






主页视频
适用于电脑端
1. 主页url(包含视频信息)
首先要获取待爬的url(不是网址)
先随便打开主页,点击视频
然后点击F12,或者右键->检查
会出现以下画面:
然后点击network

一般来说是空的:
刷新下网页:
会出现一些东西,先不分析:
点击Fetch/XHR:
再随便点击一个文件会成为如下:
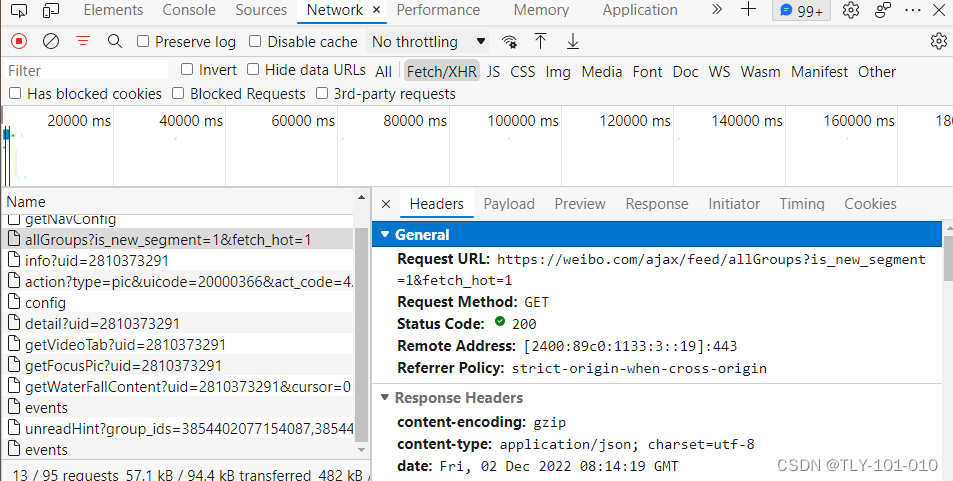
找到Preview标签点击一下
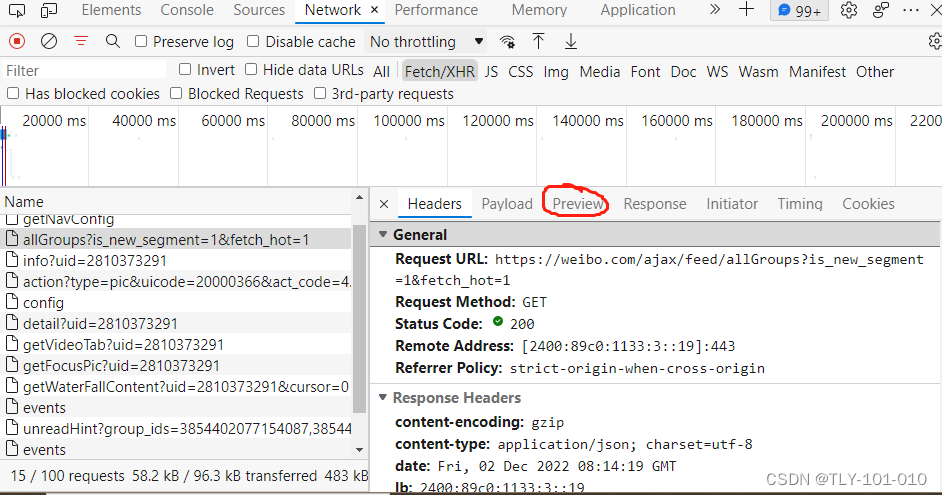
然后在左侧文件列表中找到使得Preview出现大致是这样的文件
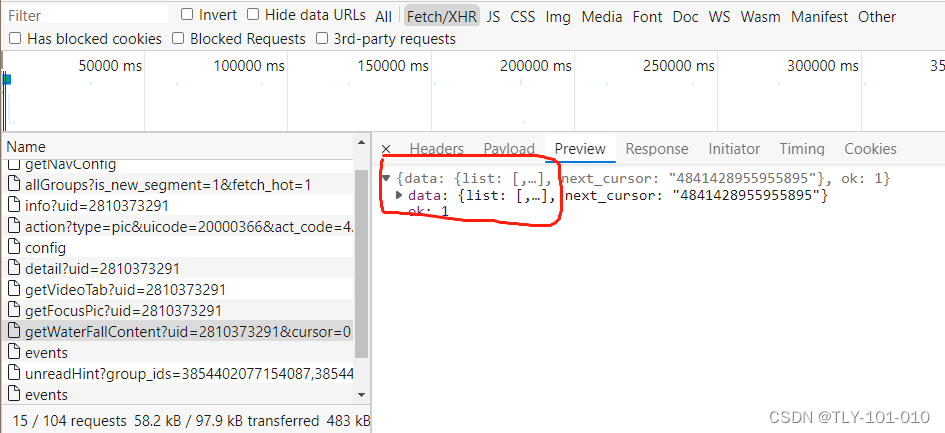
重点是data:{list:… 找到这样的基本就对了,(个人技巧,左侧get开头的文件才能找到)
找到后点击Headers标签:
获取一些必要信息
Request URL:
cookie:
referer:
user-agent:
x-requested-with:
x-xsrf-token:
都在Headers里
其中Request URL:是我们首先需要的url
2.代码开始:
import requests #必要模块不解释
# 必要准备
url = 'Request URL后面的链接'
# 伪装
headers = {
'cookie': '',
'referer': '',
'user-agent': '',
'x-xsrf-token': ''
} # 对应填写
# 发送请求 获取数据
response = requests.get(url, headers=headers)
# 获取数据处理成字典
json_data = response.json()
json_data获得是整体数据其中包含网页的全部内容,处理得到我们所需要的数据
# 解析数据
data_list = json_data['data']['list']
为什么要这样写,点开Preview,看一下结构,逐级向下寻找
list以下的数字代表每个视频的具体信息
用for遍历每个视频信息
for video in data_list:
# 每个视频的ID号取出来
oid=video['page_info']['actionlog']['oid']
# print(oid)
# 拼接url,前面的部分是固定的,后面改变
url_oid ='https://weibo.com/tv/api/component?page=%2Ftv%2Fshow%2F'+ oid
# 要提交的表单数据 #照写的未搞懂
data_oid={
'data':'{"Component_Play_Playinfo":{"oid":"'+oid+'"}}'
}
# 发送请求
response = requests.post(url_oid , headers=headers, data=data_oid)
# print(response) # response[200]
# 获取数据
json_data = response.json()
# print((json_data))
# 解析数据
# 获取视频链接地址
data_list = json_data['data']['Component_Play_Playinfo']['urls']
# print(data_list['高清 1080P'])
for i in data_list: # 为了取出最清晰的视频 data_list包含多个清晰度的视频,一般第一个最高清
video_url='https:'+data_list[i]
# title 有可能重复
title =json_data['data']['Component_Play_Playinfo']['title']
# mid 视频ID,不重复
mid = json_data['data']['Component_Play_Playinfo']['mid']
video_data=requests.get(video_url).content
# 名字可以用title+mid代替:
# with open(f'保存地址/{title}{mid}.mp4', mode='wb') as f:
with open('保存地址/名字.mp4', mode='wb') as f:
f.write(video_data)
break # 跳出for,不重复提取视频















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









