






目录
1 MapReduce跑的慢的原因
MapReduce程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘、网络
2)I/O操作优化
(1)数据倾斜
(2)Map运行时间太长,导致Reduce等待过久
(3)小文件过多
2 MapReduce常用调优参数
map阶段
map详细流程见
1)自定义分区,减少数据倾斜;
定义类,继承Partitioner接口,重写getPartition方法
mapreduce之Partition分区_一抹鱼肚白的博客-CSDN博客
2)减少溢写的次数
mapreduce.task.io.sort.mb
Shuffle的环形缓冲区大小,默认100m,可以提高到200m
mapreduce.map.sort.spill.percent
环形缓冲区溢出的阈值,默认80% ,可以提高的90%
3)增加每次Merge合并次数
mapreduce.task.io.sort.factor默认10,可以提高到20
4)在不影响业务结果的前提条件下可以提前采用Combiner
job.setCombinerClass(xxxReducer.class);
5)为了减少磁盘IO,可以采用Snappy或者LZO压缩
conf.setBoolean("mapreduce.map.output.compress", true);
conf.setClass("mapreduce.map.output.compress.codec", SnappyCodec.class,CompressionCodec.class);
6)mapreduce.map.memory.mb 默认MapTask内存上限1024MB。可以根据128m数据对应1G内存原则提高该内存。
7)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
8)mapreduce.map.cpu.vcores 默认MapTask的CPU核数1。计算密集型任务可以增加CPU核数
9)异常重试
mapreduce.map.maxattempts每个Map Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。根据机器性能适当提高。
reduce阶段
reduce阶段详细流程见
ReduceTask工作机制_一抹鱼肚白的博客-CSDN博客
1)mapreduce.reduce.shuffle.parallelcopies每个Reduce去Map中拉取数据的并行数,默认值是5。可以提高到10。
2)mapreduce.reduce.shuffle.input.buffer.percent
Buffer大小占Reduce可用内存的比例,默认值0.7。可以提高到0.8
3)mapreduce.reduce.shuffle.merge.percent Buffer中的数据达到多少比例开始写入磁盘,默认值0.66。可以提高到0.75
4)mapreduce.reduce.memory.mb 默认ReduceTask内存上限1024MB,根据128m数据对应1G内存原则,适当提高内存到4-6G
5)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
6)mapreduce.reduce.cpu.vcores默认ReduceTask的CPU核数1个。可以提高到2-4个
7)mapreduce.reduce.maxattempts每个Reduce Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。
8)mapreduce.job.reduce.slowstart.completedmaps当MapTask完成的比例达到该值后才会为ReduceTask申请资源。默认是0.05。
9)mapreduce.task.timeout如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000(10分钟)。如果你的程序对每条输入数据的处理时间过长,建议将该参数调大。
10)如果可以不用Reduce,尽可能不用
3 MapReduce数据倾斜问题
1)数据倾斜现象
数据频率倾斜——某一个区域的数据量要远远大于其他区域。
数据大小倾斜——部分记录的大小远远大于平均值。
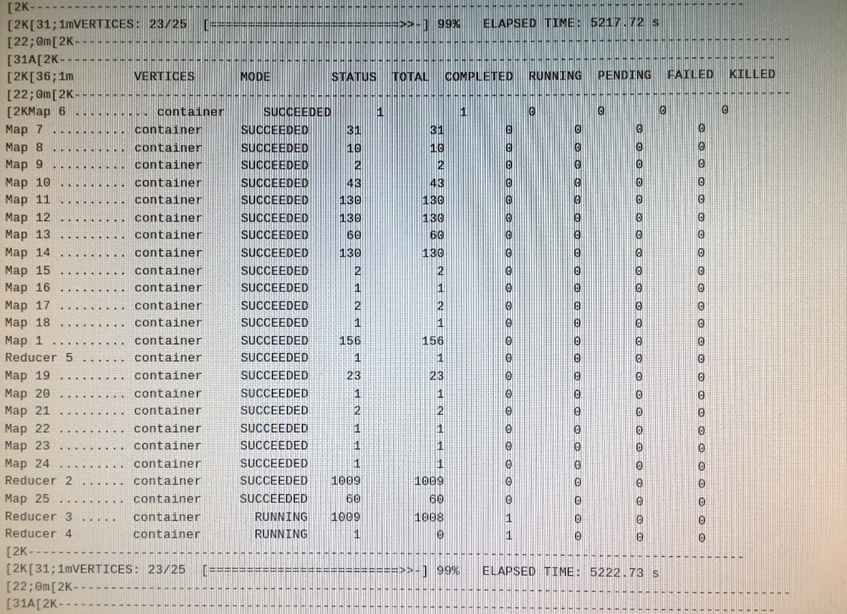
2)减少数据倾斜的方法
(1)首先检查是否空值过多造成的数据倾斜
生产环境,可以直接过滤掉空值;如果想保留空值,就自定义分区,将空值加随机数打散。最后再二次聚合。
(2)能在map阶段提前处理,最好先在Map阶段处理。如:Combiner、MapJoin
(3)设置多个reduce个数















 8038
8038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









