







原文链接:https://www.jiqizhixin.com/articles/2020-01-31-7
对话系统一般分为两种:任务型对话系统和闲聊型对话系统。本文主要讨论前者。
任务型对话系统,也称目标导向型对话系统,多用于垂直领域业务助理系统,如微软小娜、百度度秘、阿里小蜜等。这类系统具有明确要完成的任务目标,如订餐、订票等。
任务型对话的架构
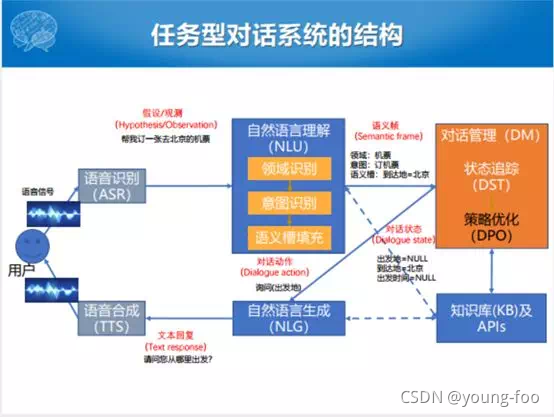
框架主要包含如下几个模块:
- ASR:输入为语音,输出为文字;
- TTS:输入为文字,输出为语音;
- 自然语言理解模块(NLU):输入为文字,输出为语义帧(包含领域、意图、语义槽);
- 对话管理模块(DM):输入为语义帧,输出为对话动作(如询问出发地);包含状态追踪和策略优化两个部分;
- 自然语言生成(NLG):输入为对话动作,输出为自然语言形式的文本;
- 知识库及APIs:在语言生成的过程中会调用知识库和一些APIs,比如一些查天气和地理位置的APIs,这些都包含在任务型对话的资源里
对话管理
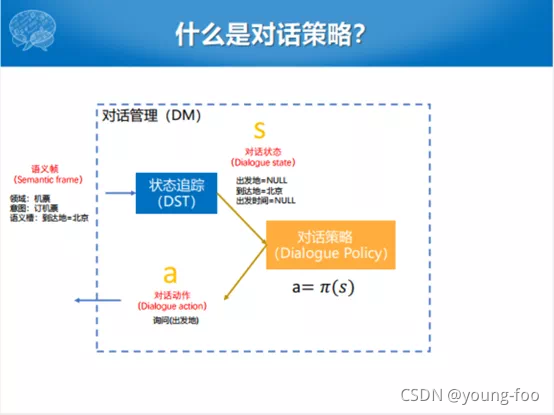
对话策略以对话状态为输入,通过一个 π \pi π函数来产生对话动作。由于对话状态集合和对话动作集合都是有限的,所以可以在集中进行枚举。
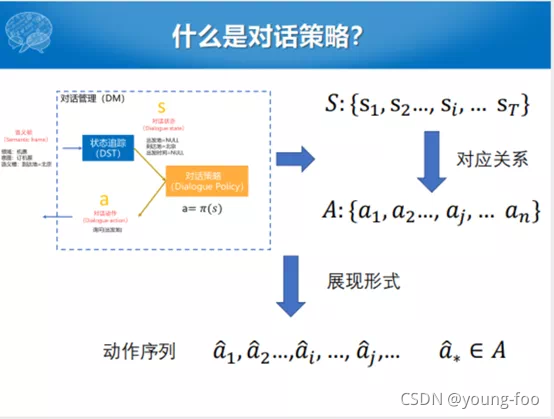
也就是说,对话策略模型就是根据对话状态序列生成对话动作序列。
对话策略方法论
1 基于规则的对话策略
对话策略最简单的方法论就是规则。如果用户是模糊查询,包含不确定性,就去问用户。如果不模糊,就生成对话动作去处理,每处理一块就生成一个对话状态的维度和特征。最后,判断是否需要回退到系统,如果需要就生成一个系统的回复,并更新对话历史和对话状态,否则不需要就回退到最开始的地方,采用一种澄清的方式让用户确认输入。如下图所示:
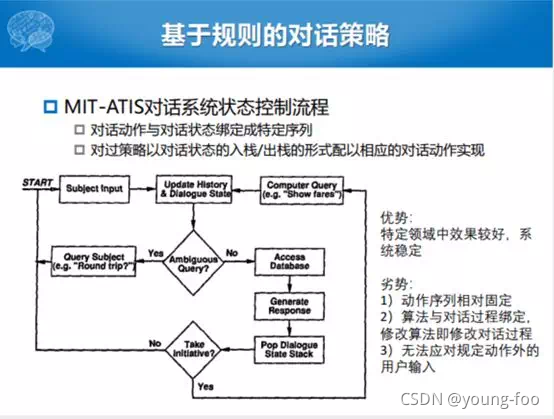
可以看到整个的方式其实就是一个比较偏向于规则的对话控制流程。在特定的领域或者特定比较小的任务上面,效果比较好。而且系统比较稳定,规定了这样的流程,规定了状态的转移的过程,就做的比较好;劣势也比较明显,动作状态序列都是固定的。算法与对话过程绑定,修改算法即修改对话过程。然后必须规规矩矩地按照系统的提示回答问题,否则流程就无法响应我们的需求。
2 基于有限状态自动机的对话策略
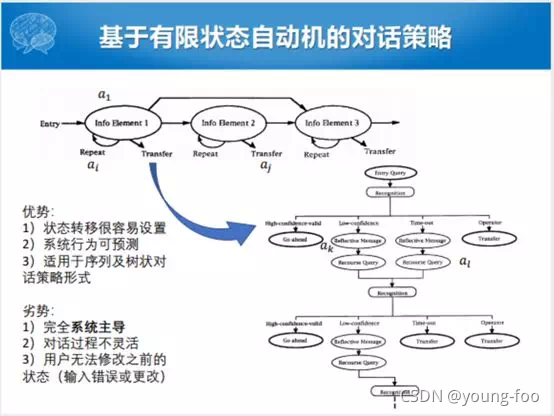
整个过程就是把对话和对话状态之间的转移过程看成有限状态自动机,可以转换成一个树形结构。这种有穷状态自动机有什么好处呢?状态转移很容易设置,有状态转型的图模型,就转成树形的结构。整个系统是可预测的,适应用树状的策略决策模式。劣势也是比较显而易见的,跟ATIS没有特别大的区别,完全是系统主导的,人要配合系统,对话的状态不是特别灵活,用户没有回退的机制。
3 基于表格的对话策略

