






 本文介绍了如何使用curl工具进行大文件下载时的断点续传功能,并提供了一个bash脚本,用于检测下载进度、管理中断情况并自动从上次中断点继续下载。通过Crontab定时器,确保即使下载中断也能自动恢复。
本文介绍了如何使用curl工具进行大文件下载时的断点续传功能,并提供了一个bash脚本,用于检测下载进度、管理中断情况并自动从上次中断点继续下载。通过Crontab定时器,确保即使下载中断也能自动恢复。
背景:项目上需要下载一个 450G的包,下载时间会持续很长,下载比较大的文件,一般需要使用断点续传功能的工具。 curl 工具就是一个具备中断后,接续下载功能的工具。
命令语法:
curl "https://www.fileurl.com" -o file_name -C -
参数解释
-o 后面接 文件名称,下载文件另存的文件名称
-C - 这个意思就是接着前面的位置继续下载
具体使用
下面是展示一个文件在下载过程中, 按下Ctr+c 键中断后,又接着下载
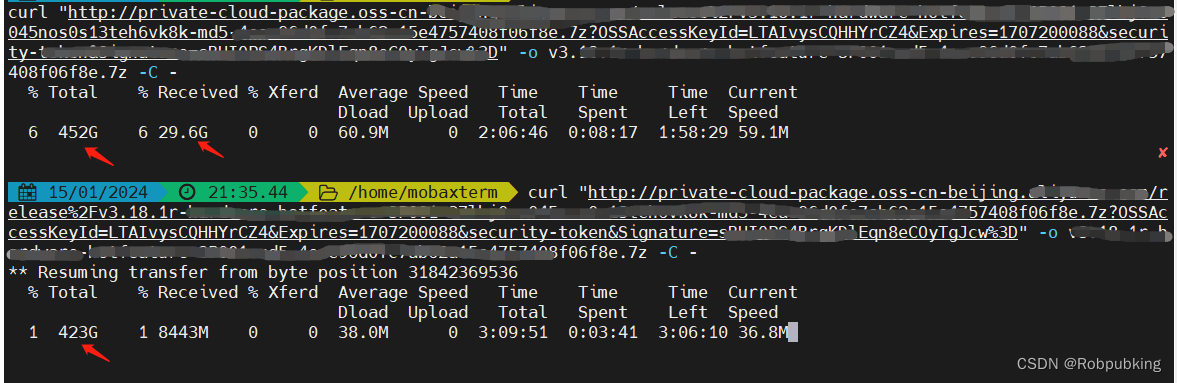
我在另外一个窗口运行 auto-down-load.sh 脚本,效果如下
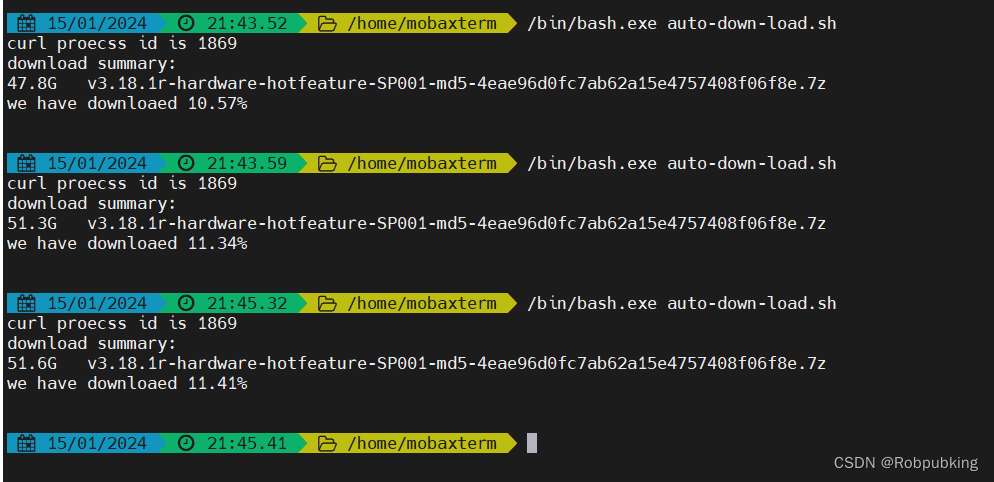
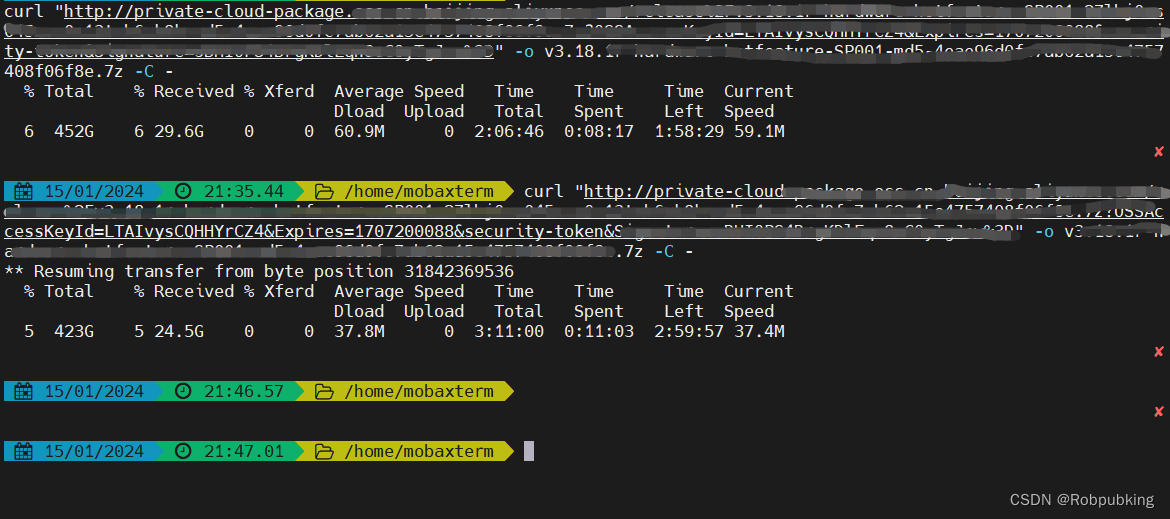
文件下载中断后,执行脚本,文件接着从中断的地方继续下载
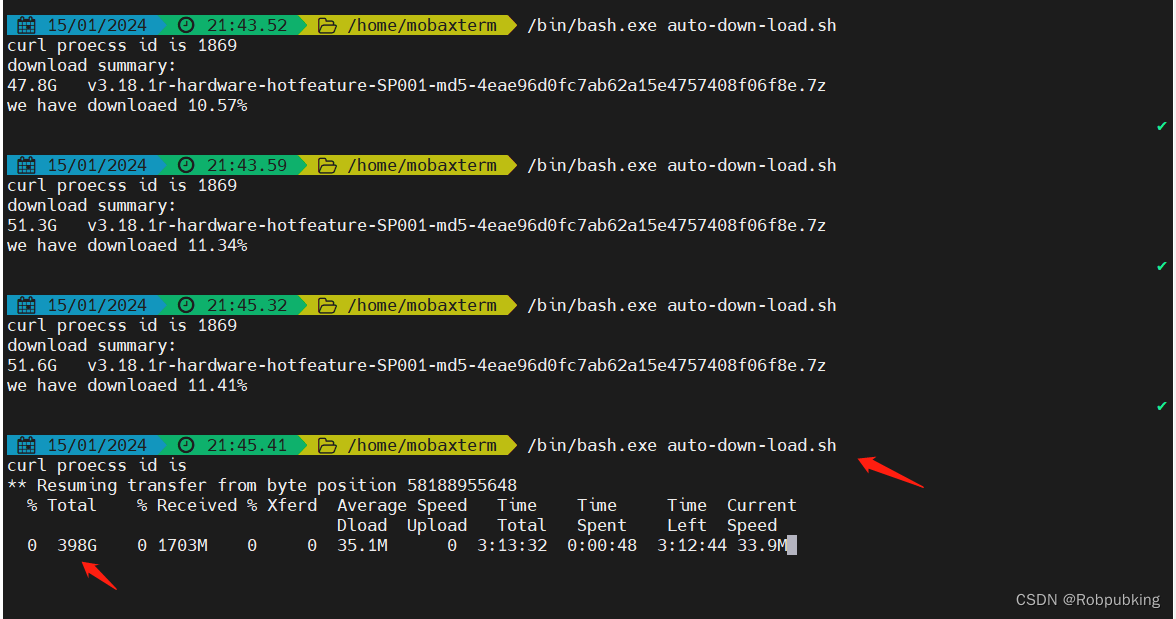
脚本的内容完全复制如下,供读者参考
#/bin/bash
# to see whether the curl process is alive or not
is_downloading=$( ps -ef | grep 'curl' )
# get curl process id
curl_pid=$( echo ${is_downloading} | awk ' { print $2 } ' )
echo "curl proecss id is ${curl_pid} "
# if the curl process is alive, it denotes the file keeps downloading
if [ -n "$is_downloading" ]
then
echo 'download summary:'
du -ah file_name.7z
