







1.网址校验:
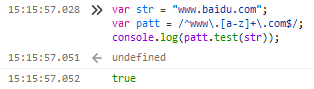
//www.xxxxxx.com校验
var patt = /^www\.[a-z]+\.com$/;
注:^www表示字符串以www开头;\.表示转义.;[a-z]+表示有若干小写字母(若不限定大小写可将[a-z]换成[a-zA-Z]);\.com$表示以.com结尾。
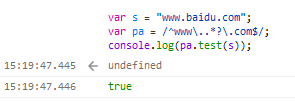
var pa = /^www\..*?\.com$/;
注:.*?中的.表示任意字符,*表示任意数量,?表示有零个或一个,合起来的意思就是有零个或一个任意长度的任意字符的字符串。
2.去除字符串中所有空格:
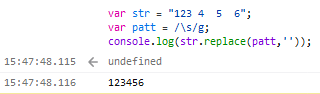
var patt = /\s/g;
注:\s(匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。___摘自菜鸟教程https://www.runoob.com/regexp/regexp-syntax.html),/g表示全局搜索(即字符串内),/\s/g即匹配字符串内所有空格字符。
3.两位小数百分数校验:
var pa = /[1-9]{1,2}\.[0-9]{2}%/;
注:[1-9]{1,2}表示有长度是1或2的由1-9以内的字符构建成的字符串,[0-9]{2}表示长度为2的由0-9以内的字符构建成的字符串。

4.省市县区校验
var patt = /^[\u2E80-\u9FFF]{1,}省[\u2E80-\u9FFF]{1,}市[\u2E80-\u9FFF]{1,}[县区]$/;
注:^[\u2E80-\u9FFF]{1,}省表示开头省字前有1及以上各汉字的字符串,[\u2E80-\u9FFF]{1,}市表示市字前有1及以上个汉字,[\u2E80-\u9FFF]{1,}[县区]$表示结尾的字符串前半部分有1及以上个汉字,后半部分为县区中的一个字符。

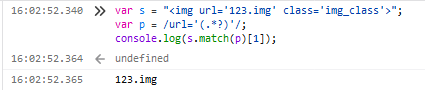
5.截取标签中的链接(爬虫需要)
var p = /str='(.*)'/;
注:(.*?)表示分组匹配任意长度任意字符串。
6.指定格式替换(分组匹配)
var patt = /([\u2E80-\u9FFF]{1,})省([\u2E80-\u9FFF]{1,})市/;
注:()是分组匹配标志,每一个()分组都表示一个对象,第一个()表示$1,第二个表示$2,依次往下。

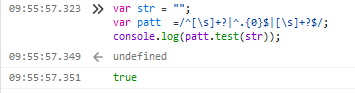
7.匹配空字符串及字符串开头结尾空字符串
var patt =/^[\s]+?|^.{0}$|[\s]+?$/;
注:^[\s]+?表示开头有至少一个空字符串,|表示“或”,^.{0}$表示字符串没有字符即空字符串,[\s]+?$表示结尾有 至少一个空字符串。
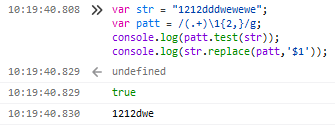
8.匹配字符串中重复出现的字符(串)
var patt = /(.+)\1{2,}/g;
注:(.+)表示任意长度长度至少为1的字符串,\1表示重复,{2,}表示在(.+)后面至少出现2次,/g中的g表示字符串全局搜索。
9.字符串截取(截取字符串结尾部分数字字符串)
var patt = /[0-9]+$/;

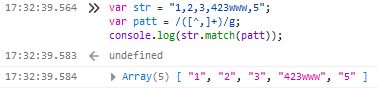
10.字符串分割split
var patt = /[^,]/g; //以逗号分割字符串
拓展:https://www.jb51.net/article/921.htm
https://www.cnblogs.com/wancheng7/p/8906015.html














 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









