







目录
第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)
第三周:浅层神经网络(Shallow neural networks)
3.9 神 经 网 络 的 梯 度 下 降 ( Gradient descent for neural networks)
在这个视频中,我会给你实现反向传播或者说梯度下降算法的方程组,在下一个视频我们会介绍为什么这几个特定的方程是针对你的神经网络实现梯度下降的正确方程。
你的单隐层神经网络会有 W [ 1 ] , b [ 1 ] , W [ 2 ] , b [ 2 ] W^{[1]},b^{[1]},W^{[2]},b^{[2]} W[1],b[1],W[2],b[2]这些参数,还有个𝑛𝑥表示输入特征的个数, n [ 1 ] n^{[1]} n[1]表示隐藏单元个数, n [ 2 ] n^{[2]} n[2]表示输出单元个数。
矩阵 W [ 1 ] W^{[1]} W[1]的维度就是 ( n [ 1 ] , n [ 0 ] ) (n^{[1]},n^{[0]}) (n[1],n[0]), b [ 1 ] b^{[1]} b[1]就是 n [ 1 ] n^{[1]} n[1]维向量,可以写成 ( n [ 1 ] , 1 ) (n^{[1]}, 1) (n[1],1),就是一个的列向量。 矩阵 W [ 2 ] W^{[2]} W[2]的维度就是 ( n [ 2 ] , n [ 1 ] ) (n^{[2]}, n^{[1]}) (n[2],n[1]), b [ 2 ] b^{[2]} b[2]的维就是 ( n [ 2 ] , 1 ) (n^{[2]}, 1) (n[2],1)维度。
你还有一个神经网络的成本函数,假设你在做二分类任务,那么你的成本函数等于:
Cost function: 公式:
J
(
W
[
1
]
,
b
[
1
]
,
W
[
2
]
,
b
[
2
]
)
=
1
m
∑
i
=
1
m
L
(
y
^
,
y
)
J(W[1], b[1], W[2], b[2]) =\frac{1}{m}\sum_{i=1}^{m}L(\hat{y} , y)
J(W[1],b[1],W[2],b[2])=m1∑i=1mL(y^,y)
loss function 和之前做 logistic 回归完全一样。
训练参数需要做梯度下降,在训练神经网络的时候,随机初始化参数很重要,而不是初始化成全零。当你参数初始化成某些值后,每次梯度下降都会循环计算以下预测值:
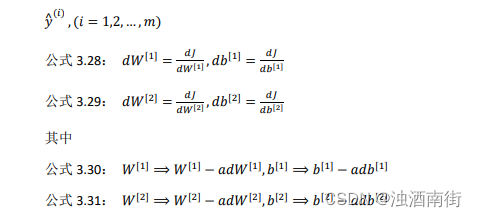
正向传播方程如下(之前讲过):forward propagation:
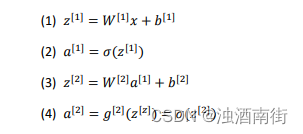
反向传播方程如下:back propagation:

上述是反向传播的步骤,注:这些都是针对所有样本进行过向量化,Y是1 ×m的矩阵;这里 np.sum 是 python 的 numpy 命令,axis=1 表示水平相加求和,keepdims 是防止python 输出那些古怪的秩数(n, ),加上这个确保阵矩阵
d
b
[
2
]
db^{[2]}
db[2]这个向量输出的维度为(n, 1)这样标准的形式。
目前为止,我们计算的都和 Logistic 回归十分相似,但当你开始计算反向传播时,你需要计算,是隐藏层函数的导数,输出在使用 sigmoid 函数进行二元分类。这里是进行逐个元素乘积,因为 W [ 2 ] T d z [ 2 ] W^{[2]T}dz^{[2]} W[2]Tdz[2]和 ( z [ 1 ] ) (z[1]) (z[1])这两个都为 ( n [ 1 ] , m ) (n^{[1]}, m) (n[1],m)矩阵;
