







普通的交叉熵函数
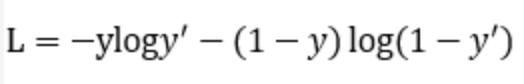
例如:
二分类的交叉熵
| 0 | 1 |
|---|---|
| 0.3 | 0.7 |
loss=-log0.7
Focal Loss
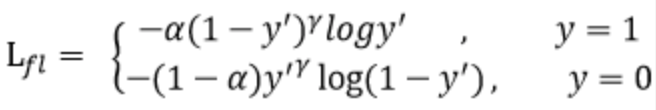
相较于标准的交叉熵函数,简单来说就是focal loss函数总共解决了两个方面的问题
- 样本的类别不均衡,比如某个标签的种类数量特别多,而某个标签的数量又特别少。
通过设定a的值来控制正负样本对总的loss的共享权重,对于数目多的样本我们分配小的权重。
例如:数据集一共3000条数据,标签为0的之后300条,标签为1的有2700条,二者相差很多,属于类别不均衡。那么我们给予他们一个权重,平衡两者之间对于loss的贡献。
- 难易样本不均衡,使得难分类的样本对损失的贡献程度更大一些
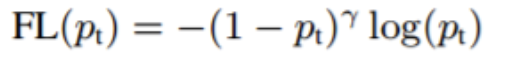
例如:
| 0 | 1 |
|---|---|
| 0.3 | 0.7 |
| 0.9 | 0.1 |
对于类别均为1的两条样本来讲
loss=-0.3^xlog0.7
loss=-0.9^xlog0.1
对于两条样本而言,第一个样本属于易分类的样本,第二个样本就属于难分类的样本,我们要增大难分类样本对总损失的贡献,减小易分类样本对于总损失的贡献。这样一来,就是的我们更关注于分类更为困难的样本。
参考
TensorFlow 实现多类别分类的 focal loss
Focal Loss理论及PyTorch实现
Pytorch 实现focal_loss 多类别和二分类示例















 2783
2783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









