







注意力的种类有如下四种:
- 加法注意力, Bahdanau Attention
- 点乘注意力, Luong Attention
- 自注意力, Self-Attention
- 多头点乘注意力, Multi-Head Dot Product Attention(请转至Transformer模型)
1. Bahdanau Attention
Neural Machine Translation by Jointly Learning to Align and Translate, Bahdanau et al, ICLR 2015
总览
2015年发布的论文,首次提出注意力机制,也就是加法注意力,并将其应用在机器翻译领域。
当前工作的不足
目前NMT主流的方法是seq2seq方法,具体采用的是encoder-decoder模型。但是在编解码模型中编码得到的是固定长度的context vector,这是当前seq2seq的瓶颈。
本文提出联合学习对齐和翻译的方法:
- 对齐:在预测每一个target word的时候都去search源句子中一个部分
- 翻译:根据对齐的部分动态生成c,然后基于c和上一个target word生成当前的target word
模型
下图展示了在预测target word o t o_t ot时从源句子隐藏状态动态生成上下文向量的过程。
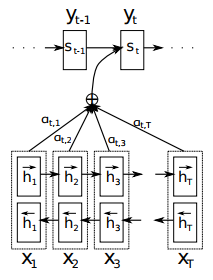
首先根据对齐模型 a a a,给每个源隐藏状态 h j h_j hj生成一个权重系数 e t j e_{tj} etj:
e t j = a ( s t − 1 , h j ) e_{tj} = a(s_{t-1}, h_j) etj=a(st−1,hj)
然后将所有权重系数进行softmax归一化得到各个源隐藏状态的注意力权重:
a t j = e x p ( e t j ) ∑ k = 1 T x e x p ( e t k ) a_{tj} = \frac{exp(e_{tj})}{\sum_{k=1}^{T_x}exp(e_{tk})} atj=∑k=1Txexp(etk)exp(etj)
计算注意力权重和各个源隐藏状态的加权和,得到预测 o t o_t ot的注意力向量:
c t = ∑ j = 1 T x a t j h j c_t = \sum_{j=1}^{T_x}a_{tj}h_j ct=j=1∑Txatjhj
然后根据注意力向量进行预测:
s t = f ( s t − 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1468
1468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









