







文章目录
1.连接redis服务
1.1 本地redis服务
redis-cli
1.2 redis服务器不在本地
redis-cli -h 127.0.0.1 -p 6379
-h <hostname> server hostname(default:127.0.0.1)
-p <port> server port(default: 6379)
2.数据结构及其命令
2.1 字符串string
string数据结构

/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
//buf 已经使用的长度
uint8_t len; /* used */
//buf 分配的长度,等于buf[]的总长度-1,因为buf有包括一个/0的结束符
uint8_t alloc; /* excluding the header and null terminator */
//只有3位有效位,因为类型的表示就是0到4,所有这个8位的flags 有5位没有被用到,表示用的是sds几,比如说这个就是1,表示sdshr8
unsigned char flags; /* 3 lsb of type, 5 unused bits */
//实际的字符串存在这里
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
1)len:表示buf中已占用字节数。
2)alloc:表示buf中已分配字节数,不同于free,记录的是为buf分配的总长度。
3)flags:标识当前结构体的类型,低3位用作标识位,高5位预留。
4)buf:柔性数组,真正存储字符串的数据空间。
string基本操作
string函数API

string命令API
Redis 字符串命令
序号 命令及描述
1 SET key value
设置指定 key 的值,在执行SET命令时给定了NX选项,如果键已经存在,那么SET命令将放弃执行设置操作,返回nil;XX选项:那么SET命令只会在键已经有值的情况下执行设置操作,并返回OK表示设置成功
2 GET key
获取指定 key 的值。
3 GETRANGE key start end
返回 key 中字符串值的子字符
4 GETSET key value
将给定 key 的值设为 value ,并返回 key 的旧值(old value)。
5 GETBIT key offset
对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
6 MGET key1 [key2..]
获取所有(一个或多个)给定 key 的值。
7 SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
8 SETEX key seconds value
将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。
9 SETNX key value
只有在 key 不存在时设置 key 的值。
10 SETRANGE key offset value
用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。
11 STRLEN key
返回 key 所储存的字符串值的长度。
12 MSET key value [key value ...]
同时设置一个或多个 key-value 对。
13 MSETNX key value [key value ...]
同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
14 PSETEX key milliseconds value
这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX
命令那样,以秒为单位。
15 INCR key
将 key 中储存的数字值增一。
16 INCRBY key increment
将 key 所储存的值加上给定的增量值(increment)。
17 INCRBYFLOAT key increment
将 key 所储存的值加上给定的浮点增量值(increment)。
18 DECR key
将 key 中储存的数字值减一。
19 DECRBY key decrement
key 所储存的值减去给定的减量值(decrement) 。
20 APPEND key value
如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾
string应用举例
缓存热门图片
set redis-log.jpg redis-log-data
存储文章
当用户想在博客中撰写一篇新文章的时候,程序就需要把文章的标题、内容、作者、发表时间等多项信息存储起来,并在用户阅读文章的时候取出来这些信息。可以使用 mset mget msetnx 命令来进行

文章长度计数功能、文章摘要、文章计数
文章长度:STRLEN article:10086:content
文章摘要:GETRANGE article:10086:content 0 5
文章阅读计数:INCR article:10086:count
消息 ID
即时通讯的消息 ID:INCR msgid:darren:to:king
限速器
- 防止网站内容被网络爬虫疯狂抓取,限制每个 ip 地址在固定的时间段内能够访问的页面数量,比如1 分钟最多只能访问 30 个页面。
- 防止用户的账号遭到暴力破解,如果同个账号连续好几次输入错误的密码,则限制账号的登录,只能等 30 分钟后再次登录,比如设置 3 次
(1)SET max:execute:times 3
(2)密码出错时 DECR max:execute:times
(3)当 max:execute:times 的值小于 0 时则禁止登录,并可以设置SETEX login:error:darren 1800 “Incorrect password”,然后使用 TTL login:error:darren 1800 检测对应剩余的时间
string总结
1)常数复杂度获取字符串长度。
2)杜绝缓冲区溢出。
3)减少修改字符串长度时所需的内存重分配次数。
4)二进制安全。
5)兼容部分C字符串函数。
6)字符串的值既可以存储文字数据,又可以存储二进制数据。
7)MSET/MGET 命令可以有效地减少程序的网络通信次数,从而提高程序的执行效率。
8)redis 用户可以定制命名格式来提升 redis 数据的可读性并避免键名冲突。
2.2 散列hash
2.3 压缩列表ziplist
2.3.1 压缩链表的构成