还有一种防止 python 输出奇怪的秩数,需要显式地调用 reshape 把 np.sum 输出结果写成矩阵形式。
以上就是正向传播的 4 个方程和反向传播的 6 个方程,这里我是直接给出的,在下个视频中,我会讲如何导出反向传播的这 6 个式子的。如果你要实现这些算法,你必须正确执行正向和反向传播运算,你必须能计算所有需要的导数,用梯度下降来学习神经网络的参数;你也可以许多成功的深度学习从业者一样直接实现这个算法,不去了解其中的知识。
3.10(选修)直观理解反向传播(Backpropagation intuition)
这个视频主要是推导反向传播。
下图是逻辑回归的推导:
回想一下逻辑回归的公式(参考公式 3.2、公式 3.5、公式 3.6、公式 3.15) 公式 3.38:
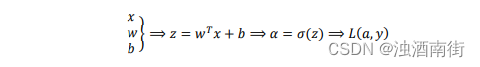
所以回想当时我们讨论逻辑回归的时候,我们有这个正向传播步骤,其中我们计算𝑧,然后𝑎,然后损失函数𝐿。
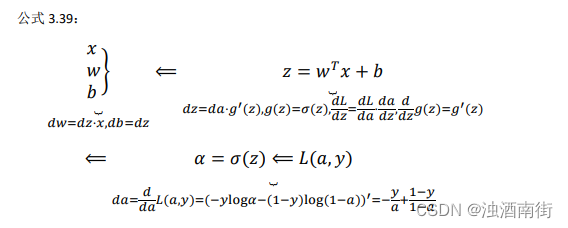
神经网络的计算中,与逻辑回归十分类似,但中间会有多层的计算。下图是一个双层神经网络,有一个输入层,一个隐藏层和一个输出层。
前向传播:
计算
z
[
1
]
z^{[1]}
z[1],
a
[
1
]
a^{[1]}
a[1],再计算
z
[
2
]
z^{[2]}
z[2],
a
[
2
]
a^{[2]}
a[2],最后得到 loss function。
反向传播:
向后推算出
d
a
[
2
]
da^{[2]}
da[2],然后推算出
d
z
[
2
]
dz^{[2]}
dz[2],接着推算出
d
a
[
1
]
da^{[1]}
da[1],然后推算出
d
z
[
1
]
dz^{[1]}
dz[1]。我们不需要对x求导,因为x是固定的,我们也不是想优化x。向后推算出
d
a
[
2
]
da^{[2]}
da[2],然后推算出
d
z
[
2
]
dz^{[2]}
dz[2]的步骤可以合为一步:
公式 3.40: d z [ 2 ] = a [ 2 ] − y dz^{[2]} = a^{[2]} − y dz[2]=a[2]−y, d W [ 2 ] = d z [ 2 ] a [ 1 ] T dW^{[2]} = dz^{[2]}a^{[1]T} dW[2]=dz[2]a[1]T(注意:逻辑回归中;为什么 a [ 1 ] T a^{[1]T} a[1]T多了个转置:dw中的W(视频里是 W i [ 2 ] W_i^{[2]} Wi[2])是一个列向量,而 W [ 2 ] W^{[2]} W[2]是个行向量,故需要加个转置);
公式 3.41:
d
b
[
2
]
=
d
z
[
2
]
db^{[2]} = dz^{[2]}
db[2]=dz[2]
公式3.42:KaTeX parse error: Double superscript at position 36: …^{[2]}∗ g^{[1]}'̲(z^{[1]}) 注意:这里的矩阵:W[2]的维度是:(
n
[
2
]
,
n
[
1
]
n^{[2]},n^{[1]}
n[2],n[1])。
z
[
2
]
z^{[2]}
z[2] ,
d
z
[
2
]
dz^{[2]}
dz[2]的维度都是:(
n
[
2
]
,
1
n^{[2]},1
n[2],1),如果是二分类,那维度就是(1,1)。
z
[
1
]
z^{[1]}
z[1],
d
z
[
1
]
dz^{[1]}
dz[1]的维度都是:(
n
[
1
]
,
1
n^{[1]},1
n[1],1)。
证明过程: 见公式 3.42,
其中
W
[
2
]
T
d
z
[
2
]
W^{[2]T}dz^{[2]}
W[2]Tdz[2]维度为:(
