







2021年11月新浪微博登录分析
先感叹一下,我2020年开始学习爬虫的时候,第二个模拟登录的网站就是微博,当时自己摸索,虽然网上有很多的文章,但还是决定自己弄出来。
初学,js、浏览器熟悉程度有限,经验也不足,一个简单的微博就把我支配得不要不要的,花了巨多的时间,参考网上文章,一路磕磕碰碰,才弄出来。虽然有点辛苦,但是解决问题之后的兴奋与成就感催动我继续研究js逆向。
后来,偶尔也玩过微博登录,发现无法绕过验证码了,近两年来,各家网站反爬越来越厉害,手机扫码、验证码越来越流行,网站接口隔三岔五更新,爬虫真是越来越难做了。
到了大三,准备找工作了,没了当时要干爬虫的想法,果断跑去卷Java后端了。
Java学习过程中,很多东西其实在爬虫中都有学习过、了解过,爬虫就是干着干着,有各种需求,然后去学习,本人认为这样学习效率是最高的。
所以,虽然没有把爬虫当成职业,但它是我对于这互联网整个行业的一个启蒙吧。
兴趣还是在的,偶尔玩一玩。小爬怡情,大爬伤身,强爬灰飞烟灭。。
下面进入正题,时隔一年多,新浪微博的加密已经是小菜了,但是本文的重点不在于此。
凭证初学的深刻印象,微博应该还是用的rsa加密,先抓波登陆包,因为我们要分析加密,所以选择账号密码登录。
强烈建议抓包之前把网站相关的任何cookie,localStorage删除干净,在chrome浏览器的设置中,删除所有与weibo.com相关的内容,我就是开始这点没做好,多花了大量时间,最好在浏览器设置中与开发工具的Application面板中检查一下
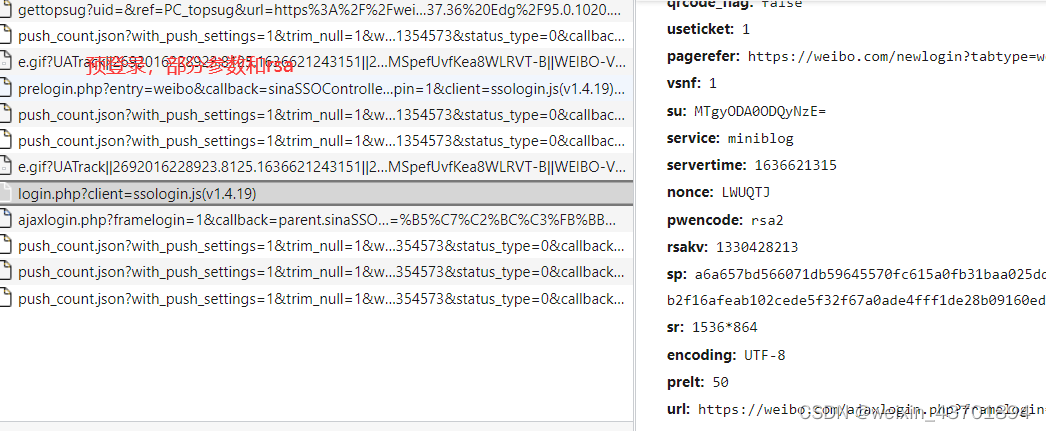
参数还不少,但是经过分析,需要解决的只有下面几个:
- su
- servertime
- nonce
- rsakv
- sp
- prelt
一个个来
su
如果有经验的,很容易猜测这是base64编码的串,应该是对用户名的,然后拿到里面一试,对的。
servertime、nonce、rsakv
这几个参数,都在prelogin那个请求的返回结果里
sp
这个应该就是密码了,怎么找到加密的位置呢,没法查看调用栈,只能用搜的了。
sp这个关键字不好搜,我们可以尝试搜rsa、encrypt等关键字。
运气很好,找到两个关键位置。
这个preloginTime其实就是prelt参数
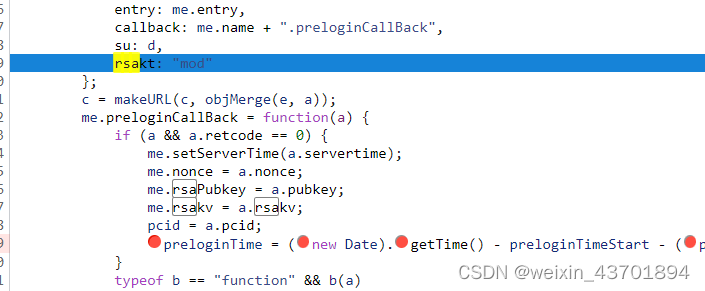
这里是关键的加密位置,直接点进加密函数,整个扣出来
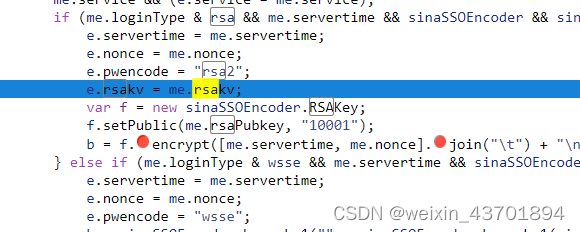
至此。所有参数倒是解决了,试一试能不能登录,返回结果如下
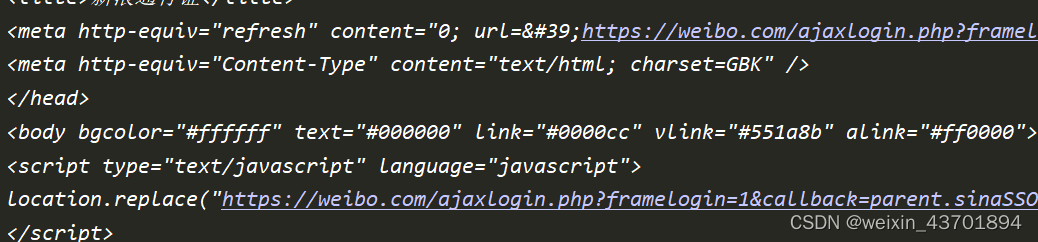
这就是接下来新浪系统的一堆跳转了,能有这个结果证明我们的加密分析是正确的,然后继续请求这个链接,发现他又返回了js代码,没法登录。
SUB && SUBP
当时在这里卡了好久,问题很明显,应该是cookie的问题,用正确的密码登录多次,发现这两个cookie值可能是登录不上的关键。