- 压缩链表结构
1.zlbytes:记录整个内存列表占用的内存字节数(在对压缩列表进行内存重新分配,或者计算zlend的位置时候使用),举例:zlbytes属性的值为0x50(十进制80),表示压缩列表的总长为80字节
2.zltail:记录压缩列表表尾节点距离列表的起始地址有多少字节,通过这个偏移量,程序无需遍历整个压缩链表就可以确定表尾节点的地址,举例:列表zltail属性的值为0x3c(十进制60),这表示如果我们有一个指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量60,就可以计算出表尾节点entry3的地址。
3.zllen:记录压缩链表包含的节点数量(当这个属性的值小于UINT16_MAX 65535时),这个属性的值就是压缩链表包含节点的数量;当这个值大于UINT16_MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出,举例:列表zllen属性的值为0x3(十进制3),表示压缩列表包含三个节点
4.entryX(X表示第几个节点):表示压缩列表包含的各个节点,节点的长度由节点保存的内容决定
5.zlend:特殊值0xFF(十进制255),用于标记压缩列表的末端
- 具体代码:
假设char * zl指向压缩列表首地址,Redis可通过以下宏定义实现压缩列表各个字段的存取操作

/* Return total bytes a ziplist is composed of. */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* Return the offset of the last item inside the ziplist. */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* Return the length of a ziplist, or UINT16_MAX if the length cannot be
* determined without scanning the whole ziplist. */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* The size of a ziplist header: two 32 bit integers for the total
* bytes count and last item offset. One 16 bit integer for the number
* of items field. */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* Size of the "end of ziplist" entry. Just one byte. */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
/* Return the pointer to the first entry of a ziplist. */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* Return the pointer to the last entry of a ziplist, using the
* last entry offset inside the ziplist header. */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* Return the pointer to the last byte of a ziplist, which is, the
* end of ziplist FF entry. */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
- 举例说明:

1)列表zlbytes属性的值为0xd2(十进制210),表示压缩列表的总长为210字节。
2)列表zltail属性的值为0xb3(十进制179),这表示如果我们有一个指向压缩列表起始地址的指针p,那么只要用指针p加上偏移量179,就可以计算出表尾节点entry5的地址。
3)列表zllen属性的值为0x5(十进制5),表示压缩列表包含五个节点。
4)zlend属性的值为0xFF(十进制255),表示压缩链表的结尾位置
2.3.2 压缩链表节点的构成
- 每个entryN(N表示序号)节点的结构如下:

- 结构体
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
previous_entry_length
- 定义说明:
1.节点的previous_entry_length属性以字节为单位,记录了压缩列表中前一个节点的长度
2.如果前一节点的长度小于254字节,那么previous_entry_length属性的长度为1字节:前一节点的长度就保存在这一个字节里面。
3.如果前一节点的长度大于等于254字节,那么previous_entry_length属性的长度为5字节:其中属性的第一字节会被设置为0xFE(十进制值254),而之后的四个字节则用于保存前一节点的长度
- 举例:

