









【本章学习目的:学习完本章节要学会开发和基本的算法以及调试!!!调试的过程才能让自己的技术能力增长 而基础的算法和和基础的学习可以更好的理解底层】
五 数组 指针 函数 字符串 结构体
5.1 数组
5.1.1 数组的定义
数组是在内存中开辟一片连续存储的空间(是连续存储的空间),静态数组是由操作系统自己开辟的,同时也会自动回收。因为是连续的空间,所以咱们开辟数组时需要指定数组的大小。
比如 int a[5] 或者 int a[]={1,2,3,4,5}。
数组的定义方式:
数据类型 数组名[];
int a[3]; double a[5]; string a[12]; char a[8]; long a[4];
注意:字符数组的最后一位是’\0’ 作为结束符(\0 是默认c会自动补充,假如说 char a[3]={‘0’,‘1’};那么默认会补充。这里涉及一个strlen和sizeof的区别)
数组的初始化:
int a[5]={1,2,3,4,5}
int a[]={1,2,3,4,5};
注意:数组名代表数组的首地址,a[X] 的X代表数组中有x个元素,数组的下标是从0-x-1;
数组名代表首地址,所以要把数组a赋值给数组b不能直接b=a;
这样是不对的,因为a是首地址 b是数组b的首地址,会直接报错。
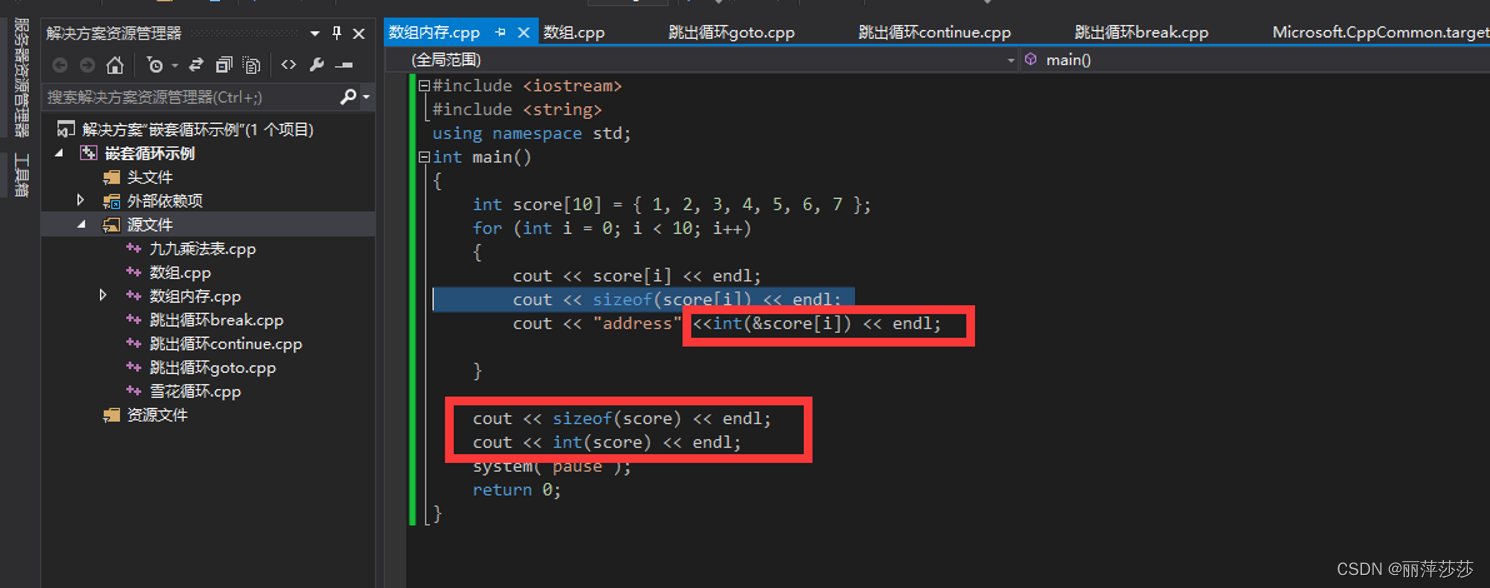
5.1.2. 数组的查找和倒置
数组的倒置:
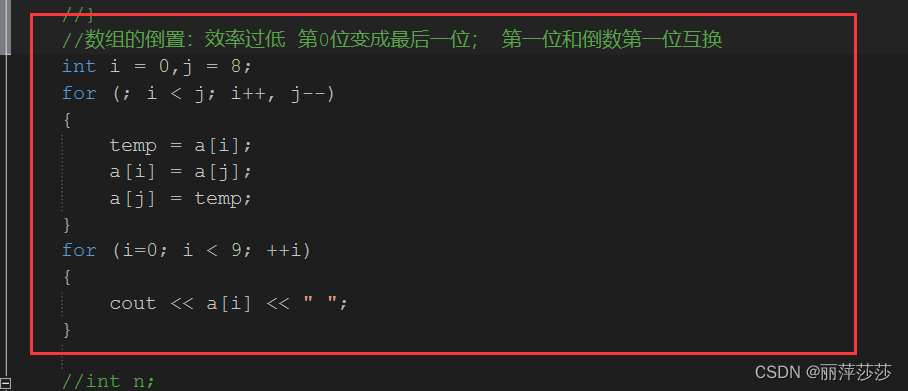
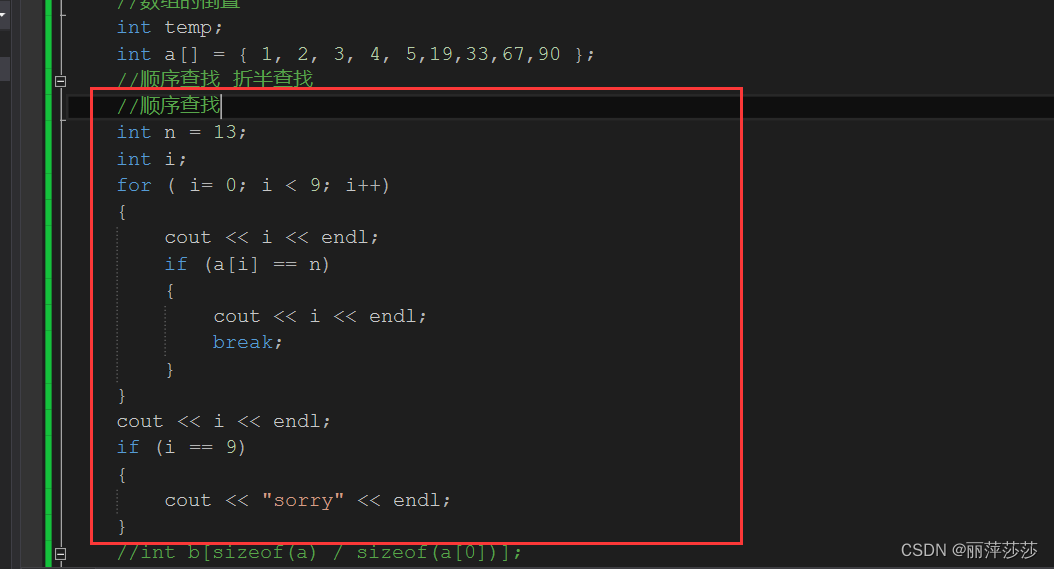
数组的查找:
顺序查找
折半查找
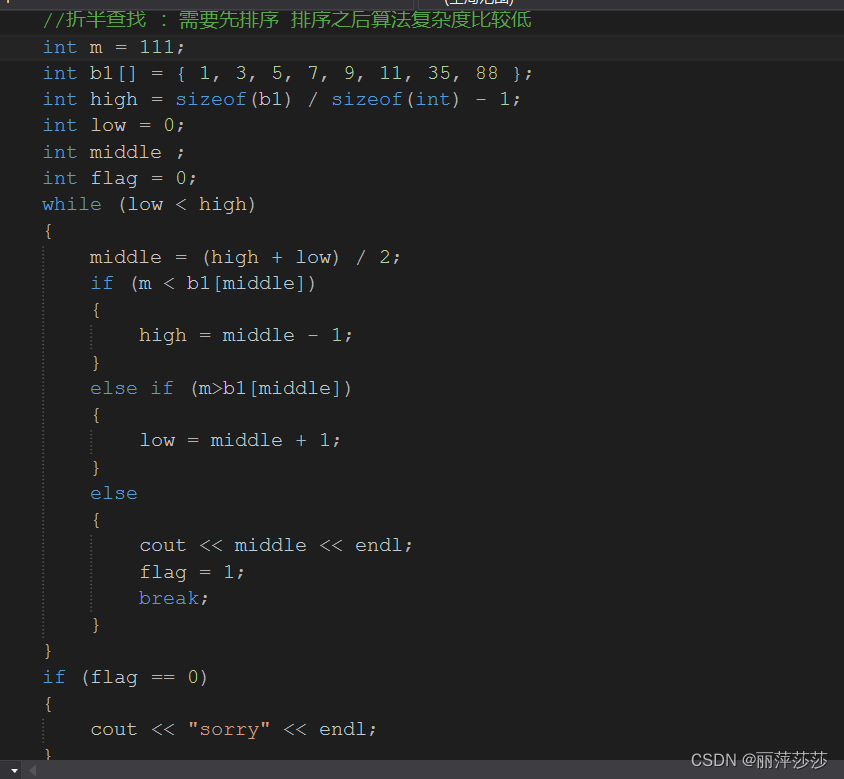
5.1.3 动态数组的开辟
我们在初始化数组的时候一般情况下都需要先指定数组的大小,因为数组是一片连续的区域,那如果我们本身存进去的数据要随着时间而扩大的话,数组直接指定大小是不满足我们的实际生产需求的。故而有了动态开辟数组
动态开辟数组C语言使用malloc; 释放使用free
C++使用new 和 delete[]。这里我们先详解下C语言的方式。
malloc free:
void * malloc(int length);malloc函数原型,指定开辟数组的大小,返回指向数组的指针。
free(void * p):释放指向数组的指针。
例如:
struct Stu
{
char name[20];//20
char sex;//1
long nYear;//4
float dScore;//4
};
int main()
{
//动态构造数组,用于存放学生的信息
//按照学生的信息的分数从高到低依次输出
int n = 0;
printf("please enter the number of students : ");
scanf_s("%d", &n);
//cout << "请输入学生的个数:" << endl;
//cin >> n;
void InputStudent(struct Stu *p, int len);
void BubbleSort(struct Stu *p,int len);
void OutPut(struct Stu *p,int len);
//请求分配: 分配多大的内存在堆,并且返回该内存的首地址
struct Stu *student = (struct Stu *)malloc(n*sizeof(*student));
//cout << sizeof(struct Stu) << endl;
//cout << n*sizeof(*student) << endl;
if (student == NULL)
{
//cout << "空间分配失败";
return 0;
}
system("pause");
return 0;
}
5.1.4 二维数组
**二维数组的定义方式:**我们一般采用第二种,第二种比较直观也比较好看

二维数组的内存地址计算:
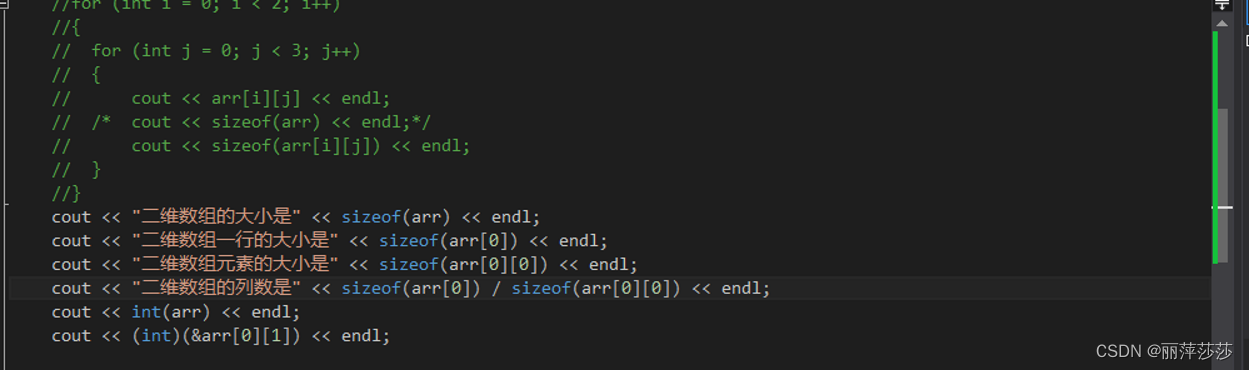 5.1.5 数组和指针
5.1.5 数组和指针
5.5.1. 一维数组和指针
一维数组的数组名代表了该数组的首地址:
int a[5]; a = &a[0] 数组名为数组的首地址,数组的首地址为数组的第一个元素也就是a[0] 的首地址,&表示取址符号。
通过指针可以访问我们的数组,代码如下:
