







项目场景:
目前粗糙的多行文本已经构建好,现在要做的事情是如何将这些非结构的文本,转换成命名体识别模型可以读取的结构化标签文本。为此非结构化文本形式是图一所示(这是之前两步的所得结果),目标数据集为图二所示。那么在这一步怎么整合成数据集将成为关键。

图一:非结构化文本
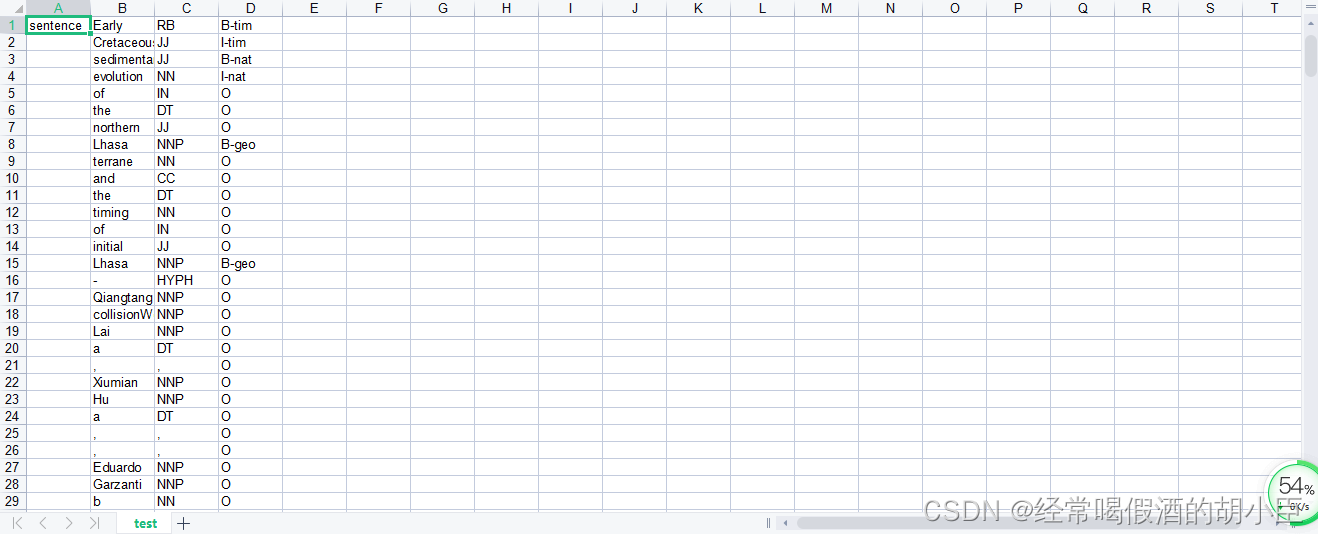
图二:目标结构化数据
单非结构文本转为单数据集
首先我我会将每一篇文章所得出的Txt(图一)放到一个文件夹中统一操作,标签分为三类B,I,O。B代表所需关键词开始,I所需关键词中间,O代表非关键词,而且默认为只能B开头加上I结尾,或者单个就一个B无I,但不能出现O后面出现I这种现象。为此,只要知道了这样规定的规定,按照一定的格式,写入表格就好。这里我是写入XLS当全部完成时转成CSV,另一个原因是XLS包,用法比CSV多,我更熟悉一点。为此这里将每一篇图一内容,全部转换后对应的图二内容。这里我也是偷懒用来standfordcorenlp的包来写词性,那这里又有一个疑问,为什么整体步骤第二步用的是NLTK新闻的包来写词性,为什么这就换了呢,其实只是很简单的原因,想做的复杂一点,也可以用NLTK来代替,我当时想着也是,如果都是一个标准,都错就是没错,那就是没错的,为此我才心安理得用了standfordcorenlp,代码如下:
import re
import xlwt
from stanfordcorenlp import StanfordCoreNLP
import os
osfile = []
dir = r"F:\pythonbert\demo\untitled1\extract\extracttxt"
for root, dirs, files in os.walk(dir):
for file in files:
if file != 'extract.py' and file != '__init__.py' and file !='split.py' and file !='Label.py' and file !='CSV.py':
osfile.append(file)
for index in range(len(osfile)):
nlp = StanfordCoreNLP('E:\stanford\stanford-corenlp-latest\stanford-corenlp-full-2021-01-09', lang='en')
sentence = []
key = []
substance = []
time = []
location =[]
Dict = []
k = 0
num = 0
# 分字典存储
with open(osfile[index], "r", encoding="utf-8") as f:
lines = f.readlines()
# 去除换行符
result = ([x.strip 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











