







Kaggle房价预测竞赛——Pandas数据预处理
数据集
California House Prices
Predict California sales prices
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
1 导入数据
(1) 读取数据
test_data = pd.read_csv('test.csv')
train_data = pd.read_csv('train.csv')
print(train_data.shape, test_data.shape)
(1460, 81) (1459, 80)
(2)查看前五条数据中的四个特征以及后三个特征
print(train_data.iloc[0:5, [0, 1, 2, 3, -3, -2, -1]])

(3) 去掉“Id”列,拼接 train_data & test_data
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
all_features.shape
(2919, 79)
2 描述性统计
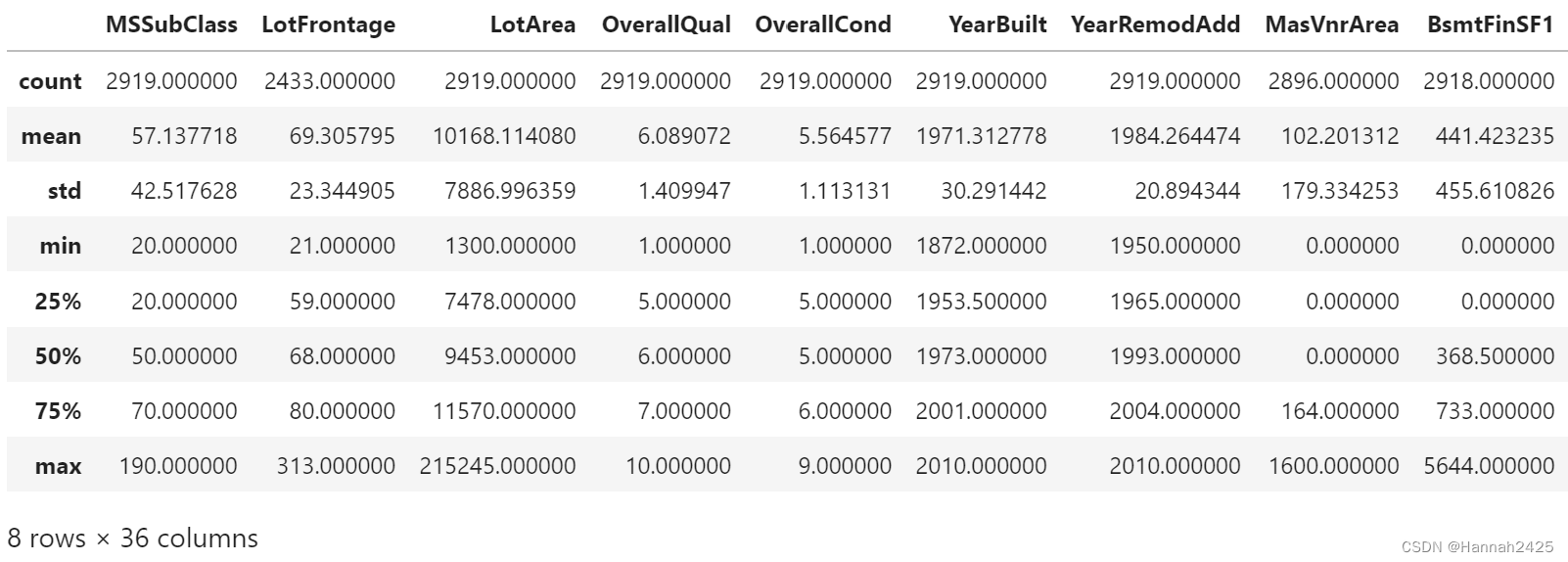
(1) 特征的非空数、均值、标准差、最小值、最大值…
all_features.describe()
(2) 特征的类型
all_features.dtypes # type(all_features.dtypes)==pandas.core.series.Series

Kaggle竞赛中Data栏目可以看到更详细的数据描述性统计
3 处理数值型数据
填充缺失+归一化
#(1)查询数值类型的列,缺失值替换为平均值(归一化后的均值就是0),利用均值和标准差整体归一化
numeric_features = all_features.dtypes[all_features.dtypes!='object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x-x.mean())/x.std())
all_features[numeric_features] = all_features[numeric_features].fillna(0)
print(len(numeric_features))
4 处理非数值型数据
看一下非数字的object都有哪些并且他们大概有多少个不同的类别
for in_object in all_features.dtypes[all_features.dtypes=='object'].index:
print(in_object.ljust(20),len(all_features[in_object].unique()))

one-hot 编码,“Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征。特征数由71个扩展至331个。
print(all_features.shape)
all_features_expand = pd.get_dummies(all_features, dummy_na=True)
print(all_features_expand.shape)

5 划分训练集特征、测试集特征、训练集标签
n_train = train_data.shape[0]
train_features = torch.tensor(all_features_expand[:n_train].values,dtype=torch.float32)
test_features = torch.tensor(all_features_expand[n_train:].values,dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1,1),dtype=torch.float32)
print(train_features.shape,"\n", test_features.shape, "\n", train_labels.shape)
















 1799
1799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