# to get downloaded file size
down_loaded=$(du -ah file_name.7z | awk ' { print $1 } ' |sed 's/G//')
old_file_size=$( cat file_size.txt )
# store down_loaded filesize to local file
if [ -n "down_loaded" ]
then
echo ${down_loaded} > file_size.txt
fi
# if file_size does not increase with keeping download, resume curl process
if [ "${down_loaded}" = "${old_file_size}" ]
then
kill -9 ${curl_pid} && curl "http://fileurl.com" -o file_name.7z -C -
exit 9
else
# to get the process percentage, keep 2 bits
percentage=$( echo "scale=4;${down_loaded} / 452 * 100" | bc | sed 's/00//' )
echo "we have downloaed ${percentage}%"
fi
else
# if something wrong with download process, start a new download process to continue from where it stopped
curl "http://fileurl.com" -o file_name.7z -C -
fi
脚本主要逻辑:
判断 curl 下载的 进程是否还存活,如果线程存活,继续判断 file_name.7z 文件 的大小有没有变化,如果线程不存活了,或者 下载 文件的大小没有再继续增加了,就表明 之前的下载被中断了,执行 curl “http://fileurl.com” -o file_name.7z -C - 继续下载 。 可以在后台创建一个 crontab 每 5分钟,执行一下 auto-down-load.sh 脚本,如果 下载因为网络原因或者其它因素中断了,就会自动继续下载

















 2298
2298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