上图展示了一个包含五字节长previous_entry_length属性的压缩节点,属性的值为0xFE00002766,其中值的最高位字节0xFE表示这是一个五字节长的previous_entry_length属性,而之后的四字节0x00002766(十进制值10086)才是前一节点的实际长度。
- 遍历:
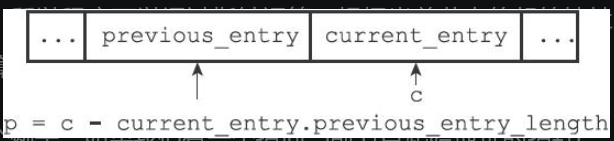
因为节点的previous_entry_length属性记录了前一个节点的长度,所以程序可以通过指针运算,根据当前节点的起始地址来计算出前一个节点的起始地址
encoding
- 定义说明:节点的encoding属性记录了节点的content属性所保存数据的类型以及长度
1)一字节、两字节或者五字节长,值的最高位为00、01或者10的是字节数组编码:这种编码表示节点的content属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录
2)一字节长,值的最高位以11开头的是整数编码:这种编码表示节点的content属性保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录
- 字节数组编码(按编码长度分类各类存储数据的大小)

- 整数编码

//字符数组
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
//整数
#define ZIP_INT_16B (0xc0 | 0<<4) //int16_t
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe
content
- 定义:节点的content属性负责保存节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的encoding属性决定
- 举例:
字符数组
编码的最高两位00表示节点保存的是一个字节数组
编码的后六位001011记录了字节数组的长度11
content属性保存着节点的值"hello world"

整数
编码11000000表示节点保存的是一个int16_t类型的整数值
content属性保存着节点的值10086

2.3.3 连锁更新
- 情景带入:
1)现在,考虑这样一种情况:在一个压缩列表中,有多个连续的、长度介于250字节到253字节之间的节点e1至eN,如图所示:
2)因为e1至eN的所有节点的长度都小于254字节,所以记录这些节点的长度只需要1字节长的previous_entry_length属性,换句话说,e1至eN的所有节点的previous_entry_length属性都是1字节长的
3)这时,如果我们将一个长度大于等于254字节的新节点new设置为压缩列表的表头节点,
4)因为e1的previous_entry_length属性仅长1字节,它没办法保存新节点new的长度,所以程序将对压缩列表执行空间重分配操作,并将e1节点的previous_entry_length属性从原来的1字节长扩展为5字节长

-
除了添加新节点可能会引发连锁更新之外,删除节点也可能会引发连锁更新。

-
因为连锁更新在最坏情况下需要对压缩列表执行N次空间重分配操作,而每次空间重分配的最坏复杂度为O(N),所以连锁更新的最坏复杂度为O(N*N)
-
要注意的是,尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的
1)首先,压缩列表里要恰好有多个连续的、长度介于250字节至253字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见
2)其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的
- redis_benchmark在插入254节点附近测试会引起大量的连锁更新
2.3.4 压缩链表API
函数API

- 因为ziplistPush头部或尾部插入新节点、ziplistInsert指定位置插节点、ziplistDelete删除指定的节点和ziplistDeleteRange删除连接多个节点,四个函数都有可能会引发连锁更新,所以它们的最坏复杂度都是O(N*N).
- 补充讲解
1)插入元素:① 将元素内容编码;② 重新分配空间;③ 复制数据
2)删除元素:① 计算待删除元素的总长度;② 数据复制;③ 重新分配空间
3)遍历压缩链表:从后往前遍历简单,从前往后遍历时,后向遍历时,需要解码当前元素,计算当前元素的长度,才能获取后一个元素首地址,函数ziplistNext()
指令API
Redis Hash 命令
序号 命令及描述
1 HDEL key field1 [field2]
删除一个或多个哈希表字段
2 HEXISTS key field
查看哈希表 key 中,指定的字段是否存在。
3 HGET key field
获取存储在哈希表中指定字段的值。
4 HGETALL key
获取在哈希表中指定 key 的所有字段和值
5 HINCRBY key field increment
为哈希表 key 中的指定字段的整数值加上增量 increment 。 6 HINCRBYFLOAT key field increment
为哈希表 key 中的指定字段的浮点数值加上增量 increment 。 7 HKEYS key
获取所有哈希表中的字段
8 HLEN key
获取哈希表中字段的数量
9 HMGET key field1 [field2]
获取所有给定字段的值
10 HMSET key field1 value1 [field2 value2 ]
同时将多个 field-value (域-值)对设置到哈希表 key 中。
11 HSET key field value
将哈希表 key 中的字段 field 的值设为 value 。
12 HSETNX key field value
只有在字段 field 不存在时,设置哈希表字段的值。
13 HVALS key
获取哈希表中所有值
14 HSCAN key cursor [MATCH pattern] [COUNT count]
迭代哈希表中的键值对
2.3.5 应用举例
短网址生成程序