#include "stdafx.h"
#include "targetver.h"
#include "iostream"
using namespace std;
int main()
{
int a[] = { 1, 2, 3, 4, 56, 7 };
//cout << a << &a[0] << endl;//a的值和&a[0]的值相同
int *p = a;//将首地址付给指针变量p *p代表该变量执行的变量值
cout << sizeof(p) << " " << p << endl;
//指针++来访问数组
for (int i = 0; i < sizeof(a) / sizeof(int); ++i)
{
cout << *p << endl;
p++;
}
cout << p;
//指针地址变动访问数组
p = a;
for (int i = 0; i < sizeof(a) / sizeof(int); ++i)
{
cout << *(p+i) << endl;
}
cout << p;
//直接和数组一样访问数组
p = a;
for (int i = 0; i < sizeof(a) / sizeof(int); ++i)
{
cout << p[i] << endl;
}
system("pause");
return 0;
}
5.5.2.二维数组和指针
二维数组是为了方便我们理解创造的二维数组,其实二维数组在计算机中本身就是以一维来存储的,我们可以看成是n行的n列数组的集合。那一般来说我们如何使用指针访问二维数组呢。主要有两种方式,一种是和访问一维数组类似的方式,定义指针变量p,只想数组的首元素,遍历访问。但是我们不是经常使用这种方式,这种方式使用起来比较麻烦。重点掌握定义数组指针,数组指针是一个指针,该指针变量指向某个数组。
重点理解:
int a[3][4];
二维数组数组名a表示二维数组的首地址= &a[0][0] = a[0]
a[0]是二维数组分解为3行一维数组的数组名
a[1]是a[1][0]-a[1][3] 这个一维数组的首地址
指针访问二维数组方式如下:
#include"stdafx.h"
#include"targetver.h"
#include "iostream"
using namespace std;
int main()
{
//用指向数组元素的指针变量输出二维数组各元素的值
int a[3][4] = { 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23 };
//指针p 指向整型变量
int *p = a[0];//p指向a的首地址
p = a[0];
p = &a[0][0];
p = *a;
for (int i = 0; i < 12; ++i,++p)
{
if (p != a[0] && (p - a[0]) % 4 == 0)
cout << "\n";
cout << *p << " ";
}
cout << "\n";
//指向由m个元素组成的一维数组的指针变量
int(*p1)[4];
p1 = a;
p1 = &a[0];
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
cout << *(*(p1 + i) + j) << " ";
if (j == 3)
{
cout << "\n";
}
}
}
//用指向数组的指针作函数参数
int *p3[4];
0行首地址和0行0列元素地址
cout << a << &a[0];
0行0列元素地址
cout << *a <<endl << *(a + 0)<<endl;
1行0列元素地址
cout << &a[1][0] << endl << *(a + 1) + 0 << endl << a[1] << endl;;
2行0列元素地址
cout << &a[2][0] << endl << *(a + 2) << endl << a[2] << endl;;
0行0列元素地址
cout << a << *a << a[0] << &a[0][0] << endl;
2行0列元素地址
cout << *(a + 2) << endl << a[2] << &a[2] <<endl << &a[2][0] << endl;
0行0列元素
cout << a[0][0] << endl << **a << endl << *a[0] << endl;