然后就开始找这两个cookie生成的逻辑,花了挺多时间登录、调试,最后发现就是访问微博,如果检测不到你的SUB、SUBP参数,会重定向到新浪访客系统,然后经历一系列跳转,为客户端生成SUB、SUBP两个cookie,并存储到本地,再返回到weibo.com。我们模拟登录,是没有这个生成SUB、SUBP的,再密码验证通过之后,跳转经过新浪访客系统,发现没有这两个参数,就会返回上面提到的又一段js代码,再经过跳转生成访客身份,设置SUB、SUBP参数,再跳转回微博登录,登录之后,将sina.com.cn的cookie转到weibo.com,具体来说,如下
def _cross_domain(self):
"""
默认cookie是.login.sina.com,转到.weibo.com
:return:
"""
sub = self.session.cookies.get("SUB", domain=".sina.com.cn")
subp = self.session.cookies.get("SUBP", domain=".sina.com.cn")
self.session.cookies.clear(domain=".sina.com.cn", name="SUB", path="/")
self.session.cookies.clear(domain=".sina.com.cn", name="SUBP", path="/")
self.session.cookies.set("SUB", sub, domain=".weibo.com")
self.session.cookies.set("SUBP", subp, domain=".weibo.com")
- 如果浏览器事先的SUB、SUBP没有删除干净的话,登录过程中不会出现模拟登录中的js代码,没法排查问题
- 如果事先删除了,在浏览器一打开weibo.com的时候,就会经过访客系统生成SUB、SUBP,如果不注意这个细节的话,这两个参数的来源就解决不了
- 删除完cookie之后,打开调试工具,再刷新页面;或者全程用fiddler抓包,这两种方法可以抓到SUB、SUBP生成的过程
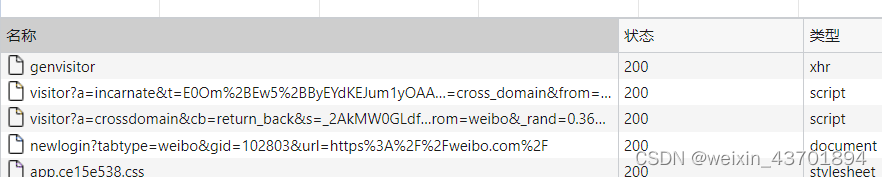
这两个参数解决,后续流程就比较简单了,但还是没法绕开验证码。
总结
- 注意到session对象cookie生成过程中,发现有一些是wei.com下的、一些是sina.com下的,再联系跳转过程中的crossDomainUrlList,可以猜到,新浪访客系统设置了cookie,才能继续访问微博。
- 需要分析cookie的网站,一定要记得删除cookie之后再抓包
- 浏览器不够用的时候,有些包的内容无法查看,使用中间拦截工具。
代码:Github















 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