用表格的形式表示对话的信息。整个过程有一个好处,我们人和机器可以混合主导,我们可以问机器一些问题,机器在这个过程当中也会问人的问题。不断地维护、更新表格的信息。表格上的信息有一个好处,我们可以更新。假如说这一轮说错了,下一轮还可以更新出来,这个更新的就在条目上。首先是混合主导,再就是容错性比较好且可更新。劣势是整个过程需要一个预设的脚本,就像我们说的系统生成的话都是预设的。根据什么样的上半句,拼接后半句,也不够灵活。
4 基于脚本的对话策略

MIT的Galaxy2是通过脚本流控制的,表格的形式没有一个明确的结构的过程,是通过不断地更新的过程,最终找到上面还有什么信息,缺什么信息,更新了什么信息,最后给你什么信息。但是这个Galaxy2有一个明显的自顶向下的规划结构,把这个大的Domain意图当成server,然后把Domain下面的一些意图当成Program。对每一个下面的这些语义槽当成更下层的规则。最后针对每一个槽或者针对每一个意图规定了一些若干个操作,比如有输入操作,有检索操作,有存储操作,有输出操作。一个脚本化或者流化的对话控制就是这样一个过程。我们看每一个节点都是对话的动作,但是这种对话动作序列的过程不是自动化生成的过程,而是由脚本控制的。这个也是一样的,下边四个变量,rule是什么样的,Input、output怎么实现的。
- 优势:任务扩展方便。多层的结构有点像现在的层次化或者是Domain到意图再到槽的自顶向下的构架,逻辑比较清晰,任务扩展相对方便一些。
- 劣势:这些规则都是手工定义的,对话流控制需要预设,也没有可学习的过程。