2行1列元素
//cout << a[2][1] << endl << *(*(a + 2) + 1) << endl;
system("pause");
return 0;
}
5.1.6 数组的排序算法
冒泡排序
//冒泡排序
//冒泡排序思想:每次沉底一个最大数,排序n*(n-1)
//冒泡排序时间复杂度:on2 空间复杂度 o1 稳定的排序算法
for(int i=0; i<len-1; i++)
{
for(int j =0; j<len-1-i; ++j)
{
if(a[j+1] < a[j])
{
int temp = a[j+1];
a[j+1] =a[j];
a[j]= temp;
}
}
}
插入排序
//2 插入排序
//插入排序思想:元素逐个添加到已经排序好的数组中去,同时要求,插入的元素必须在正确的位置,这样原来排序好的数组是仍然有序的。
//插入排序时间复杂度:on2 空间复杂度o1 稳定的排序算法
//比如 3 ,9,4,67,88,17
// 3 9
// 3 4 9
for (int i = 1; i < sizeof(a) / sizeof(int); ++i)
{
if (a[i] < a[i - 1])//如果比较小的话
{
temp = a[i];
j = i - 1;
while (j >= 0 && a[j] > temp)
{
a[j + 1] = a[j];
j--;
}
a[j + 1] = temp;
}
}
选择排序
//3 选择排序:
//选择排序思想:第一趟排序选出最小树,记住下标,存储到第一位,第二趟从i+1到n开始查找,记住最小数下标,存储到第二位
//第三趟排序找出最小数,记住下标放到第三位
//选择排序算法复杂度:on2 o1 不稳定算法
for(int i=0; i<len; ++i)
{
int index = i;
int temp;
for(int j = i+1; j<len; ++j)//5 7 8 5 4
{
if(a[j] < a[index])
{
index =j;
}
}
//交换a[index]和a[i]
int temp = a[j];
a[j] = a[index];
a[index] = temp;
}
快速排序
//4 快速排序:定义两个指针 一个指向low 一个指向high,定义一个哨兵key =a[low] //从小到大排序
//排序从右向左排序,如果key <= a[high],high--; 指导key大于a[high],A[LOW]=a[high],low++
//key >= a[low],low++; 直到key小于[low],a[high] = a[low],high--;
//递归循环排序:
//时间复杂度:0nlog2n 空间复杂度:olog2n 不稳定算法
void QuickSort(int a[], int low, int high)
{
int i = low;
int j = high;
int key = a[low];
if (low >= high)
return;
while (low < high)
{
while (low < high && key <= a[high])
{
high--;
}
if (key > a[high])
{
//交换数据 并且改为从left开始比较
a[low] = a[high];
++low;
}
while (low < high && key >= a[low])
{
++low;//向后寻找
}
if (key < a[low])
{
a[high] = a[low];
--high;
}
}
a[low] = key;
if (low > 1)
QuickSort(a, i, low - 1);
if (high < j-1)
QuickSort(a, high + 1, j);
}
=以上算法需要重点掌握,思想 实现方式 算法的复杂度 大家可以开启debug模式调试 查看寄存器的值 这样有助于理解奥!!!!! 算法很久没看可能会忘记 所以最好是隔断时间看看 这些都是比较基础的算法。先看看原理 ,自己复述出来 ,然后再根据原理写代码 。没有按照既定结果的话debug单步调试看看 ,哪里有问题。这边一定要掌握 !后面还有链表的排序也是这样的!!大家加油~~

5.2 指针
5.2.1 指针的定义
前面学习数组的时候我们已经简单知道了指针,现在我们具体来讲讲指针把。
首先什么是指针呢?指针有什么作用?
