







一、 数据
1. 数据类型
- 按 数据结构 可划分为:数值、文本、图像、图形、音频、视频等;
按 数据组织方式 可划分为:属性-值型数据 和 链接型数据;
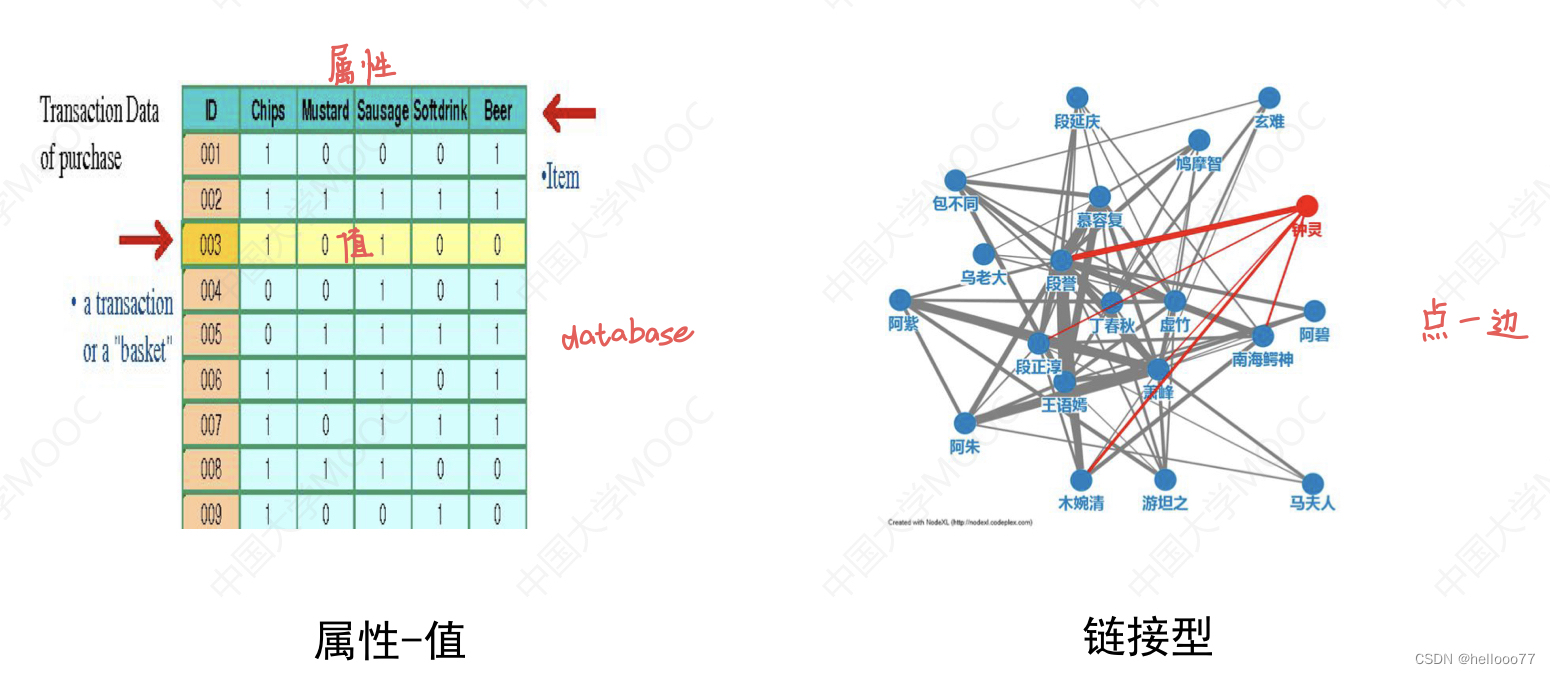
- 时序数据:以时间为下标的数据序列 ( 带时间标签的数据 )。eg. 购物记录
- 时空数据:同时具有时间和空间维度的数据。eg. 城市出租车出租轨迹
- 流数据 ( 大数据时代的一种重要数据类型 ) :是一种顺序、大量、快速、连续流进和流出的数据序列,可被视为一个 随时间延续而无限增长的动态数据集合 。其特点如下:
- 数据实时到达
- 数据到达次序独立
- 数据规模宏大且不能预知其最大值
- 数据一经处理,不能咋被再次提取
流数据出现的场景:网络监控、传感器网络、航空航天、气象监控、金融服务等应用领域。
2. 数据规范方法
- 定义:将数据按比例缩放,使之落入一个小的特定区间。
目的:通过数据规范化,可以在保持数据完整性的同时 最小化数据冗余 。 - 数据规范方法:最大最小值规范化、Z-score规范化、小数定标规范化
-
最大最小值规范化 ( 需要依靠属性A的最值 )
将属性A的值 v 基于A的最大最小值规范化为 v’。