n
[
1
]
,
n
[
2
]
n^{[1]}, n^{[2]}
n[1],n[2])、(
n
[
2
]
,
1
n^{[2]}, 1
n[2],1)相乘得到(
n
[
1
]
,
1
n^{[1]}, 1
n[1],1),和
z
[
1
]
z^{[1]}
z[1]维度相同,KaTeX parse error: Double superscript at position 8: g^{[1]}'̲(z^{[1]})的维度为(
n
[
1
]
,
1
n^{[1]}, 1
n[1],1),这就变成了两个都是(
n
[
1
]
,
1
n^{[1]}, 1
n[1],1)向量逐元素乘积。
实现后向传播有个技巧,就是要保证矩阵的维度相互匹配。最后得到
d
W
[
1
]
和
d
b
[
1
]
dW^{[1]}和db^{[1]}
dW[1]和db[1],公式 3.43:
d
W
[
1
]
=
d
z
[
1
]
x
T
dW^{[1]} = dz^{[1]}x^T
dW[1]=dz[1]xT,
d
b
[
1
]
=
d
z
[
1
]
db^{[1]} = dz^{[1]}
db[1]=dz[1]可以看出
d
W
[
1
]
和
d
W
[
2
]
dW^{[1]} 和dW^{[2]}
dW[1]和dW[2] 非常相似,其中x扮演了
a
[
0
]
a^{[0]}
a[0]的角色,
x
T
x^T
xT等同于
a
[
0
]
T
a^{[0]T}
a[0]T。

下图写了主要的推导过程:

吴恩达老师认为反向传播的推导是机器学习领域最难的数学推导之一,矩阵的导数要用链式法则来求,如果这章内容掌握不了也没大的关系,只要有这种直觉就可以了。还有一点,就是初始化你的神经网络的权重,不要都是 0,而是随机初始化,下一章将详细介绍原因。
3.11 随机初始化(Random+Initialization)
当你训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为 0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为 0,那么梯度下降将不会起作用。
让我们看看这是为什么。有两个输入特征,
n
[
0
]
n^{[0]}
n[0] = 2,2 个隐藏层单元
n
[
1
]
n^{[1]}
n[1]就等于 2。 因此与一个隐藏层相关的矩阵,或者说
W
[
1
]
W^{[1]}
W[1]是 22 的矩阵,假设把它初始化为 0 的 22 矩阵,
b
[
1
]
b^{[1]}
b[1]也等于
[
00
]
T
[0 0]^T
[00]T,把偏置项𝑏初始化为 0 是合理的,但是把w初始化为 0 就有问题了。 那这个问题如果按照这样初始化的话,你总是会发现
a
1
[
1
]
a_1^{[1]}
a1[1] 和
a
2
[
1
]
a_2^{[1]}
a2[1]相等,这个激活单元和这个激活单元就会一样。因为两个隐含单元计算同样的函数,当你做反向传播计算时,这会导致
d
z
1
[
1
]
dz_1^{[1]}
dz1[1] 和
d
z
2
[
1
]
dz_2^{[1]}
dz2[1]也会一样,对称这些隐含单元会初始化得一样,这样输出的权值也会一模一样,由此
W
[
2
]
W^{[2]}
W[2]等于[0 0];
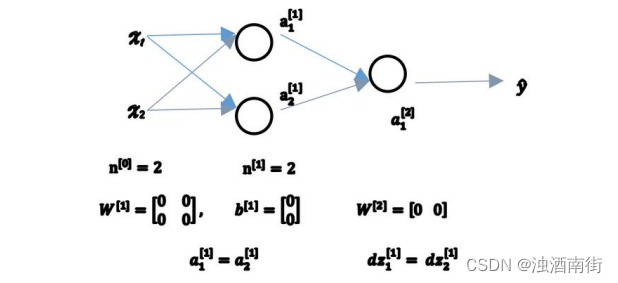
图 3.11.1 但是如果你这样初始化这个神经网络,那么这两个隐含单元就会完全一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数,令人困惑。dW会是一个这样的矩阵,每一行有同样的值因此我们做权重更新把权重
W
[
1
]
⟹
W
[
1
]
−
α
d
W
