








Density Estimation:密度估计 
Cumulative distribution:累计分布函数F(x) 




注意,均值mean E(x) = np, Var(x) = np(1-p)

Continuous distribution:连续分布

连续的边界不重要,离散的边界重要



这里连续变量的PDF(probability density function)概率密度函数不同于上面离散变量的PDF(probality distribution function)概率分布函数。我们的Density Estimation就是去估计一条概率密度曲线。




给定几个独立的来自同一分布的样本点,让我们去估计PDF概率密度曲线。


Parametric density estimation:有参密度估计
我们需要选择哪个分布模型来估计呢?这是一个难点,按下不表。

假设是正态分布,我们要求μ和σ,最少需要知道2个点。

要说似然函数,就要从贝叶斯条件概率说起。似然函数就是吧后验概率转化成先验概率的函数。 


当我们要解决likelihood问题时,就是我们已知样本以及样本分布情况,求原概率分布情况。(第3问就是likelihood问题,第2问就是求概率问题)

从population到sample。population就是概率密度曲线,当我们已知曲线的时候,可以通过pnorm求出sample阴影部分的面积。


Likelihood就是从sample到population的过程:


当只有一个点的sample时,如果是正态分布,一定是x=u的时候,概率最大,但是更多的情况是sample有很多点,比如有4个点。这个时候,就不一定是u最大了。要怎么求4个点的呢?因为他们相互独立,可以将他们的概率相乘。


对数似然函数




Kernel Function是一种特殊的PDF,不满足任何一种分布模型。不同于机器学习的核函数。



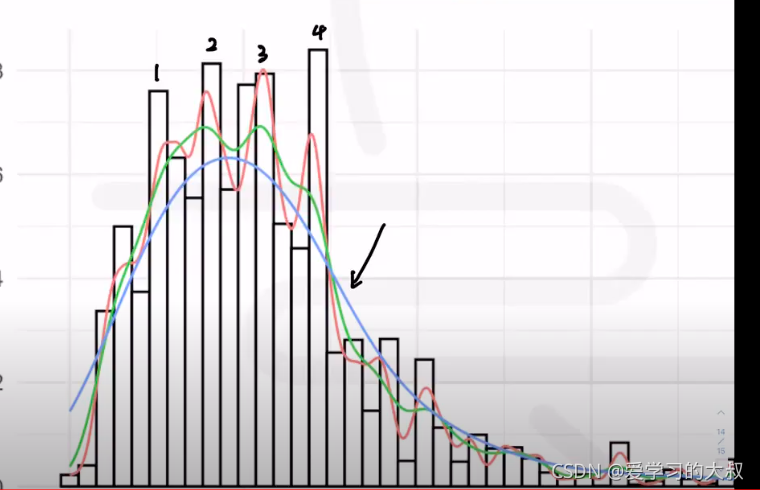
统计直方图是基于sample的,而概率密度曲线是基于populaton的。所以当直方图没有的时候,只是表明sample在这里没有,对曲线有影响,但并不是说概率就是0,只是概率比较低。


核密度估计KDE
公式中1后面表示距离x有h的距离所有点的个数,每一个算作1,有8个点,就是8.


xi是在x左右范围内的点。K是核函数



可以看到不同的KDE画出来的曲线都差不多。




关于h过大或者过小,考过

h过大,4个峰也没了。所以h过大,过于平滑也不好。重要信息丢失/稀释














09-20
 1502
1502
1502
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









