






背景
这个文章只是给一个Flink cdc的效果的一个说明以及一些用法的思考,测试数据是一些虚拟订单数据(可以参考我前面的文章<Python虚拟订单数据创建>)
环境
下载安装pyflink
pip install apache-flink
关于一些PyFlink的写法以及算子的使用可以参考这篇文章
代码
创建流式环境
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(6)
env_settings = EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build()
s_env = StreamTableEnvironment.create(s_env, environment_settings=env_settings)
数据源输入表
s_env.sql_update("""
CREATE TABLE source (
order_id STRING,
customer_name STRING,
order_create_time TIMESTAMP(3),
total_money FLOAT,
order_status STRING,
item_num INT,
province STRING,
city STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/data?autoReconnect=true&serverTimezone = GMT%2B8',
'driver' = 'com.mysql.cj.jdbc.Driver',
'table-name' = 'order_data',
'username' = 'root',
'password' = '***'
)
""")
cdc会通过mysql的binlog日志来获取数据变化,实现一个实时数据计算的效果。
表结构参考虚拟订单创建的文章
数据源输出表
s_env.sql_update("""
CREATE TABLE sink (
customer_name STRING,
sum_total_money FLOAT
) WITH (
'connector' = 'print'
)
""")
执行算子
# 执行转换并收集结果
s_env.sql_update("INSERT INTO sink select customer_name,sum(total_money) as sum_total_money from source group by customer_name")
s_env.execute("Flink-cdc-order")
执行结果
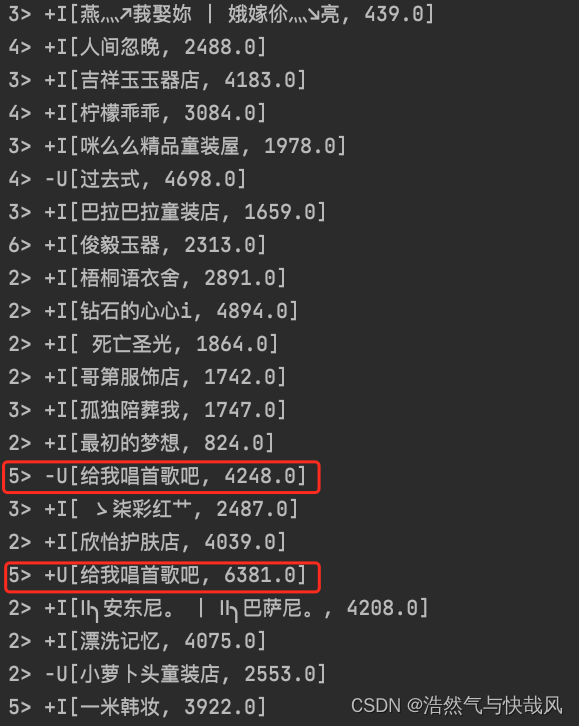
+i 代表 增加insert ,+U代表增加update ,-U代表去除update
从图中可以看见5号线程先去掉了"给我唱首歌吧"的汇总数据,然后更新一条新的计算结果,打印在控制台上。
当然你也可以将sink换成mysql,kafka等其他的数据源
s_env.sql_update("""
CREATE TABLE sink (
customer_name STRING,
sum_total_money FLOAT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/data?autoReconnect=true&serverTimezone = GMT%2B8',
'driver' = 'com.mysql.cj.jdbc.Driver',
'table-name' = '***',
'username' = 'root',
'password' = '***'
)
)
""")
换成mysql数据源之后,一旦你的order_data表数据进行变化,计算结果也会变化之后放入结果表。我们可以通过cdc的这种形式做实时的数据大屏,活动作战室分析,日常分销监控等等的用处。














 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