W^{[1]} ⟹ W^{[1]} − αdW
W[1]⟹W[1]−αdW每次迭代后的𝑊[1],第一行等于第二行。
由此可以推导,如果你把权重都初始化为 0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过 1 个隐含单元也没什么意义,因为他们计算同样的东西。当然更大的网络,比如你有 3 个特征,还有相当多的隐含单元。
如果你要初始化成 0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为你想要两个不同的隐含单元计算不同的函数,这 个 问 题 的 解 决 方 法 就 是 随 机 初 始 化 参 数 。 你 应 该 这 么 做 : 把
W
[
1
]
W^{[1]}
W[1]设 为
np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如 0.01,这样把它初始化为很小的随机数。然后𝑏没有这个对称的问题(叫做 symmetry breaking problem),所以可以把 b 初始化为 0,因为只要随机初始化W你就有不同的隐含单元计算不同的东西,因此不会有 symmetry breaking 问题了。相似的,对于
W
[
2
]
W^{[2]}
W[2]你可以随机初始化,
b
[
2
]
b^{[2]}
b[2]可以初始化为 0。

你也许会疑惑,这个常数从哪里来,为什么是 0.01,而不是 100 或者 1000。我们通常倾向于初始化为很小的随机数。因为如果你用 tanh 或者 sigmoid 激活函数,或者说只在输出层有一个 Sigmoid,如果(数值)波动太大,当你计算激活值时
z
[
1
]
=
W
[
1
]
x
+
b
[
1
]
z^{[1]} = W^{[1]}x + b^{[1]}
z[1]=W[1]x+b[1],
a
[
1
]
=
σ
(
z
[
1
]
)
=
g
[
1
]
(
z
[
1
]
)
a^{[1]} =σ(z^{[1]}) = g^{[1]}(z^{[1]})
a[1]=σ(z[1])=g[1](z[1])如果W很大,z就会很大。z的一些值a就会很大或者很小,因此这种情况下你很可能停在 tanh/sigmoid 函数的平坦的地方(见图 3.8.2),这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
回顾一下:如果w很大,那么你很可能最终停在(甚至在训练刚刚开始的时候)z很大的值,这会造成 tanh/Sigmoid 激活函数饱和在龟速的学习上,如果你没有 sigmoid/tanh 激活函数在你整个的神经网络里,就不成问题。但如果你做二分类并且你的输出单元是 Sigmoid函数,那么你不会想让初始参数太大,因此这就是为什么乘上 0.01 或者其他一些小数是合理的尝试。对于 w [ 2 ] w^{[2]} w[2]一样,就是 np.random.randn((1,2)),我猜会是乘以 0.01。
事实上有时有比 0.01 更好的常数,当你训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为 0.01 可能也可以。但当你训练一个非常非常深的神经网络,你可能会选择一个不同于的常数而不是 0.01。下一节课我们会讨论怎么并且何时去选择一个不同于 0.01 的常数,但是无论如何它通常都会是个相对小的数。
好了,这就是这周的视频。你现在已经知道如何建立一个一层的神经网络了,初始化参数,用前向传播预测,还有计算导数,结合反向传播用在梯度下降中。















 4485
4485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









