







模型
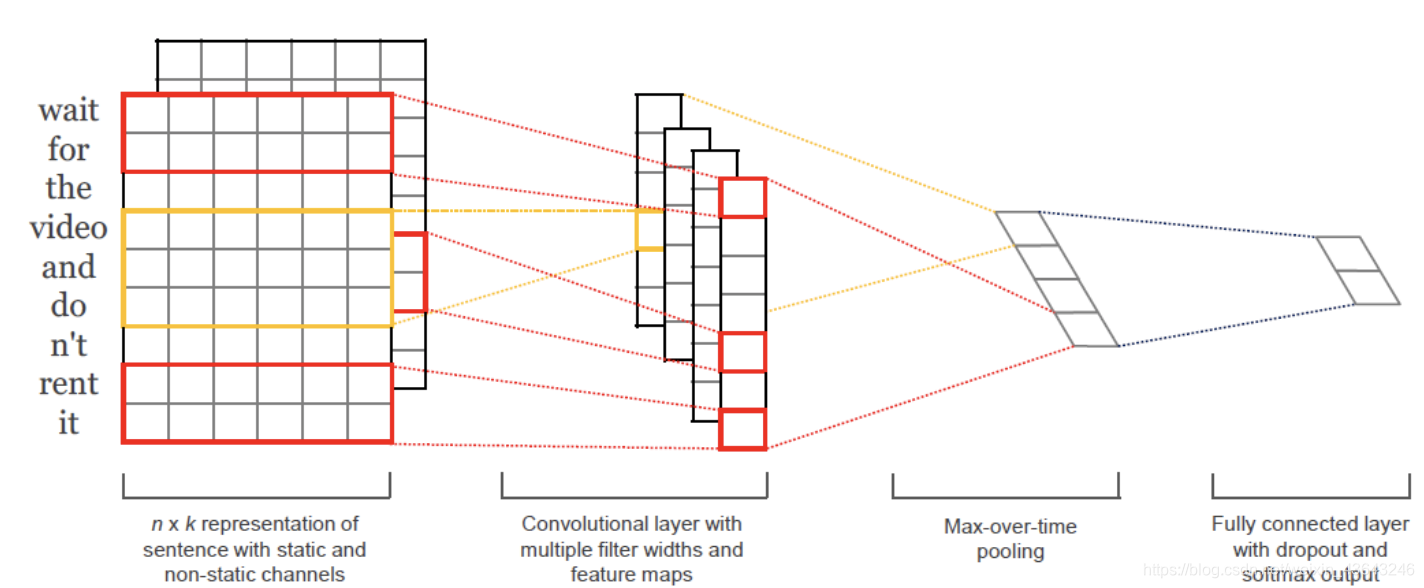
论文可以在这里找到Convolutional Neural Networks for Sentence Classification
后面的实现参考文本分类实战(二)—— textCNN 模型
因为用的自己的数据集,所以在此基础上做了一点点改动
代码
import os
import csv
#import time
#import datatime
import random
import json
from collections import Counter
from math import sqrt
import gensim
import pandas as pd
import numpy as np
import tensorflow as tf
#from sklearn.metrics import roc_auc_score,accuray_score,precision,recall_score #导入评价指标
参数设置
#配置参数
#训练参数
class TrainingConfig(object):
epoches=10
evaluateEvery=1000
checkpointEvery=1000
learningRate=0.001
#模型参数
class ModelConfig(object):
embeddingSize=300
numFilters=300
filterSizes=[2,3,4,5]
dropoutKeepProb=0.5
l2RegLambda=0.0
class Config(object):
sequenceLength=100
batchSize=16
trainSource='./data/train_data.csv'
devSource='./data/val_data.csv'
testSource='./data/test_data.csv'
stopWordSource='./data/stopsword.txt'
numClasses=44
rate=0.8
training=TrainingConfig()
model=ModelConfig()
#实例化对象
config=Config()
取数据的方式
我理解这部分,就是你如何从自己的数据读出数据,并处理成你模型能接受的样子,简单来说,就是你处于数据的类。
我的数据是这样的清洗后是这样的,一共是44个类别,属于多分类问题

class Dataset(object):
def __init__(self, config):
self.config = config
self._trainSource = config.trainSource
self._devSource = config.devSource
self._testSource = config.testSource
self._stopWordSource = config.stopWordSource
self._sequenceLength = config.sequenceLength
self._embeddingSize = config.model.embeddingSize
self._batchSize = config.batchSize
self._rate = config.rate
self._stopWordDict = {}
self.trainSentences = []
self.trainLabels = []
self.evalSentences = []
self.evalLabels = []
self.wordEmbedding = None
self.labelList = []
def _readData(self,filePath):
#读数据的方法
lines=open(filePath,encoding='utf-8').read().split('\n')
sentences=''
labels=''
for i in range(len(lines)-1):
item=lines[i].split('\t')
labels+=str(item[0])
labels+='\n'
sentences+=str(item[1])
sentences+='\n'
labels = labels.strip().split('\n')
sentences = sentences.strip().split('\n')
return sentences,labels
def _labelToIndex(self,labels,label2idx):
#将标签转化成索引
labelIds=[label2idx[label] for label in labels]
return labelIds
def _wordToIndex(self,sentences,word2idx):
#将词转换成索引
sentenceIds=[[word2idx.get(item, word2idx["UNK"]) for item in sentence] for sentence in sentences]
return sentenceIds
def _dealDate(self,x,y,word2idx):
#补全或者截取句子的长度
sentences=[]
for sentence in x:
if len(sentence) >= self._sequenceLength:
sentences.append(sentence[:self._sequenceLength]) #截断过长的
else:
sentences.append(sentence+[word2idx["PAD"]]*(self._sequenceLength - len(sentence))) #补长
Sentences=np.array(sentences,dtype="int64")
Labels = np.array(y, dtype="float32")
return Sentences, Labels
def _genVocabulary(self,sentences,labels):
#生成词向量 词汇-索引映射字典
allWords = [word for sentence in sentences for word in sentence]
#取掉停用词
subWords = [word for word in allWords if word not in self.stopWordDict]
wordCount = Counter(subWords) # 统计词频
sortWordCount = sorted(wordCount.items(), key=lambda x: x[1], reverse=True)
#按照词频数排序
# 去除低频词
words = [item[0] for item in sortWordCount if item[1] >= 5]
vocab, wordEmbedding = self._getWordEmbedding(words)
self.wordEmbedding = wordEmbedding #word-embedding的映射
word2idx= dict(zip(vocab, list(range(len(vocab))))) #词表 word-id的映射
uniqueLabel = list(set(labels))
#print(uniqueLabel)
label2idx = dict(zip(uniqueLabel, list(range(len(uniqueLabel))))) #标签表 label-id的映射
self.labelList = list(range(len(uniqueLabel)))
# 将词汇-索引映射表保存为json数据,之后做inference时直接加载来处理数据
with open("./data/word2idx.json", "w", encoding="utf-8") as f:
json.dump(word2idx, f)
with open("./data/label2idx.json", "w", encoding="utf-8") as f:
json.dump(label2idx, f)
return word2idx, label2idx
def _getWordEmbedding(self,words):
#按照我们数据集建立的词表从训练好的word2vec提取出词向量
vocab=[]
wordEmbedding=[]
# 添加 "pad" 和 "UNK",
vocab.append("PAD")
vocab.append("UNK")
wordEmbedding.append 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