-
Z-score规范化 ( 借助于属性A 的分布 )
将属性A的值 v 基于A的均值和标准差规范化为 v’。

-
小数定标规范化

3. 数据度量方法
- 目的:刻画数据之间的 远近亲疏程度 。
- 常用方法:相似性函数 ( 夹角余弦、杰卡德Jaccard 相似系数、相关系数 )、距离函数。
-
夹角余弦:两个向量夹角的余弦可以表示为两个向量的 方向差异 。

-
杰卡德Jaccard 相似系数:用于衡量两个集合 相似度 的一种指标。
- 定义:两个集合 A和B的交集元素在A和B的并集中所占的比例 。
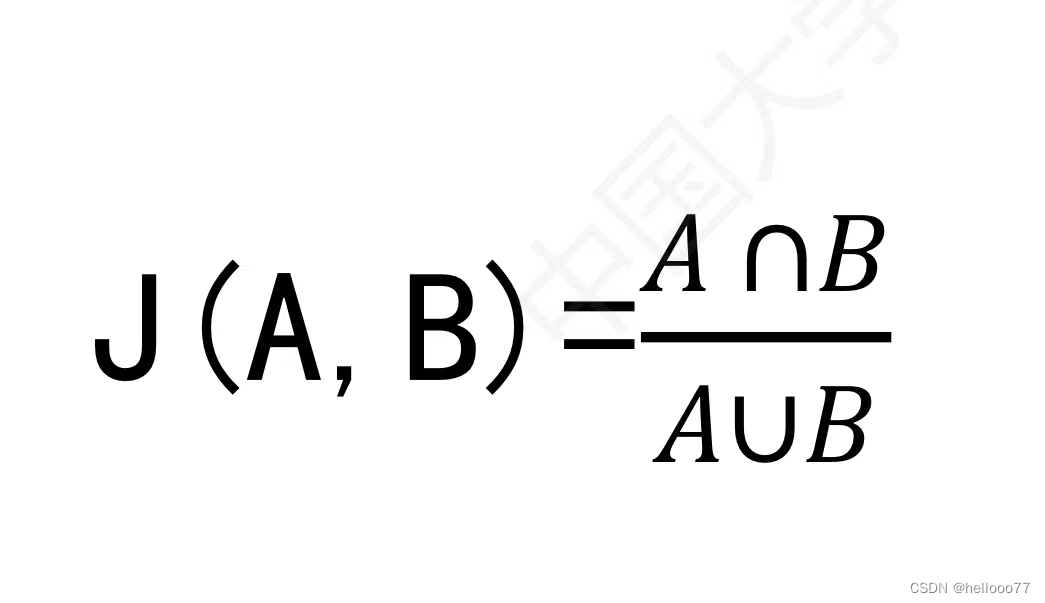
- 定义:两个集合 A和B的交集元素在A和B的并集中所占的比例 。
-
相关性系数:用于衡量数据的 相关性 的指标 。
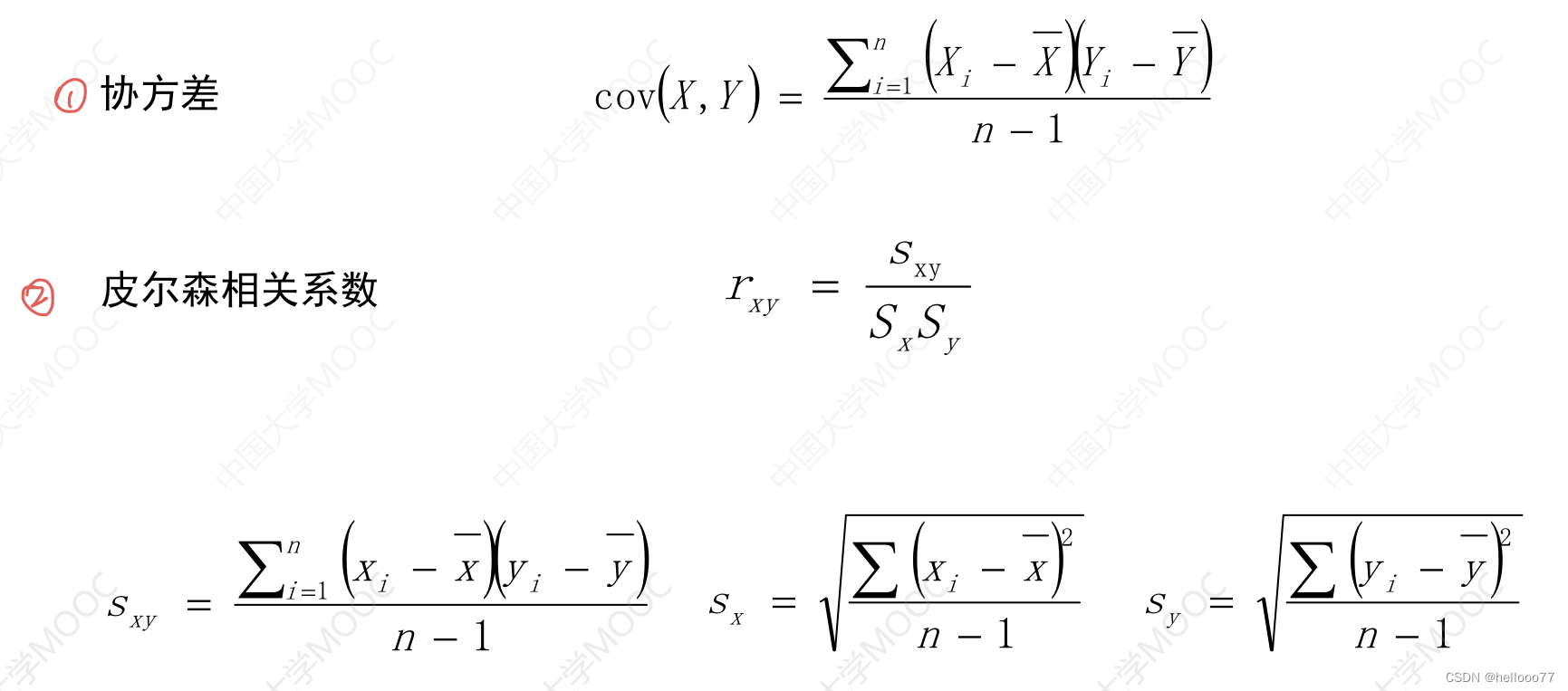
-
距离函数
- 距离的定义