*指针是地址,指针定义 :数据类型 * 指针变量名。比如 int p;
**这里我们要知道p是指针,p里面存储的指针p的地址!*p表示指针p指向的变量,p是根据单元p的值找到的,p存储的是指针指向的变量的值!
在我们的操作系统中,所有的变量其实都是地址,这句话如何理解,意思是比如你定义int a,a其实就是地址的名称,地址可能0x340A;那通过指针我们可以直接操作地址,这在我们写代码的时候会非常的方便,当然由于这种可以直接访问地址的操作,也可能使得我们的代码非常危险。比如动态开辟数组没有释放指针就会造成内存泄漏。比如指针定义之后没有初始化或者在程序运行中已经为空,而我们没有判断是否为空指针的情况直接找指向指针的值,就会导致访问不可访问的内存而出错,因此在实际运用中我们要记得判断指针是否为空,减少这种bug!!!
5.2.1 指针的使用
1 最常用:通过指针访问数组
2 作为形参可以直接改变形参的值
void BubbleSort(struct Stu *p,int len)
{
float dtemp;
for (int i = 0; i < len; ++i)
{
for (int j = 0; j < len - i; j++)
{
if (p[j].dScore > p[j + 1].dScore)
{
dtemp = p[j].dScore;
p[j].dScore = p[j + 1].dScore;
p[j + 1].dScore = dtemp;
}
}
}
}
void OutPut(struct Stu *p,int len)
{
for (int i = 0; i < len; ++i)
{
printf("name:%s,sex:%c,year:%d,score:%.2f\n",p->name,p->sex,p->nYear,p->dScore);
p++;
}
}
void InputStudent(struct Stu *p, int len)
{
for (int i = 0; i < len; ++i)
{
printf("请输入第%d个学生的信息\n",i+1);
printf("name = %s", (p + i)->name);
scanf_s("%s",(p+i)->name);
}
}
2 关于指针所占的内存空间:在32位操作系统下,不管是什么类型的指针,都是占用4位指针;64的操作系统占用8个字节的内存
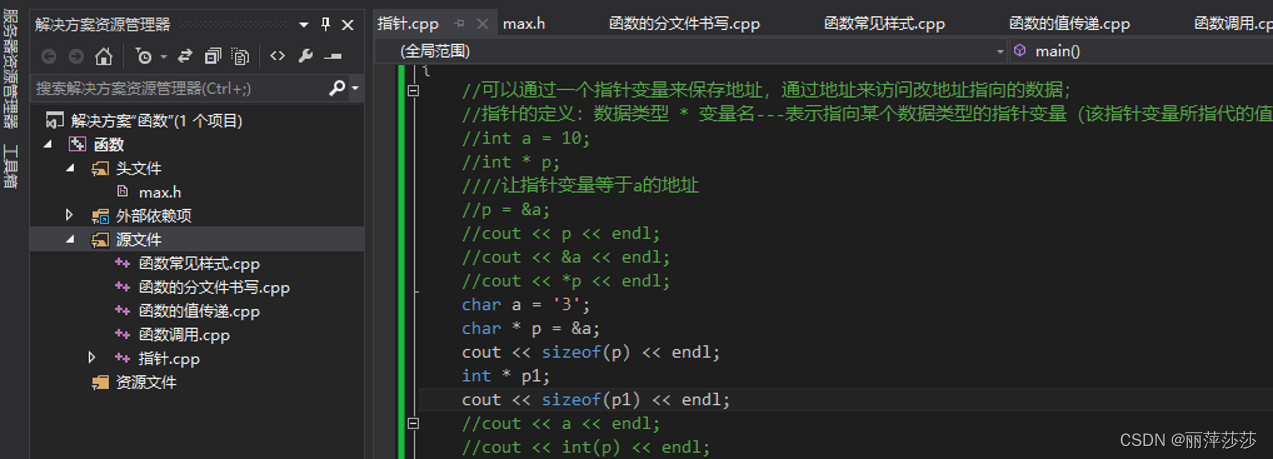
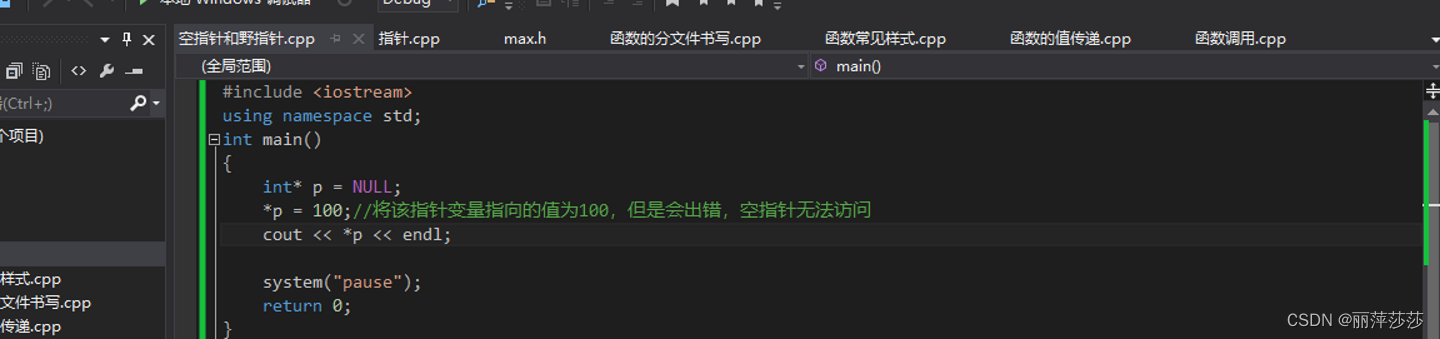
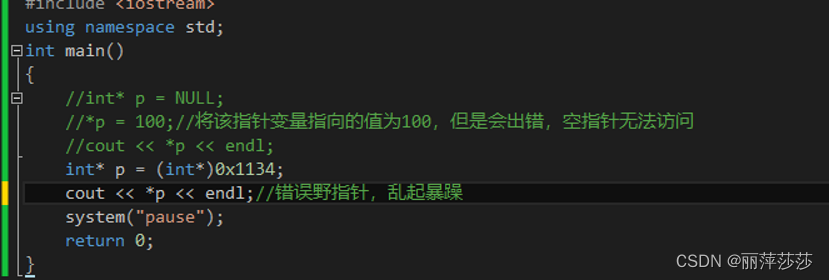
3 空指针和野指针:
空指针:指针变量指向内存中编号为0的指针----指向内存编号为0的指针变量;
用途: 初始化指针变量
!!!:空指针指向的内存无法访问(0-255)这块内存是系统所占用
5.2.2 数组指针和指针数组
数组指针:本质上是指针,定义方式是int (*p)[5]; 表示改指针指向一个存放了5个int型元素的数组的首地址,经常用于访问二维数组
指针数组:本质上是数组,定义方式是int *p[5],表示该数组存放了5个int型指针变量的元素!
