







QT/C++成功调用libtorch的环境配置(2023.7.19)
QT/C++成功调用libtorch的环境配置
背景:和同门一起搭的新系统是基于QT的,如果系统能够直接调用训练好的神经网络,可以提高图像处理的稳定性和速度。之前听说pytorch训练的权重文件可以直接用C的libtorch调用,速度和直接用python的差不多,这不得试试嘛。避坑无数后,在Qt上测试图像分类和图像分割都OK。
版本:
系统:win10
显卡:3080 Ti+cuda11.1+cuDNN v8.0.4
torch: 1.9.1+cu111
QT: 版本6,64位程序
比较深刻的坑有
- 使用和训练网络时,环境对应的pytorch和libtorch版本,以及相应GPU的版本要对应的很好。
- 不管是C++还是Qt,想要成功调用libtorch网络模型,都需要加上一句奇妙的咒语。
- 如果程序能顺利运行,但网络预测的结果不对,考虑是网络输出前后的数据处理问题。
Pytorch 模型训练
下载
训练运行使用的Pytorch和Libtorch版本,以及相应GPU的版本要对应。
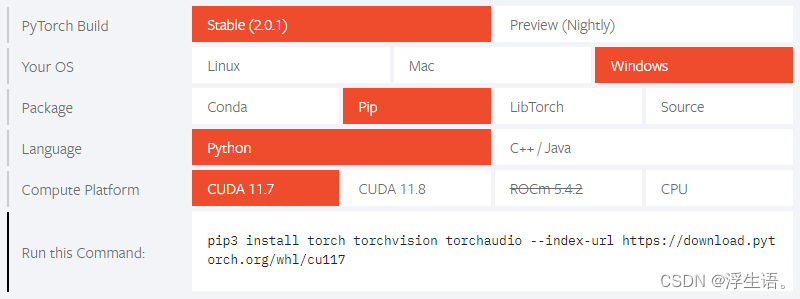
Pytorch下载官网:https://pytorch.org/
考虑到CUDA,我下载的pytorch不是最新版本,过去的合适版本可在https://pytorch.org/get-started/previous-versions/#v182-with-lts-support中找到,并pip下载。
训练
用了图像分类的训练代码做测试,运行简单,训练快。
图像分割用的U-net类方法。
贴上图像分类代码:
import torch
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tqdm import tqdm
'''定义超参数'''
batch_size = 256 # 批的大小
learning_rate = 1e-3 # 学习率
num_epoches = 100 # 遍历训练集的次数
'''
transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.485, 0.456, 0.406 ],
std = [ 0.229, 0.224, 0.225 ]),
])
'''
'''下载训练集 CIFAR-10 10分类训练集'''
train_dataset = datasets.CIFAR10('./data', train=True, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.CIFAR10('./data', train=False, transform=transforms.ToTensor(), download=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
'''定义网络模型'''
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 2
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 3
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 4
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 5
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 6
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 7
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 8
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 9
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 10
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 11
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 12
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 13
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.AvgPool2d(kernel_size=1, stride=1),
)
self.classifier = nn.Sequential(
# 14
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(),
# 15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
# 16
nn.Linear(4096, num_classes),
)
# self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
# print(out.shape)
out = out.view(out.size(0), -1)
# print(out.shape)
out = self.classifier(out)
# print(out.shape)
return out
'''创建model实例对象,并检测是否支持使用GPU'''
model = VGG16()
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
'''定义loss和optimizer'''
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
'''训练模型'''
for epoch in range(num_epoches):
print('*' * 25, 'epoch {}'.format(epoch + 1), '*' * 25) # .format为输出格式,formet括号里的即为左边花括号的输出
running_loss = 0.0
running_acc = 0.0
for i, data in tqdm(enumerate(train_loader, 1)):
img, label = data
# cuda
if use_gpu:
img = img.cuda()
label = label.cuda()
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1) # 预测最大值所在的位置标签
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.item()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(train_dataset))))
model.eval() # 模型评估
eval_loss = 0
eval_acc = 0
for data in test_loader: # 测试模型
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
# 保存模型
torch.save(model.state_dict(), './cnn.pth')
转化
我的模型训练出来是.pth的权重文件,这类文件不能直接被libtorch读取,所以先在pytorch上用torch.jit.trace把.pth转化为.pt文件。
顺便一提,同门的测试,YOLO的pytorch直接训练输出的.pt文件似乎不能直接被libtorch读取,目前只有.pth转换后的.pt可测试成功。
