






项目场景:
目前有个需求是根据一段内容生成文本简报,简报分为,简报标题,简报摘要,简报内容和生成的建议。目前我只将技术调通了,并没有用领域数据输入,所有简报的效果我也不太清楚。技术方案和技术思路已经成熟。
摘要生成
目前我是通同GTP-2模型来生成摘要,因为有板子所以将GTP-2的参数条大,得到的效果还算可以。原github项目传送门,原作者代码没有毛病开袋即食,不需要改,并且有详细的备注,我只将改动部分列举,也作为学习点。
config.json部分
原配置参数n_layer:6和n_positions: 512,我这将n_layer设置为10层,n_positions为1024。
{
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_layer": 10,
"n_positions": 1024,
"vocab_size": 13317
}
train.py部分
我依旧的炼丹微调,扩大了epcohs和batch_size,缩小了学习率。最终得到checkpoint-279600,百度网盘:链接:https://pan.baidu.com/s/1UPy5i-hRXQL0lxUB9Sueyg
提取码:78x2
def set_args():
"""设置训练模型所需参数"""
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0', type=str, help='设置训练或测试时使用的显卡')
parser.add_argument('--config_path', default='./config/config.json', type=str, help='模型参数配置信息')
parser.add_argument('--vocab_path', default='./vocab/vocab.txt', type=str, help='词表,该词表为小词表,并增加了一些新的标记')
parser.add_argument('--train_file_path', default='./data_dir/train_data.json', type=str, help='新闻标题生成的训练数据')
parser.add_argument('--test_file_path', default='./data_dir/test_data.json', type=str, help='新闻标题生成的测试数据')
parser.add_argument('--pretrained_model_path', default=None, type=str, help='预训练的GPT2模型的路径')
parser.add_argument('--data_dir', default='./data_dir', type=str, help='生成缓存数据的存放路径')
parser.add_argument('--num_train_epochs', default=40, type=int, help='模型训练的轮数')
parser.add_argument('--train_batch_size', default=64, type=int, help='训练时每个batch的大小')
parser.add_argument('--test_batch_size', default=8, type=int, help='测试时每个batch的大小')
parser.add_argument('--learning_rate', default=1e-4, type=float, help='模型训练时的学习率')
parser.add_argument('--warmup_proportion', default=0.1, type=float, help='warm up概率,即训练总步长的百分之多少,进行warm up')
parser.add_argument('--adam_epsilon', default=1e-8, type=float, help='Adam优化器的epsilon值')
parser.add_argument('--logging_steps', default=20, type=int, help='保存训练日志的步数')
parser.add_argument('--eval_steps', default=4000, type=int, help='训练时,多少步进行一次测试')
parser.add_argument('--gradient_accumulation_steps', default=4, type=int, help='梯度积累')
parser.add_argument('--max_grad_norm', default=1.0, type=float, help='')
parser.add_argument('--output_dir', default='output_dir/', type=str, help='模型输出路径')
parser.add_argument('--seed', type=int, default=2020, help='随机种子')
parser.add_argument('--max_len', type=int, default=512, help='输入模型的最大长度,要比config中n_ctx小')
parser.add_argument('--title_max_len', type=int, default=32, help='生成标题的最大长度,要比max_len小')
return parser.parse_args()
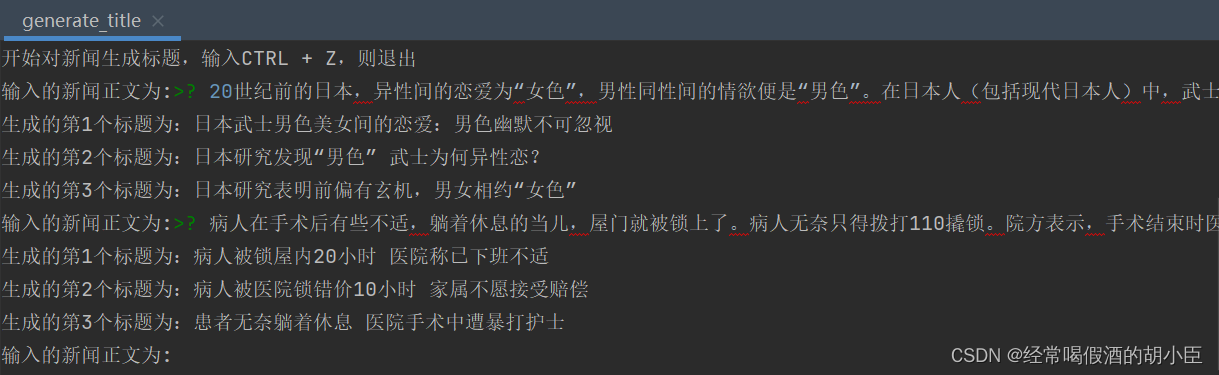
演示结果:
感觉还可以,之后之前加一个文本分类做,用垂直领域训练,感觉会好些。
自我学习github地址:https://github.com/zhichen-roger/GTP-2_titleGeneration.git



















 5481
5481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