使用散列表重新实现文件存储

2.3.6 散列表和字符串

散列键的优点
- 散列的最大优势,只需要在数据库里面创建一个键,就可以把任意多的字段和值存储到散列里面

字符串键的优点
- 字符串的功能更丰富
1)虽然散列键命令和字符串键命令在部分功能上有重合的地方,但是字符串键命令提供的操作比散列
键命令更为丰富。比如,字符串能够使用 SETRANGE 命令和 GETRANGE 命令设置或者读取字符
串值的其中一部分,或者使用 APPEND 命令将新内容追加到字符串值的末尾,而散列键并不支持
这些操作。
2)再比如我们要设置键过期时间,键过期时间是针对整个键的,用户无法为散列中的不同字段设置不
同的过期时间,所以当一个散列键过期的时候,他包含的所有字段和值都会被删除。与此相反,如
果用户使用字符串键存储信息项,就不会遇到这样的问题——用户可以为每个字符串键分别设置不
同的过期时间,让它们根据实际的需要自动被删除
字符串键和散列键的选择
| 比较的范畴 | 结果 |
|---|---|
| 资源占用 | 字符串键在数量较多的情况下,将占用大量的内存和 cpu 时间。与此相反,将多个数据项存储到同一个散列中可以有效地减少内存和 cpu 消 耗。 |
| 支持的操作 | 散列键支持的所有命令,几乎都有对应的字符串键版本,但字符串键支持的 SETRANGE、GETRANGE、APPEND 等操作散列并不具备 |
| 过期时间 | 字符串可以为单个键单独设置过期时间,独立删除某个数据项,而散列一旦到期,它包含的所有字段和值都会被删除 |
- 适用场景对比:
1.如果程序需要为单个数据项单独设置过期的时间,那么使用字符串键。
2. 如果程序需要对数据项执行诸如 SETRANGE、GETRANGE 或者 APPEND 等操作,那么优
先考虑使用字符串键。当然,用户也可以选择把数据存储在散列中,然后将类似 SETRANG
E、GETRANGE 这样的操作交给客户端执行。
3 如果程序需要存储的数据项比较多,并且你希望尽可能地减少存储数据所需的内存,就应该优
先考虑使用散列键。
4 如果多个数据项在逻辑上属于同一组或者同一类,那么应该优先考虑使用散列键
2.3.7 总结
- 压缩列表是一种为节约内存而开发的顺序型数据结构。
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值
- 添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率并不高。
补充:链表quicklist,每个quicklist的节点都是ziplist压缩链表
链表结构
- 3.2 及3.2之前
Redis 3.2版本之前使用的双向非循环链表的基本结构如图

- 3.2 版本到现在
1.quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为Adoubly linked list of ziplists
2.quicklist是一个双向链表,链表中的每个节点是一个ziplist结构