5.2.3 函数指针和指针函数
函数指针:本质是指针,定义方式是int (*func)();表示该函数返回的是一个int型的指针的值。
例如:
int func(int x);
int (*p)(int x);
p = func; func函数的首地址赋值给函数指针p
(目前这部分比较少使用到,如果后续有使用到我会补充例子!!)
5.2.4 二维数组和二维指针
二维数组和二维指针可以看数组和指针那个章节!主要是要理解二维数组到底怎么排列的。为什么指针我们称之为行指针呢!!
5.2.5 常量指针 指针常量 常指针常量
常量指针:
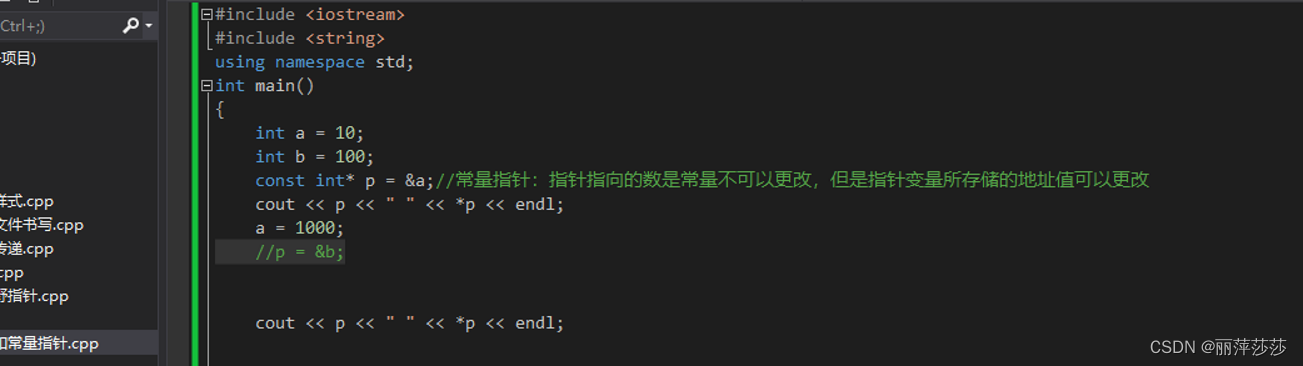
指针常量:

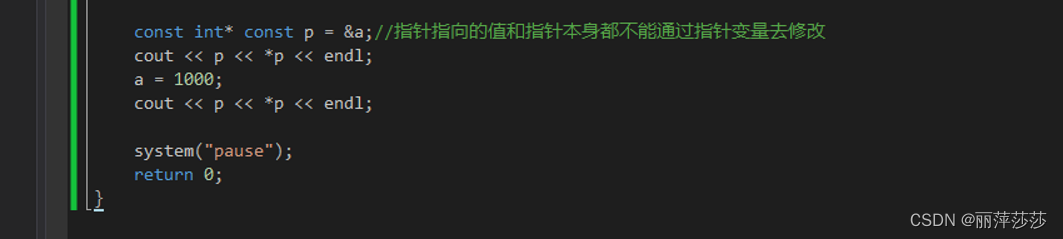
const修饰指针和常量:
5.3 函数
5.3.1 函数的定义
函数返回类型 函数名(数据类型 形参1,数据类型 形参2)
5.3.2 函数的使用
函数经常用于代码编程时,对相同逻辑封装成函数,减少代码冗余。
5.3.3 函数的参数传递!!!