- 距离度量
-
高维空间中两点 x 和 y 的 欧式距离 ( Euclodean distance )
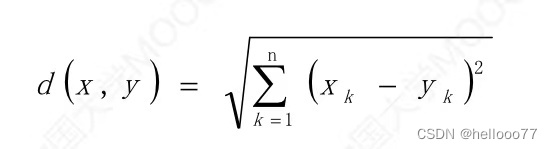
-
闵氏距离 ( Minkowski distance ) : 更广泛应用
-
- 距离的定义
二、 数据的特征表示
- 特征表示 的定义:将数据转化为 有利于后续分析和处理 的形式而进行的 一种形式化的表示和描述 。
- 特征工程 ( 大数据分析领域把数据的特征表示的研究领域叫做特征工程 )
定义:利用领域知识从原始数据中 提取 用于后续机器学习及数据挖掘应用的 特征(向量)的过程 。
所使用到的方法如下:
- 特征提取:在原始数据特征维度很高的情况下,利用映射(或变换)的方法 将高维的特征向量变换为低维特征向量 。
- 特征选择:从一组数量为 D 的特征中选择出数量为 d ( d<<D ) 的一组 最优特征 。
- 特征空间:每一条样本被称作是一个实例,通常由特征向量表示,所有特征向量存在的空间称为特征空间。
三、 数据建模与分析方法
- 数据分析的主要任务: 包括分类与回归分析、相关分析、聚类分析、关联规则挖掘和异常检测等,分为 预测 和 描述 两大类。
- 预测任务的目标:根据其他属性的值,预测特定属性的值。
- 描述任务的目标:导出和概括数据的潜在模式 ( 相关、趋势、聚类、轨迹和异常 ) 。
二者对比:预测任务是在数据上 进行归纳以做出预测 ; 描述性挖掘主要是 刻画目标数据的一般性质 。
- 主要方法
- 监督学习 ( supervised learning ) :学习中的监督来自 训练数据集 中 有标记的实例 。
- 无监督学习 ( unsupervised learning ) :学习过程中输入的实例没有类标记。
- 半监督学习 ( Semi-supervised learning ) :是监督学习与无监督学习相结合的一种学习方法。利用 未标记的 大量数据 **提升机器学习算法的表现效果( 性能 ) ** 。
- 强化学习 ( reinforcement learning ) 又称 “在励学习”、“增强学习”:用于描述和解决智能体 (agent) 在与环境的交互过程中 通过学习策略以达成回报最大化或实现特定目标的问题。
- 深度学习 ( deep learning ) :是机器学习的一个新研究方向。该概念源于 人工神经网络 的研究,通过组合低层特征形成更加抽象的高层表示。
- 学习 分类
- 分类 属于 有监督学习。
- 步骤:从给定的 有标记训练数据集 中学习模型,当未标记数据到来时,可以根据训练好的模型预测结果。
- 导出的模型的表示形式有:分类规则、决策树、神经网络等形式。
- 训练+预测 过程图示:
3.1 K最邻近( k-Nearest Neighbor ) - KNN ( 典型的分类算法 )

KNN 缺点:
- 需要存储全部的训练样本
- 需要进行繁重的距离计算
改进的 KNN 算法:
- 分组快速搜索近邻法
- 压缩近邻算法

3.2 朴素贝叶斯 - 基础知识

- 步骤

- 学习 回归分析
- 目的:了解 两个或多个变量间是否相关、相关方向与强度 ,并建立数学模型以便观察特定变量来 预测研究者感兴趣的变量 ,主要包括 线性回归分析 和 非线性回归分析。
- 分类 vs. 回归
- 相同点:研究输入输出变量之间的关系。
- 不同点:分类输出的是离散的类别值,回归输出的是连续的数值。
- 学习 聚类
- 聚类分析 ( Cluster Analysis ) 又称群分析,是根据 “物以类聚” 的道理,对数据进行划分。
- 聚类是在 没有先验知识 的情况下进行的 ( 无监督学习 ) 。
- 划分基本思想:同一类簇的任意两个点间的距离小于不同类簇的任意两个点间的距离。
- 聚类算法包括:K-means、DBSCAN、层次聚类算法、密度峰值聚类等。
- 学习 关联规则挖掘
- 关联规则 ( Association rules ) 挖掘:发现大量数据中 项集之间 有趣的 关联或相关联系 。
- 学习 深度学习
- 含多隐层的深度学习模型 图示
- 多隐层的人工神经网络具有优异的特征学习能力,学习 得到的特征对数据有更本质的刻画 ,从而有利于可视化或分类。
- 深度神经网络在训练上的难度,可以通过 “逐层初始化” ( layer-wise pre-training ) 来有效克服,逐层初始化可通过无监督学习实现。
7.1 深度学习的具体模型及方法
- 生成式 / 无监督模型
- 正则化的自编码器
- 受限玻尔兹曼机
- 深度置信网络 ( Deep Belief Networks – DBN )
- 判别式模型
- 递归神经网络
- 深度神经网络
- 卷积神经网络 ( 深度残差网络 )















 2457
2457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