- 数据结构(quickNode是quicklist中的一个节点):
typedef struct quicklistNode {
struct quicklistNode *prev; //prev、next指向该节点的前后节点
struct quicklistNode *next;
unsigned char *zl; //指向该节点对应的ziplist结构
unsigned int sz; /* ziplist size in bytes */
//代表整个ziplist结构的大小
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//采用常用的编码方式,1代表是原生的,2代表使用LZF进行压缩
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//ontainer为quicklistNode节点zl指向的容器类型:1代表none,2代表使用ziplist存储数据
unsigned int recompress : 1; /* was this node previous compressed? */
//recompress代表这个节点之前是否是压缩节点,若是,则在使用压缩节点前先进行解压缩,使用后需要重新压缩,此外为1,代表是压缩节点
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
//extra为预留
} quicklistNode;
//当我们对ziplist利用LZF算法进行压缩时,quicklistNode节点指向的结构为quicklistLZF
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
//sz表示compressed所占字节大小。
char compressed[];
} quicklistLZF;
//当我们使用quicklistNode中ziplist中的一个节点时,Redis提供了quicklistEntry结构以便于使用,该结构如下
typedef struct quicklistEntry {
const quicklist *quicklist; //quicklist指向当前元素所在的quicklist
quicklistNode *node; //node指向当前元素所在的quicklistNode结构
unsigned char *zi; //zi指向当前元素所在的ziplist
unsigned char *value; //value指向该节点的字符串内容
long long longval; //longval为该节点的整型值
unsigned int sz; //sz代表该节点的大小
int offset; //offset表明该节点相对于整个ziplist的偏移量
} quicklistEntry;
//quicklistIter是quicklist中用于遍历的迭代器
typedef struct quicklistIter {
const quicklist *quicklist; //quicklist指向当前元素所处的quicklist
quicklistNode *current; //current指向元素所在quicklistNode
unsigned char *zi; //zi指向元素所在的ziplist
long offset; /* offset in current ziplist */
//ffset表明节点在所在的ziplist中的偏移量
int direction; //direction表明迭代器的方向
} quicklistIter;
数据压缩
- 目的:降低ziplist所占用的空间
1.quicklist每个节点的实际数据存储结构为ziplist,这种结构的主要优势在于节省存储空间。为了进一步降低ziplist所占用的空间,Redis允许对ziplist进一步压缩,Redis采用的压缩算法是LZF
2.压缩过后的数据可以分成多个片段,每个片段有2部分:一部分是解释字段,另一部分是存放具体的数据字段。解释字段可以占用1~3个字节,数据字段可能不存在.

- LZF压缩的数据格式:(3种)
1)字面型,解释字段占用1个字节,数据字段长度由解释字段后5位决定。示例如图7-5所示,图中L是数据长度字段,数据长度是长度字段组成的字面值加1。
2)简短重复型,解释字段占用2个字节,没有数据字段,数据内容与前面数据内容重复,重复长度小于8,示例如图7-6所示,图中L是长度字段,数据长度为长度字段的字面值加2, o是偏移量字段,位置偏移量是偏移字段组成的字面值加1。
3)批量重复型,解释字段占3个字节,没有数据字段,数据内容与前面内容重复。示例如图7-7所示,图中L是长度字段,数据长度为长度字段的字面值加9, o是偏移量字段,位置偏移量是偏移字段组成的字面值加1。



- 压缩
1.思想:数据与前面重复的,记录重复位置以及重复长度,否则直接记录原始数据内容
2.流程:遍历输入字符串,对当前字符及其后面2个字符进行散列运算,如果在Hash表中找到曾经出现的记录,则计算重复字节的长度以及位置,反之直接输出数据。下面给出了LZF源码的核心部分。(用到的函数:lzf_compress)
- 解压缩
1.根据LZF压缩后的数据格式,我们可以较为容易地实现LZF的解压缩。值得注意的是,可能存在重复数据与当前位置重叠的情况,例如在当前位置前的15个字节处,重复了20个字节,此时需要按位逐个复制
2.解压缩函数 lzf_decompress(const void* const in_data, unsigned int in_len,void* out_data , unsigned int out_len)
基本操作
初始化

quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
//ziplist大小默认是8KB
quicklist->bookmark_count = 0;
return quicklist;
}
添加元素
- 说明:
quicklist提供了push操作,对外接口为quicklistPush,可以在头部或者尾部进行插入,具体的操作函数为quicklistPushHead与quicklistPushTail。两者的思路基本一致,下面针对quicklistPushHead进行讲解。
- 代码:
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
//头部节点仍然可以插入
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
//头部节点不可以继续插入,新建quicklistNode,ziplist
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
//新建节点
quicklistNodeUpdateSz(node);
//将新建的quicklistNode插入到quicklist结构体中
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
删除元素
更改元素
- 思路:先删除原有元素,之后插入新的元素
- 说明:quicklist不适合直接改变原有元素,主要由于其内部是ziplist结构,ziplist在内存中是连续存储的,当改变其中一个元素时,可能会影响后续元素。故而,quicklist采用先删除后插入的方案
- 代码:
/* Replace quicklist entry at offset 'index' by 'data' with length 'sz'.
*
* Returns 1 if replace happened.
* Returns 0 if replace failed and no changes happened. */
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
int sz) {
quicklistEntry entry;
if (likely(quicklistIndex(quicklist, index, &entry))) {
/* quicklistIndex provides an uncompressed node */
//删除元素
entry.node->zl = ziplistDelete(entry.node->zl, &entry.zi);
//插入元素
entry.node->zl = ziplistInsert(entry.node->zl, entry.zi, data, sz);
quicklistNodeUpdateSz(entry.node);
quicklistCompress(quicklist, entry.node);
return 1;
} else {
return 0;
}
}
查找元素
- 思路:通过元素在链表中的下标查找对应元素
- 方法:首先找到index对应的数据所在的quicklistNode节点,之后调用ziplist的接口函数ziplistGet得到index对应的数据,源码中的处理函数为quicklistIndex
/* Populate 'entry' with the element at the specified zero-based index
* where 0 is the head, 1 is the element next to head
* and so on. Negative integers are used in order to count
* from the tail, -1 is the last element, -2 the penultimate
* and so on. If the index is out of range 0 is returned.
*
* Returns 1 if element found
* Returns 0 if element not found */
//idx为需要查找的下标,结果写入entry
int quicklistIndex(const quicklist *quicklist, const long long idx,
quicklistEntry *entry) {
quicklistNode *n;
unsigned long long accum = 0;
unsigned long long index;
//1.当idx为负值时,代表从尾部向头部的偏移量,-1代表尾部元素
int forward = idx < 0 ? 0 : 1; /* < 0 -> reverse, 0+ -> forward */
//2.初始化entry,index以及quicklistNode
initEntry(entry);
entry->quicklist = quicklist;
if (!forward) {
index = (-idx) - 1;
n = quicklist->tail;
} else {
index = idx;
n = quicklist->head;
}
if (index >= quicklist->count)
return 0;
//3.遍历quicklistNode节点,找到index对应的quicklistNode
while (likely(n)) {
if ((accum + n->count) > index) {
break;
} else {
D("Skipping over (%p) %u at accum %lld", (void *)n, n->count,
accum);
accum += n->count;
n = forward ? n->next : n->prev;
}
}
if (!n)
return 0;
D("Found node: %p at accum %llu, idx %llu, sub+ %llu, sub- %llu", (void *)n,
accum, index, index - accum, (-index) - 1 + accum);
//4.计算index所在ziplist的偏移量
entry->node = n;
if (forward) {
/* forward = normal head-to-tail offset. */
entry->offset = index - accum;
} else {
/* reverse = need negative offset for tail-to-head, so undo
* the result of the original if (index < 0) above. */
entry->offset = (-index) - 1 + accum;
}
quicklistDecompressNodeForUse(entry->node);
entry->zi = ziplistIndex(entry->node->zl, entry->offset);
//5.利用ziplist获取元素
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
/* The caller will use our result, so we don't re-compress here.
* The caller can recompress or delete the node as needed. */
return 1;
}
函数API
- 本节对quicklist常用的API进行总结,并给出其操作的时间复杂度。我们假设quicklist的节点个数为n,即quicklistNode的个数为n;每个quicklistNode指向的ziplist的元素个数为m;区间操作中区间长度为l,具体如表所示。