5.3.3.1 值传递:不会改变实参的值
5.3.3.2 指针传递:能够改变实参的值(比较危险 但是好用)
指针变量所存放的是参数的地址,故而参数的值修改之后,改指针变量所指向的参数值也会随之修改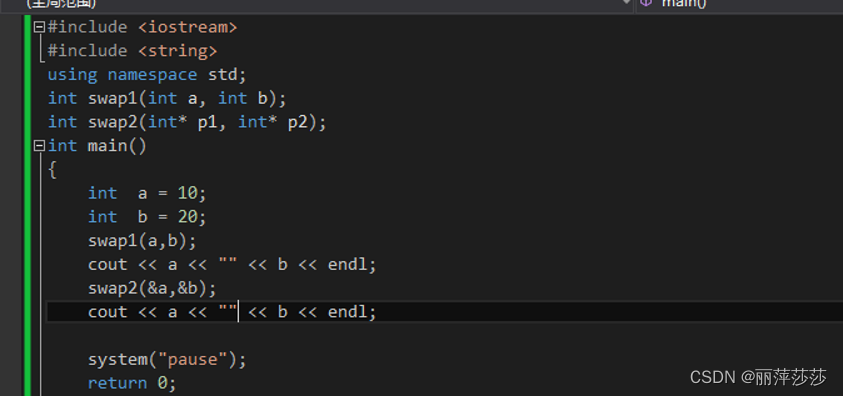
字符串本章不再叙述作为提纲了解
5.4 字符串
5.4.1 字符串的定义
5.4.2 字符串相关函数的使用和了解
5.5 结构体
5.5.1 结构体的定义
c中结构体定义比较死板,在c++中则使用起来非常灵活 格式也不会那么死板,这部分大家可以自己看标准,我认为语言是不断进化的,在编译器允许的基础上,我们根据自己的喜好来就行。
struct 结构体名{成员变量(数据类型+变量名)}
struct NODE
{
int data;
struct NODE * next;
};
5.5.2 结构体的使用(结构体操作符)
简单结构体
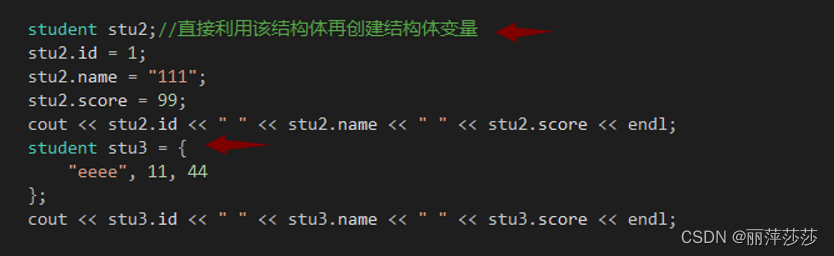
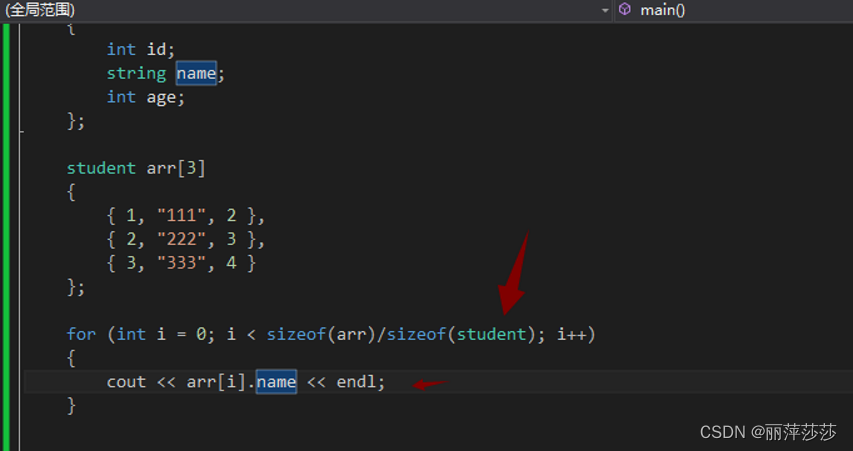
结构体数组
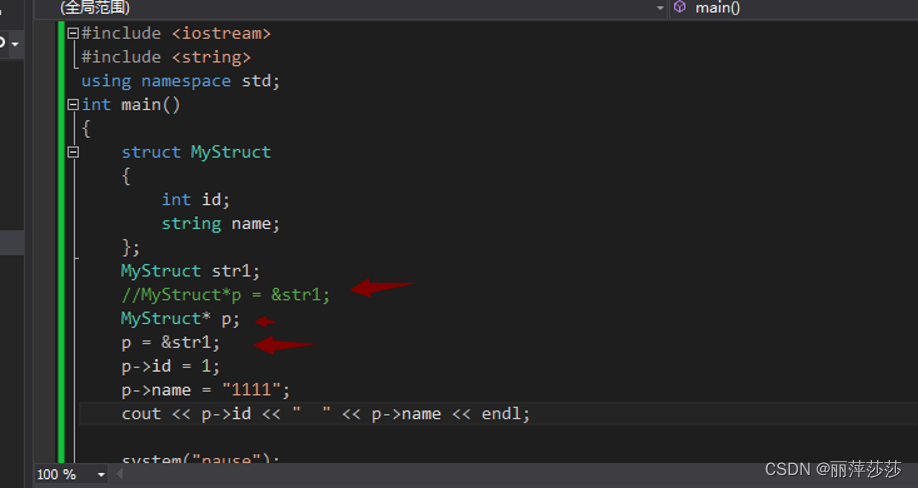
结构体指针
结构体作为参数传递
当结构体作为参数传递的时候有两种方式:
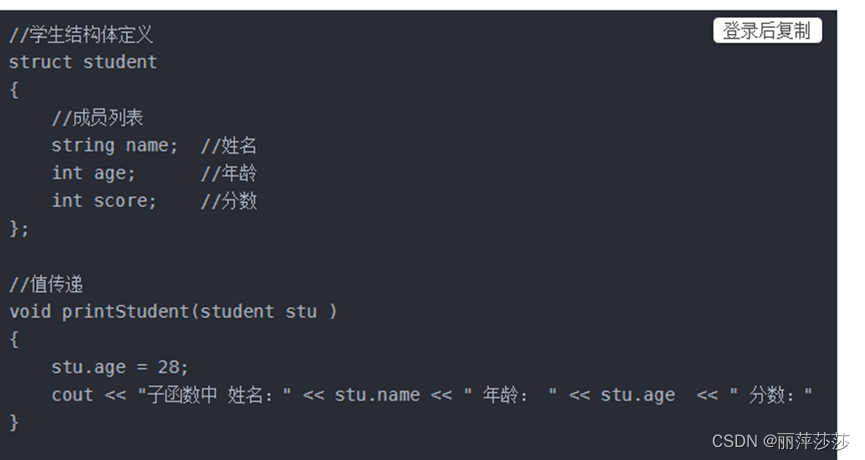
这边还要注意下操作符 结构体成员操作符是. 结构体指针操作符是->
1 值传递:值传递不修改实参数据
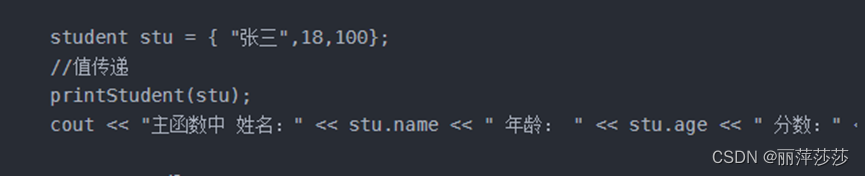
