







Netflix数据集包含了1999.12.31-2005.12.31期间匿名客户提供的超过一亿部电影平级。这个数据集大约给出了480189个用户和17770部电影评级。数据集中的详细信息如下图所示:
 该数据集包含电影信息、training set(训练集)、probe set(探测集)和qualifying set(评估集)组成(电影信息没有在上图中显示出来)。qualifying set(评估集)又被分为Quiz(测验集)和Test(测试集)。其中,training set的评分数量为100480507。probe set是training set的子集,包含1408395个评分。Netflix大赛的目标是预测qualifying set,并且在Quiz上获得至少0.8563的RMSE值。当参赛者提交Quiz的预测分数时,Netflix公司会将其RMSE值公布在排行榜上。但是,在test中得分最高的人将是该奖项的最终获得者,而test的RMSE值从未被公开过,这样做的目的是为了参赛者通过重复提交结果来了解Quiz数据集(这也是为什么将qualifying set分为两部分的原因)。
该数据集包含电影信息、training set(训练集)、probe set(探测集)和qualifying set(评估集)组成(电影信息没有在上图中显示出来)。qualifying set(评估集)又被分为Quiz(测验集)和Test(测试集)。其中,training set的评分数量为100480507。probe set是training set的子集,包含1408395个评分。Netflix大赛的目标是预测qualifying set,并且在Quiz上获得至少0.8563的RMSE值。当参赛者提交Quiz的预测分数时,Netflix公司会将其RMSE值公布在排行榜上。但是,在test中得分最高的人将是该奖项的最终获得者,而test的RMSE值从未被公开过,这样做的目的是为了参赛者通过重复提交结果来了解Quiz数据集(这也是为什么将qualifying set分为两部分的原因)。
探测集的采样与评估集的分布几乎是相同,但探测集与训练集的采样不同。
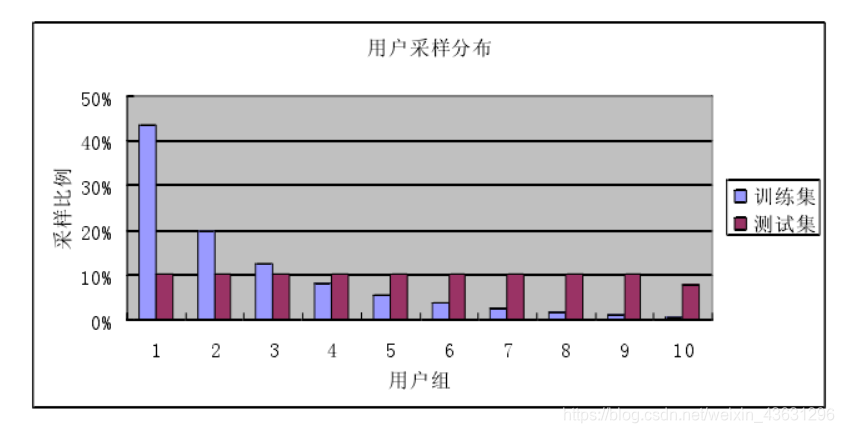
差异1:用户采样;训练集中的用户分布是不均匀的,少数用户非常活跃,10%的最活跃用户的评分占据了测试集评分点的百分之43.6%,而测试集的用户分布是均匀的,几乎所有用户被测试的概率相同,除极少数不活跃的用户,见下图:
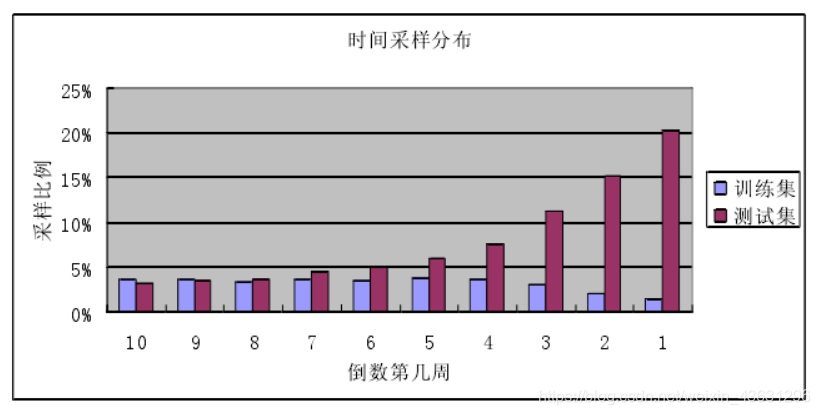
差异2:时间采样;探测集的数据点采样相比于训练集更集中于离现在较近的时刻,测试集中最后一周的评分点占了 20.4%,而训练集中最后一周的评分点仅占了1.5%。见下图:
1.电影信息
电影信息采用以下格式:

Movie ID,Year Of Release,标题
- Movie ID与实际的Netflix影片ID或IMDB影片ID不对应。
- Year Of Release的范围可以从1890年到2005年,可能对应于相应DVD的发行,不一定是它的剧场版本。
- 标题是Netflix电影标题,可能与其他网站上使用的标题不对应,标题是英文的。
2.training set(训练集)
“training_set.tar”是包含17770个文件的目录,文件中的每个后续行对应于客户的评级及其日期,格式如下:

电影ID:客户ID,等级,日期
- MovieID的顺序范围为1到17770。
- CustomerID范围从1到2649429。 有480189位用户。
- 评级为1到5的五星级(整数)。
- 日期的格式为YYYY-MM-DD。
3.probe set(探测集)
探测集包含指示电影ID的行,后跟冒号,然后是客户ID。格式如下:

MovieID1:
CustomerID11
CustomerID12
…
MovieID2:
CustomerID21
CustomerID22
4.qualifying_data(测试集)
Netflix奖的测试集包含在文本文件中“qualifying.txt”。它由指示电影ID的行,后跟冒号,然后是客户ID和评级日期组成。格式如下:

MovieID1:
CustomerID11,Date11
CustomerID12,Date12
…
MovieID2:
CustomerID21,Date21
CustomerID22,Date22
参赛者需根据训练集中的信息来预测客户在测试集中为电影提供的所有评级。提交的预测文件的格式遵循电影ID、客户ID和日期顺序
如果测试集看起来像:
111:
3245,2005-12-19
5666,2005-12-23
6789,2005-03-14
225:
1234,2005-05-26
3456,2005-11-07
那么预测文件应该类似于:
111:
3.0
3.4
4
225:
1.0
2.0
数据集下载链接:
https://pan.baidu.com/s/1bJjvmvMouoMBZE7ZVRHAbg 提取码: spie
数据集下载链接: https://pan.baidu.com/s/1bJjvmvMouoMBZE7ZVRHAbg 提取码: spie

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