2.4 集合set(整数集合intset)
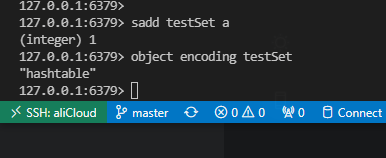
- 改变集合set的数据结构的两要点:
一、节点数量变化由以下配置项决定:
set-max-intset-entries 512 //
set高于512节点都是hash_table字典,低于512节点数据结构是整数集合intset,所以下面的都是整数集合intset的讲解
二、当添加非整形变量时,例如在集合中增加’a’后,testSet的底层编码从intset转换为hash_table
2.4.1 整数集合的实现
- 1.数据结构
//每个intset结构表示一个整数集合
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
encoding //编码方式,encoding属性的值决定了contents数组保存元素的类型,并不是简单的int8_t
length //length属性记录了集合包含的元素数量,也是contents数组的长度
contents //保存元素的数组
- 2.元素存储原理
-特点
1)各个项在数组中按值的大小从小到大有序的排列
2)数组中不包含重复项
3)当一个底层为int16_t整数集合增加一个int64_t类型的元素时,整数集合已有的所有元素都会转换成int64_t类型(下面讲怎么升级,怎么改变元素类型)
2.4.2 升级
2.4.2.1 为什么需要升级
- 当我们将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合里面
2.4.2.2 升级步骤:
- 如果需要升级需要调用intsetUpgradeAndAdd()