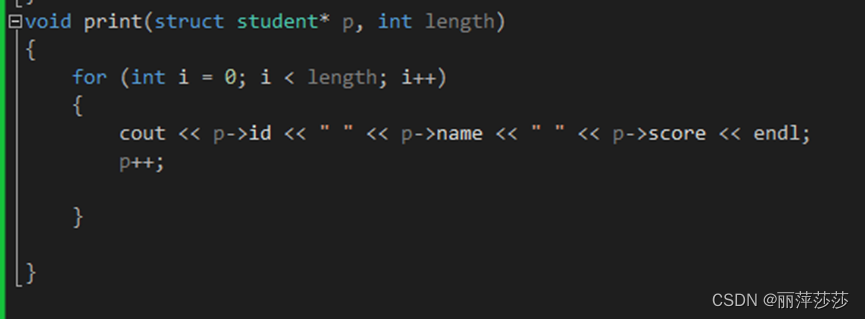
2 地址传递:地址传递修改实参数据
8 结构体中const的使用场景
作用:用const来防止误操作
尤其是用于函数传递的时候
Const student*p;-----防止操作的时候随意删改数据
9 结构体案例1:3个老师,5个学生,学生的成员变量为;
老师的成员变量为,输入老师和学生的值,打印输出;使用函数封装的方式实现
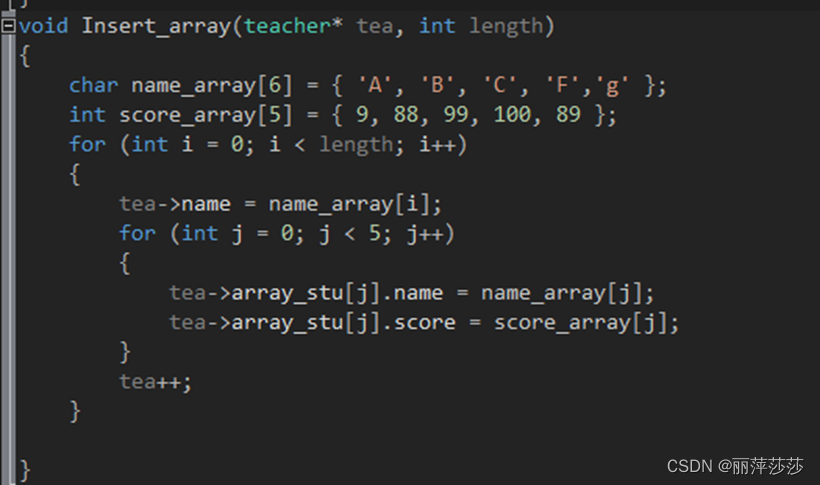
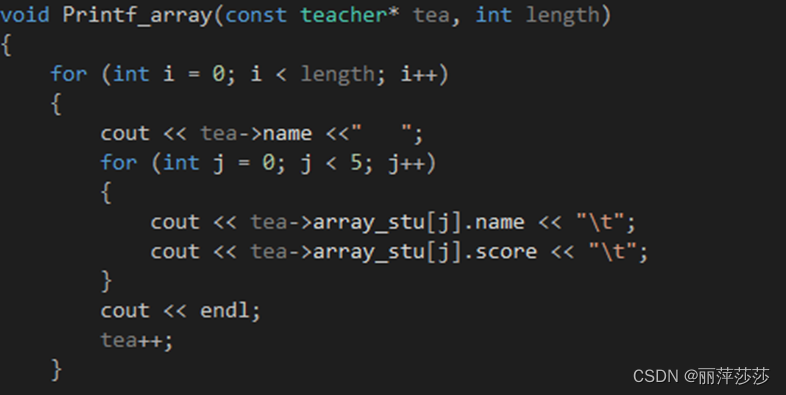
结构体还要注意求结构体数组大小的问题 对齐原则 位域操作符
六 链表
6.1 链表
为什么要学习链表,我们之前学习过数组,数组是连续开辟的空间,查找的效率非常高,但是其插入和删除的效率都比较低。而且由于是连续开辟的空间,在空间没有连续的情况下使用数组不是特别好的方式,会大幅度占用空间。
单链表的构造:链表有唯一一个头指针指向头节点,尾部有唯一一个尾节点,不指向任何的其他节点。中间的节点都有前驱节点和后驱节点。节点可以划分为指针域和数据域。指针域存放指针,指向后一个节点,数据域存放该节点的数据。如图:
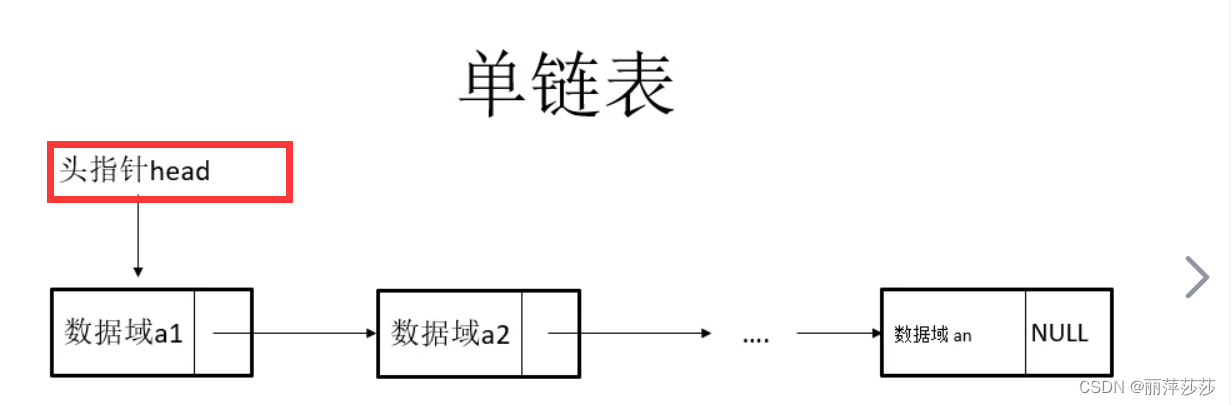
6.2 链表的分类
链表主要有单链表 双链表 单循环链表 全循环链表,在这里我们先学习简单的单链表。链表的数据结构相对来说比较复杂,学会了链表后面的链栈和链式队列的操作会变得非常简单。我们重点学习链表的原理以及链表的C实现和相关链表的增删改查!