5 基于规划的对话策略
Wasson在1990年的时候给规划进行了一个定义,通过创建一个动作序列来实现某个目标的求解方法,并尝试预测执行该规划的效果。创建一个动作序列就是人机对话中的若干问题和若干回复,最终实现的目标是帮人完成相应的任务,后面的人就想能不能通过规划的方法来做对话策略的学习,也就是后面的基于规划的方法来求解对话策略学习的过程。

规划分三种:一种是固定的、静态的规划。比如,我们知道已有的数据里面,动作的序列是什么样的,就一条一条的把动作序列写出来,相对来说这种就比较的简单。当然如果写的规划库的数量足够多的话,其实鲁棒性还行;另一种是动态的规划。给定这样一个输入的序列,希望是一个整体的考虑,是建模联合分布,但是实际的过程中,我们其实可以进行Markov的假设,动态规划的过程就是给定若干个前续的动作序列,预测后续的动作序列是什么样的。这个过程就是通过规划的方式进行进行求解对话的过程;初次之外还有基于层次化的规划。
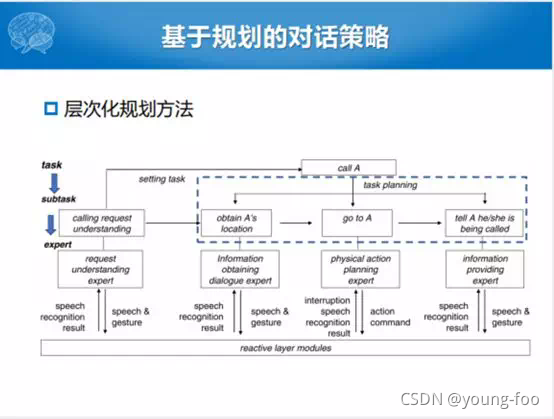
这个可以看成是基于层次化的对话策略学习的,在规划版本上的扩展。把这个任务自顶向下做一个分解,这个里面涉及到了一个事儿,我要告诉有一个A同学,在寝室楼下阿姨这里来了一个电话,正好A的同寝的人来了,阿姨就说你告诉A同学说有电话找他。这个B同学就要做几件事情,第一件事情要知道A到底是在寝室,在洗澡间还是在厕所。知道A的位置之后就要走到A这块,说你有一个电话在楼下找你,就把这样整个任务分成了三个子任务。总体来说,这种层次化的方法,一方面有一个比较清晰脉络的逻辑。整个规划的方法从上层大的任务分解到子任务,子任务分解到操作,每一个都有相应的属性,跟之前的层次化的方法特别的像。这样的方法还是存在一定的问题,首先对系统的错误比较敏感,鲁棒性比较差。对话策略清晰归清晰,但是相对固定,灵活性不够。第三是策略和任务绑定,很难在任务间迁移,策略决策过程是和任务和领域是强相关的。
6 基于概率的对话管理模型
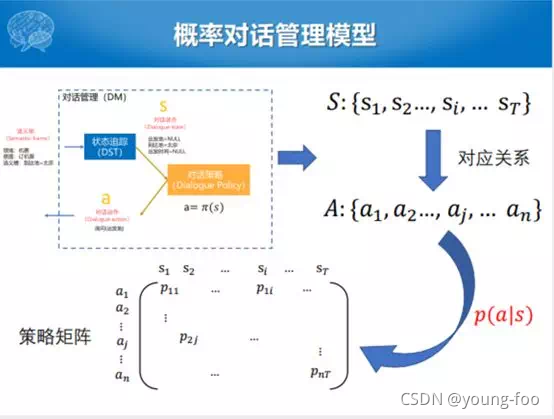
最简单的一种方式,或者能够比较自然地应用这种策略矩阵求解概率化的方式就是强化学习。强化学习的框架也比较简单,主要有对话的Agent,这个里面有对话状态跟踪和对话学习两块。这个里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









