,特别是对于长序列。在不相关的元素上计算注意力权重是多余的。不仅如此,由于注意机制给每个输入单元分配了一个权重,即使是不相关的单元也有一个较小的权重,相关单元的注意权重变得很小,特别是对于长序列,导致性能下降。
为了解决这一问题,我们提出了一种新的方法——门控注意网络(GA-Net),该方法利用辅助网络动态地选择需要关注的元素子集,并计算注意权值来聚集所选择的元素。GA-Net包括一个辅助网络和一个骨干网。辅助网络生成一组输入相关的二进制门,以确定每个单词是否需要关注。骨干注意网络是一个常规注意网络,它执行主要的循环计算,但仅通过计算注意权值来聚合选定单词的隐藏状态。注意单元与隐藏状态序列之间的联系是稀疏的,而不是传统注意机制中的紧密联系。如图1所示,所提出的GA-Net具有稀疏的注意结构,并且已经学会只注意重要的单词。辅助网络和骨干注意网络采用端到端的方式共同训练。

关于soft-attention/global-attention,hard-attention and local-attention:
- soft-attention/global-attention:每个状态都有一个权重
- hard-attention:每次只关注一个state,这样计算效率高,但是丢失了很多输入的信息
- local-attention:局部注意力是软注意力和硬注意力之间的平衡。目标只会盯着窗口内的相邻的state。其局限性也是很明显的,因为非邻居也会对目标产生影响。
因此,我们提出了一种稀疏注意机制GA-Net,它可以动态地选择需要注意的重要输入。它不仅提高了软注意的计算效率,而且比硬注意和局部注意保留了更多的信息,获得了更好的可解释性。
Gated Attention Network
模型的网络结构如下:

GA-Net包括一个骨干网络和辅助网络。
上图右边为骨干网络,左边是辅助网络。与传统的注意力机制网络不同,骨干网络是带有门控机制的注意力网络,其中门控机制g1, …, gt取值为1或0决定来自当前状态的信息是否应流入,以达到选择性地激活部分网络的目的。辅助网络的作用是生成二进制门,它观察输入的句子,并为每个位置生成二进制门,以确定是否需要注意该位置。辅助网络输出是概率pt计算如下:
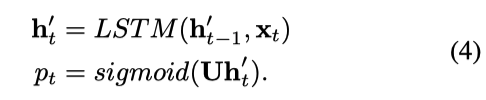
概率pt决定了闸门开启的概率,将pt转化为伯努利0-1分布:
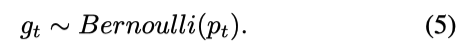
由于门控的离散值为0和1,不能通过梯度下降来反向传播误差,论文通过引入Gumbel-Softmax来解决梯度下降的问题。Gumbel-Softmax旨在通过连续松弛的Gumbel-Softmax分布来近似离散分布。为了使辅助网络在训练过程中可区分,论文用Gumbel-Softmax分布代替Bernoulli分布,独热向量的softmax的近似值计算如下:
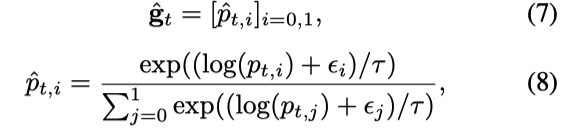
其中εi是Gumbel(0,1)的随机样本,当温度τ趋于0时,Gumbel- softmax分布趋于1 -hot。具有软门的注意权值可以用:
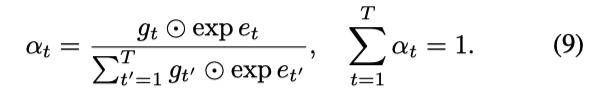
Experiments
文本分类在不同数据集上的分类精度结果:

论文证实了可以通过更稀疏的注意力结构实现与完全注意力连接相一致的性能。尤其是对于IMDB数据集,每个输入仅打开19.99%的门。
最后,论文通过分析如下图所示的两个案例进一步验证了所提出的GA-Net具有选择序列中相关单元的能力。

实验也证明了辅助网络采用LSTM效果更好:
BiLSTM+AUX F NN和BiLSTM+AUX AT T都优于所有基线模型。这再次证明并不是所有的注意力都是必需的,辅助网络在选择有意义的单位方面的能力也是必需的。与BiLSTM+AUX F NN和BiLSTM+AUX AT T相比,从精度和密度两方面来看,BiLSTM+AUX LSTM仍然是性能最好的。因此,LSTM在处理输入为序列的类似任务时是一个比较好的辅助网络选择。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