-
1).根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间
-
2).将底层数组现有的所有元素都转化为与新元素相同的类型,并将类型转换后的元素放到正确的位置上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变
-
3).将新元素添加到底层数组里面
-
添加元素或删除元素为什么是O(N):因为这个操作可能引起升级,而每次升级都需要对底层所有元素进行类型转换,所以向整数集合添加新元素的时间复杂度为O(N)
2.4.3 升级的好处
提升灵活性
- c语言是静态类型语言,为了避免类型错误,我们通常不会将不同类型的值放在同一个数据结构里面
- 但是整数集合现在可以通过自动升级底层数组来适应新元素,所以我们可以随意的将int16_t、int32_t、或者int64_t类型的整数添加到集合中,而不必担心出现类型错误,做法非常灵活
节约内存
- 举例,只有用到int32_t类型的值,才会将int32_t类型的参数添加到集合中
2.4.4 降级
- 整数集合不支持降级,一旦数组升级,编码就会一直保持升级后的状态
2.4.5 整数集合API
函数形式的API
intset *intsetNew(void); //创建一个新的intset,时间复杂度O(1)
intset *intsetAdd(intset *is, int64_t value, uint8_t *success); //将给定元素添加到整数集合里面,O(N)
intset *intsetRemove(intset *is, int64_t value, int *success); //从整数集合中移除给定元素,O(N)
uint8_t intsetFind(intset *is, int64_t value); //因为底层数组有序,查找可以通过二分查找法来进行,所以复杂度为O(logN)
int64_t intsetRandom(intset *is); //从整数集合中随机返回一个数,O(1)
uint8_t intsetGet(intset *is, uint32_t pos, int64_t *value); //取出底层数组在给定索引上的元素,O(1)
uint32_t intsetLen(const intset *is); //返回整数集合包含的元素个数,O(1),直接返回结构体length的数组就可以
size_t intsetBlobLen(intset *is); //返回整数集合占用的内存字节数,O(1),计算就可以返回了,很快
命令形式的API
1 SADD key member1 [member2] //O(N)
向集合添加一个或多个成员
2 SCARD key //O(1)
获取集合的成员数
3 SDIFF key1 [key2] //O(N)
返回给定所有集合的差集
4 SDIFFSTORE destination key1 [key2] //与SDIFF一样,都是O(N)
返回给定所有集合的差集并存储在 destination 中
5 SINTER key1 [key2] //O(N*M)
返回给定所有集合的交集 //N为给定集合的数量,而M则是所有给定集合当中,包含元素最少的那个集合的大小
6 SINTERSTORE destination key1 [key2] //O(N*M)
返回给定所有集合的交集并存储在 destination 中 7 SISMEMBER key member
判断 member 元素是否是集合 key 的成员
8 SMEMBERS key //O(N)
返回集合中的所有成员
9 SMOVE source destination member //O(1)
将 member 元素从 source 集合移动到 destination 集合
10 SPOP key //O(N)
移除并返回集合中的一个随机元素
11 SRANDMEMBER key [count] //O(1)
返回集合中一个或多个随机数
12 SREM key member1 [member2] //O(N)
移除集合中一个或多个成员
13 SUNION key1 [key2] //O(N)
返回所有给定集合的并集
14 SUNIONSTORE destination key1 [key2] //O(N)
所有给定集合的并集存储在 destination 集合中
15 SSCAN key cursor [MATCH pattern] [COUNT count]
迭代集合中的元素 //
2.4.6 set应用举例
唯一计数器(比如网站的访问量)
- 浏览量记录的是网站页面被用户访问的总次数,网站的每个用户都可以重复地对同一个页面进行多次访问,而这些访问会被浏览量计数器一个不漏地记下来。
- 用户数量记录的是访问网站的 IP 地址数量,即使同一个 IP 地址多次访问相同的页面,用户数量计数器也只会对这个 IP 地址进行一次计数。
- 网站浏览量可以使用字符串键是的计数器进行计数,但想要记录网站的用户数量,就需要构建一个新的计数器,可以用 SET 集合
加入 IP: SADD users:count 202.177.2.232
计算总数:SCARD users:count
点赞
朋友圈点赞:
(1)点赞
sadd like:{消息 Id} {点赞用户 Id}
(2) 取消点赞
srem like:{消息 Id} {点赞用户 Id}
(3) 检查用户是否点过赞
sismember like:{消息 Id} {点赞用户 Id}
(4) 获取点赞用户列表
smembers like:{消息 Id}
(5) 获取点赞用户数量
scard like:{消息 Id}
共同关注和推荐关注
集合操作
(1) 交集
sinter set1 set2 set3 -> {c}
(2) 并集
sunion set1 set2 set3 -> {a,b,c,d,e}
(3) 差集
sdiff set1 set2 set3 -> {a}

集合实现微博/微信关注模型
(1) darren 老师关注的人
sadd darrenSet qiuxiang lee king
(2) qiuxiang 老师关注的人
sadd qiuxiangSet darren ting lee king
(3) king 老师关注的人
sadd kingSet qiuxiang darren ting buding
(4) 我和 qiuxiang 老师共同关注(交集):
sinter darrenSet qiuxiangSet - {lee,king}
(5) 我关注的人是否也关注他(king 老师)
sismember qiuxiangSet king
(6) 我可能认识的人(钉钉 脉脉):
sdiff qiuxiangSet darrenSet - {darren, ting}
投票
- 问答网站、文章推荐网站、论坛这类注重内容质量的网站上通常都会提供投票功能,用户可以通过投票来支持一项内容或者反对一项内容:

- 赞同的时候将用户 SADD 到赞同集合,并将用户从反对集合删除 SREM
抽奖
微信抽奖小程序:
(1) 点击参与抽奖加入集合
sadd key {userId}
(2) 查看参与抽奖所有用户;
smembers key
(3) 抽取 n 名中奖者
srandmember key [n]
或 spop key [n]
2.4.7 整数集合重点回顾
- 整数集合的底层实现为数组,这个数组以有序、无重复的方式保存集合元素,在有需要时,程序会根据新添加元素的类型,改变这个数组的类型
- 升级操作为整数集合带来了操作上的灵活性,并且尽可能节约了内存
- 整数集合只支持升级操作,不支持降级操作














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









