







1、torch.autograd.backward
功能:自动求取梯度
autograd:计算图与梯度求导

2、torch.autograd.grad
功能:求取梯度
• outputs: 用于求导的张量,如 loss
• inputs : 需要梯度的张量
• create_graph : 创建导数计算图,用于高阶求导
• retain_graph : 保存计算图
• grad_outputs:多梯度权重
3、autograd注意事项:
1. 梯度不自动清零
2. 依赖于叶子结点的结点,requires_grad默认为True
3. 叶子结点不可执行in-place
import torch
torch.manual_seed(10)
help(torch.autograd.backward)
Arguments:
tensors (sequence of Tensor): Tensors of which the derivative will be
computed.
grad_tensors (sequence of (Tensor or None)): The "vector" in the Jacobian-vector
product, usually gradients w.r.t. each element of corresponding tensors.
None values can be specified for scalar Tensors or ones that don't require
grad. If a None value would be acceptable for all grad_tensors, then this
argument is optional.
retain_graph (bool, optional): If ``False``, the graph used to compute the grad
will be freed. Note that in nearly all cases setting this option to ``True``
is not needed and often can be worked around in a much more efficient
way. Defaults to the value of ``create_graph``.
create_graph (bool, optional): If ``True``, graph of the derivative will
be constructed, allowing to compute higher order derivative products.
Defaults to ``False``.
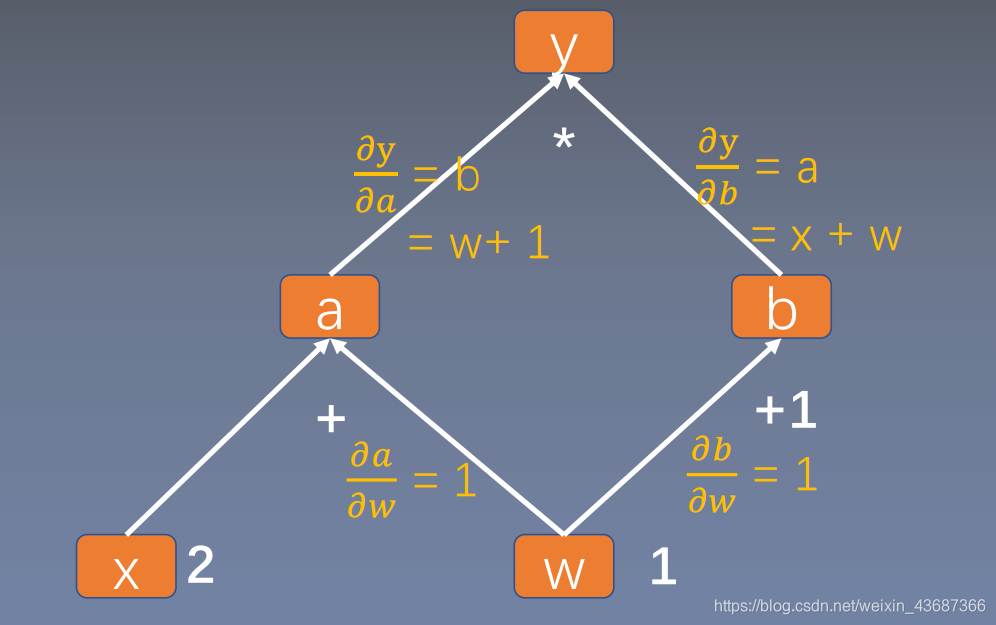
w = torch.tensor([1.],requires_grad=True)
x = torch.tensor([2.],requires_grad=True)
a = torch.add(w,x) # y = w+x
b = torch.add(w,1) # y1 = w+1
y = torch.mul(a,b) # y = (w+x)*(w+1)
# 保存计算图,可以让下面可以继续求反向传播
# 因为不这么做的话,计算图是会自动释放的,下一次用不了
y.backward(retain_graph=True)
print(w.grad)
y.backward(retain_graph=True)
print(w.grad)
y.backward()
print(w.grad)
tensor([5.])
tensor([10.])
tensor([15.])
flag = True
if flag:
w = torch.tensor([1.],requires_grad=True)
x = torch.tensor([2.],requires_grad=True)
a = torch.add(w,x) # w+x
b = torch.add(w,1) # w+1
y0 = torch.mul(a,b) # (w+x)*(w+1)=>w^2 + x*w + w +x=>dy0/dw=2w+x+1=5
y1 = torch.add(a,b) # (w+x)+(w+1)=>2w + x + 1=>dy1/dw=2
loss = torch.cat([y0,y1],dim=0) # [y0,y1]
grad_tensors = torch.tensor([1.,3.]) # y0*1+y1*2=5*1+2*2=9.
# gradient 传入 torch.autograd.backward()中的grad_tensors
loss.backward(gradient=grad_tensors) # 表示多梯度权重,也就是对梯度进行加权值,需要提前给出
print(w.grad)
tensor([11.])
flag = True
if flag:
x = torch.tensor([3.],requires_grad=True)
y = torch.pow(x,2) #求平方操作
# create_graph创建导数计算图,用于高阶求导,如果为false的话,下面的导数计算无法进行
# 而且还会保留grad_fn记录操作过程
grad1 = torch.autograd.grad(y,x,
create_graph=True) # grad_1 = dy/dx = 2x = 2 * 3 = 6
print(grad1)
grad2 = torch.autograd.grad(grad1[0],x,
create_graph=True) # grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
print(grad2)
(tensor([6.], grad_fn=<MulBackward0>),)
(tensor([2.], grad_fn=<MulBackward0>),)
flag = True
if flag:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
# 梯度清零,不清零就会在之前的基础上进行累加
"""
tensor([5.])
tensor([10.])
tensor([15.])
tensor([20.])
"""
# _下划线代表占位操作
w.grad.zero_()
tensor([5.])
tensor([5.])
tensor([5.])
tensor([5.])
flag = True
if flag:
# 一个不行后面都会受到影响
w = torch.tensor([1.], requires_grad=False)
x = torch.tensor([2.], requires_grad=False)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
print(a.requires_grad, b.requires_grad, y.requires_grad)
False False False
flag = True
if flag:
a = torch.ones((1, ))
print(id(a), a)
# 这个id会发生变化
a = a + torch.ones((1, ))
print(id(a), a)
# 这个是占位操作,不会改变
a += torch.ones((1, ))
print(id(a), a)
2108023962648 tensor([1.])
2108023236000 tensor([2.])
2108023236000 tensor([3.])
flag = True
if flag:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
# 叶子节点不可以执行in-place操作
# w.add_(1)
y.backward()
print(w.grad)
tensor([5.])















 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