这部分也非常重要奥!!
6.3 链表的构造和增删改查
6.3.1 链表的构造
struct NODE *CreateLink()
{
int len;
int i;
int val;
struct NODE * head = (struct NODE *)malloc(sizeof(*head));//开辟一个堆空间,空间大小为node结构体的大小,并返回该地址的首地址赋予指针head
//头节点
struct NODE * move = head;
head->next = NULL;
if (NULL == head)
{
printf("分配失败\n");
exit(-1);
}
printf("请输入需要生成的链表的节点数,len= ");
scanf_s("%d",&len);
for (int i = 0; i < len; ++i)//创建节点
{
struct NODE * fresh = (struct NODE *)malloc(sizeof(*fresh));//开辟一个堆空间存放新的结构体数组,并返回该节点的首地址
if (NULL == fresh)
{
printf("分配失败\n");
exit(-1);
}
printf("请输入第%d个节点的值,data= ",i+1);
scanf_s("%d", &val);
fresh->data = val;
//连接三部曲
move->next = fresh;
fresh->next = NULL;
move = fresh;
}
return head;
}
6.3.2 链表的输出
void OutputLikn(struct NODE * p)
{
//不能试图移动头指针
struct NODE * move = p;
if (p == NULL)
{
printf("delete already222222222 \n");
return;
}
while (move->next != NULL)
{
printf("%d\n", move->next->data);
move = move->next;
}
return;
}
6.3.3 链表的插入
void InsertLink(struct NODE * p)
{
int val = 0;
int val1 = 0;
printf("请输入在哪个数据后面插入该节点,data:");
scanf_s("%d", &val);
printf("请输入插入的数据,data:");
scanf_s("%d", &val1);
struct NODE * move = p;
while (move->next->data != val && move->next != NULL)
{
move = move->next;
}
if (move->next != NULL)
{
struct NODE * p1 = move->next->next;
struct NODE * p2 = (struct NODE *)malloc(sizeof*p2);
p2->data = val1;
move->next->next = p2;
p2->next = p1;
}
return;
}
6.3.4链表的删除
void DeleteLink(struct NODE * p)
{
int val;
printf("请输入想删除的数据:");
scanf_s("%d",&val);
getchar();
struct NODE * move = p;
while (move->next != NULL )
{
/* printf("1111111111111");*/
if (val == move->next->data)
{
//printf("222222222");
struct NODE * p1 = move->next;
move->next = p1->next;
free(p1);
p1 = NULL;
printf("delete already\n");
return;
}
//printf("33333333333");
move = move->next;
}
printf("nonononono\n");
return;
}
//删除链表
void DeleteAllLink(struct NODE * p)
{
//删除每一个节点
if (p == NULL)
{
printf("delete already \n");
return;
}
struct NODE * move = p;
while (p!= NULL)
{
move = p->next;
free(p);
p = NULL;
p = move;
}
if (p == NULL)
{
printf("delete already11111111\n");
return;
}
return;
}
6.3.5 链表的排序算法:
以下代码先别复制 先想想数组的排序原理 先自己慢慢写 然后通过debug查看 一次写不对也没有关系的!! 排序的过程可以分为交换数据和改变节点的指向!!(写法很多 选择自己喜欢的就行!!)
冒泡排序
void BubbleSort(struct NODE *head)
{
struct NODE * move1 = head;
struct NODE * move2 = head;
struct NODE * save = NULL;
while (move1->next->next!=NULL)
{
while (move2->next->next != NULL && save != move2)
{
if (move2->next->data > move2->next->next->data)
{
//交换数据
int temp = move2->next->next->data;
move2->next->next->data = move2->next->data;
move2->next->data = temp;
}
move2 = move2->next;
}
move1 = move1->next;
save = move2->next;
move2 = head;
}
}
插入排序
void InsertSort(struct NODE *head)
{
struct NODE * disorder = head->next->next;//无序部分
struct NODE * order = head->next;//有序部分
struct NODE * back = NULL;
struct NODE * front = head->next;
if (head == NULL)
{
printf("EXIT");
return;
}
while (disorder!=NULL)//插入排序:无序部分不为空
{
while (disorder != order)//比较和move2 有序部分的数据
{
if (disorder->data < order->data)//move2插入在move1之前
{
//交换位置(不是直接插入 要知道其前驱节点和后驱节点)
back = disorder->next;//disorder的后驱节点
disorder->next = order;//无序的下一个指针地址为order
order = disorder;//order的地址为disorder 位置互换
front->next = back;//
disorder = front;//
break;
}
order = order->next;
}
front = disorder;
disorder = disorder->next;
order = head->next;
}
return;
}
选择排序
void SelectSort(struct NODE *head)
{
struct NODE * move = head->next;
struct NODE * move2 = head->next->next;
while (move->next != NULL)
{
struct NODE * max = move;
while (move2 != NULL)
{
if (max->data < move2->data)
{
max = move2;
}
move2 = move2->next;
}
if (max != move)
{
int temp = max->data;
max->data = move->data;
move->data = temp;
}
move = move->next;
move2 = move->next;
}
}
七 栈
栈:链式栈 在链表的基础上只允许栈顶进行数据的插入和删除。可以通过top指针指向链栈的最高点
栈:先进后出
八 队列
队列:链式队列 队尾插入 队头删除 先进先出的结构
九 各种排序算法
9.1 算法的时间复杂度和空间复杂度
9.2 冒泡排序
9.3 选择排序
9.4 插入排序
9.5 快速排序
9.6 堆排序
以上排序算法在经过数组和链表的学习基本都会了把,不会的朋友们回去复习下 后面的数据结构会有更具体的解释和备注
十 文件的相关操作
10.1 文件
10.2 文件的输入和输出
先写到这里了!这些都是基础性的学习!后面会出C语言的进阶,本篇笔记只是个人的学习笔记,有一些基础和要注意的点,可以作为提纲和参考,但是不能完全替代书籍!!未来在工作中遇到的问题也会发出来!欢迎和大家一起交流呀~~~















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









