




 本文介绍了PyTorch中简单Seq2Seq模型的实现,包括模型结构、数据处理、网络创建、训练过程和测试结果。Seq2Seq模型常用于机器翻译、文本生成等NLP任务,其核心是Encoder和Decoder之间的状态向量传递。
本文介绍了PyTorch中简单Seq2Seq模型的实现,包括模型结构、数据处理、网络创建、训练过程和测试结果。Seq2Seq模型常用于机器翻译、文本生成等NLP任务,其核心是Encoder和Decoder之间的状态向量传递。
任务描述:pytorch实现简单seq2seq模型
一、什么是Seq2Seq
所谓Seq2Seq(Sequence to Sequence), 就是一种能够根据给定的序列,通过特定的方法生成另一个序列的方法。最早由《Sequence to Sequence Learning with Neural Networks》等提出,用于解决机器翻译中输入和输出不等长的问题(比如同一句话中英文的长度不相同)。随着NLP领域的发展,Seq2Seq技术还广泛应用到了聊天机器人、文本摘要自动生成、图片描述自动生成、机器写诗歌、代码补全等任务中,成为NLP中最重要的思想之一。其基本结构如下:
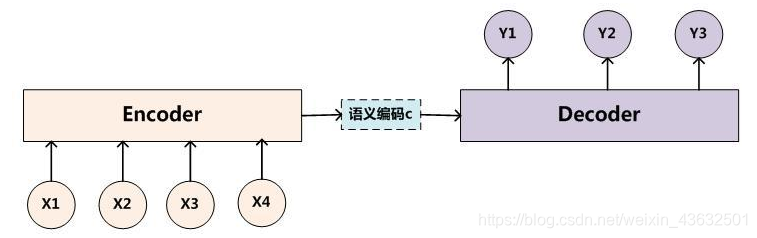
如图所示,最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量C,Encoder通过学习输入,将其编码成一个固定大小的状态向量c,继而将c传给Decoder,Decoder再通过对状态向量c的学习来进行输出。
二、数据
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
本文只是展示seq2seq的基本原理,所使用数据较为简单,目的是通过学习,当输入第一个单词时,网络经过计算可以得到第二单词(类似于翻译的思想)。
三、完整代码
1. 导入需要的库
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
2. 创建字典
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
// S: 在单词前加'S'
// E: 在单词后加'E'
// P: 当单词长度小于step长时,在后面补上'P'
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
num_dict = {
n:i for i, n in enumerate(char_arr)}
3. 网络参数
// n_class=29, batch_size=6
n_step = 5
n_hidden = 128
n_class = len(num_dict)
batch_size = len(seq_data)
4. 准备数据
def make_batch(seq_data):
input_batch, output_batch, target_batch = [] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3906
3906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