模型转换代码仍参考:
注意:转换需要训练网络的模型结构;转换时是否GPU对输出的.pt文件有影响。
import torch
import torch.nn as nn
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tqdm import tqdm
print(torch.cuda.device_count())
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 2
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 3
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 4
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 5
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 6
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 7
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 8
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 9
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 10
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 11
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 12
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 13
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.AvgPool2d(kernel_size=1, stride=1),
)
self.classifier = nn.Sequential(
# 14
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(),
# 15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
# 16
nn.Linear(4096, num_classes),
)
# self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
# print(out.shape)
out = out.view(out.size(0), -1)
# print(out.shape)
out = self.classifier(out)
# print(out.shape)
return out
'''创建model实例对象,并检测是否支持使用GPU'''
model = VGG16()
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
use_gpu = 1
if use_gpu:
model = model.cuda()
print("model.cuda")
model.eval()
'''测试'''
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 转换模型
model.load_state_dict(torch.load("cnn.pth",map_location=lambda storage, loc: storage.cuda(0)) )
torch.no_grad()
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 32, 32)
if use_gpu:
example = Variable(example).cuda()
# label = Variable(label, volatile=True).cuda()
else:
example = Variable(example)
# label = Variable(label)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
traced_script_module = torch.jit.trace(model, example)
traced_script_module.save("cnn.pt")
libtorch模型使用
下载
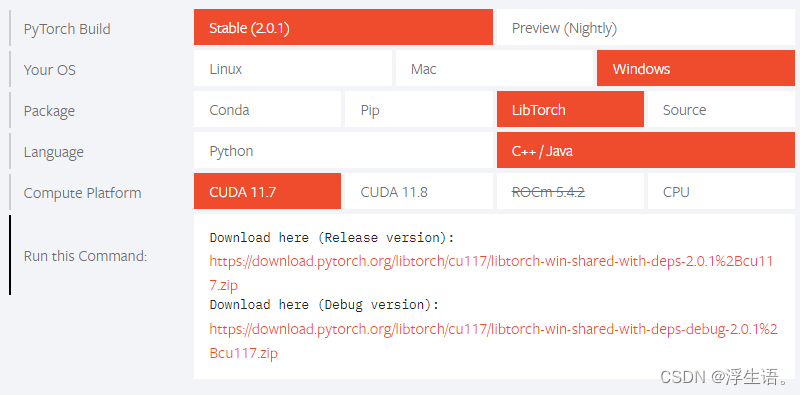
libtorch的下载流程可参考。
注意:
- 下载的Release version 和 Debug version关系到使用C或QT的 Release还是Debug模式才能运行成功,注意对应。
- libtorch对应pytorch同样不是最新版本,可以使用下载链接https://download.pytorch.org/libtorch/cu111/libtorch-win-shared-with-deps-1.9.1%2Bcu111.zip 按格式修改成pytorch 对应版本(即修改链接中的cu版本和torch版本)下载
解压后得到可使用的库
C++使用
我使用VS2019,libtorch基本的使用方法和一般库一样。
- 两个包含目录:
1. D:\libtorch-win-shared-with-deps-1.9.1+cu111\libtorch\include\torch\csrc\api\include
2. D:\libtorch-win-shared-with-deps-1.9.1+cu111\libtorch\include
- 一个库目录:
1. D:\libtorch-win-shared-with-deps-1.9.1+cu111\libtorch\lib
- 一堆链接器->输入->附加依赖项:
(注意加全)
asmjit.lib c10.lib c10_cuda.lib caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib caffe2_nvrtc.lib
Caffe2_perfkernels_avx.lib Caffe2_perfkernels_avx2.lib
Caffe2_perfkernels_avx512.lib clog.lib cpuinfo.lib dnnl.lib
fbgemm.lib fbjni.lib kineto.lib libprotobuf.lib libprotobuf-lite.lib
libprotoc.lib mkldnn.lib pthreadpool.lib pytorch_jni.lib torch.lib
torch_cpu.lib torch_cuda.lib torch_cuda_cpp.lib torch_cuda_cu.lib
XNNPACK.lib
- 一句神奇的魔法咒语,链接器->命令行->其它选项:
大多数贴出的/INCLUDE:?warp_size@cuda@at@@YAHXZ 我用着不行,参考知乎讨论修改为:
1. /INCLUDE:"?ignore_this_library_placeholder@@YAHXZ
- 把libtorch相关的dll文件全部扔进项目里,丑陋但能用:
- 贴入代码
代码是图像分类的,分类之前会确定是否检测到电脑中配置的CUDA,并计算预测速度。
运行要使用GPU用 at::kCUDA,使用CPU则对应修改为at::kCPU
#include "torch/script.h" // One-stop header.
#include <torch/torch.h>
#include <iostream>
#include <opencv2\opencv.hpp>
#include <opencv2\imgproc\types_c.h>
#include<time.h>
using namespace cv;
using namespace std;
int main()
{
/*******load*********/
auto image = imread("dog3.jpg");
imshow("testimg1", image);
waitKey(0);
torch::DeviceType device_type;
device_type = at::kCUDA;
torch::Device device(device_type);
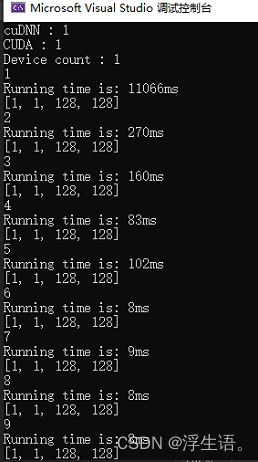
std::cout << "cuDNN : " << torch::cuda::cudnn_is_available() << std::endl;
std::cout << "CUDA : " << torch::cuda::is_available() << std::endl;
std::cout << "Device count : " << torch::cuda::device_count() << std::endl;
torch::jit::script::Module module;
//std::shared_ptr<torch::jit::script::Module> module = torch::jit::load(argv[1], device);
try {
module = torch::jit::load("cpu.pt", device);
}
catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
return -1;
}
vector<string> out_list = { "plane", "ca", "bird", "cat","deer", "dog", "frog", "horse", "ship", "truck" };
if (!image.data)
{
cout << "image imread failed" << endl;
}
cvtColor(image, image, CV_BGR2RGB);
Mat img_transfomed;
resize(image, img_transfomed, Size(32, 32));
torch::Tensor tensor_image = torch::from_blob(img_transfomed.data, { img_transfomed.rows, img_transfomed.cols, img_transfomed.channels() }, torch::kByte);
tensor_image = tensor_image.permute({ 2, 0, 1 });
tensor_image = tensor_image.toType(torch::kFloat);
tensor_image = tensor_image.div(255);
tensor_image = tensor_image.unsqueeze(0).to(at::kCUDA);//����һά����չά�ȣ�����ǰ��
std::vector<torch::jit::IValue> inputs;
inputs.push_back(tensor_image);
torch::Tensor output;
clock_t start_time = clock();
for (int i = 1; i <= 1000; i++)
{
cout << i << endl;
output = module.forward(inputs).toTensor().to(at::kCUDA);
clock_t end_time = clock();
cout << "Running time is: " << static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC * 1000 << "ms" << endl;//输出运行时间
start_time = clock();
}
torch::Tensor output_max = output.argmax(1);
int a = output_max.item().toInt();
cout << "分类预测的结果为:" << out_list[a] << endl;
return 0;
}
- 运行
运行是Debug还是Release需要注意对应libtorch版本。
运行可能会遇到各种问题,需要一步步排查,从代码能运行->能CPU读取权重->能GPU读取权重->模型能输出对的结果。
问题: Torch使用GPU时似乎需要预热,前一两轮预测花费的时间特别长,后续逐渐稳定,不知道有没有改善方法。
Qt使用
下载和使用的代码与C++基本不变。
QT的配置上有所差异,体现为.pro文件的配置语法
注意(奇怪的脾气):
- 加入lib要一个一个加,/*是不行的
- 如果出现dll相关报错,把dll放入项目中
- 别忘了奇妙的咒语:LIBS += -INCLUDE:“?ignore_this_library_placeholder@@YAHXZ”
INCLUDEPATH += D:/libtorch-win-shared-with-deps-1.9.1+cu111/libtorch/include
INCLUDEPATH += D:/libtorch-win-shared-with-deps-1.9.1+cu111/libtorch/include/torch/csrc/api/include
LIBS += -LD:/libtorch-win-shared-with-deps-1.9.1+cu111/libtorch/lib \
-lasmjit \
-lc10 \
-lc10_cuda \
-lcaffe2_detectron_ops_gpu \
-lcaffe2_module_test_dynamic \
-lcaffe2_nvrtc \
-lCaffe2_perfkernels_avx \
-lCaffe2_perfkernels_avx2 \
-lCaffe2_perfkernels_avx512 \
-lclog \
-lcpuinfo \
-ldnnl \
-lfbgemm \
-lfbjni \
-lkineto \
-llibprotobuf \
-llibprotobuf-lite \
-llibprotoc \
-lmkldnn \
-lpthreadpool \
-lpytorch_jni \
-ltorch \
-ltorch_cpu \
-ltorch_cuda \
-ltorch_cuda_cpp \
-ltorch_cuda_cu \
-lXNNPACK
LIBS += -INCLUDE:"?ignore_this_library_placeholder@@YAHXZ"
最后的话
对于训练的不同功能的模型,如果不处理好对应模型的输入数据和输出数据,可能会出现无意义的结果,比如全黑图像。
如果本博客有任何错误或需要补充的内容,也欢迎留言分享,我会加以更正。
最后祝大家都能配置好环境,实现想要的功能!














 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









