







文章目录
概述
PointPillar+CenterPoint是比较成熟的自动驾驶3D目标检测落地方案。目标跟踪则选用了图森未来的SimpleTrack。本文意在梳理3个模型的原理以及相关重点部分的代码。文章分成上(PointPillar)中(CenterPoint)下(SimpleTrack)3篇。
PointPillar原始论文:
PointPIllar思想
在自动驾驶行业,PointPillar是比较成熟的落地方案,在Transformer之前,应用广泛,精度和速度都兼备,并且可以表现出良好的性能。由于其在CUDA实时推理的优异表现,使得PointPillar可以成为工业界典范。它的主要思想是将点云分成柱子(Pillar),通过PointNet方法对柱子进行Encoder编码,得到伪图像(Pseudo Image)。再利用成熟的2D CNN网络对伪图进行特征提取,进而传递给下游目标检测任务头(Head)。
主体结构
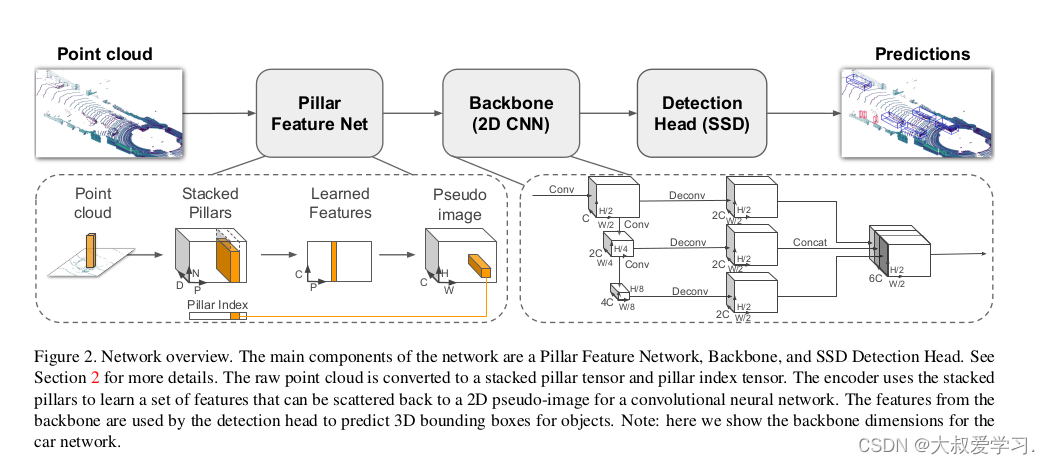
看模型,先看输入输出。输入点云,输出目标检测结果。中间是模型的主体部分:Pillar Feature Net,Backbone(2D CNN),Detection Head(SSD)。下面分别介绍。
Pillar Feature Net(从点云到伪图像的转换)
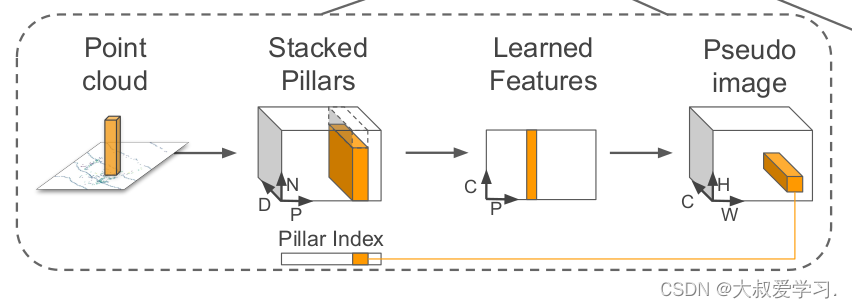
Pillar Feature Net主要功能是对无序化的点云通过柱子(Pillar)的形式进行编码(Encoder)进而得到一个类似图像形式的伪图,之所以说是伪图(CHW),是因为他的通道数不是3维,而是C维。得到伪图后,便可以通过成熟的2D图像框架对伪图进行特征提取,以及下游的目标检测任务。
4个步骤下面做详细解释:
a. Point Cloud:
我们选取Pillar的大小0.2*0.2(单位m),在point cloud range x:[0, 150], y:[-25, 25], z:[-1, 8]范围上进行网格划分。得到[750, 250, 1]的BEV Grid-Map。由于点云的稀疏性,90%以上的格子都是空的,只有少量的Pillar里包含点云,一般会设置最大Pillar个数为12000个(总共187500个格子)。
b. Stacked Pillar:
记录每一个Pillar的index,这在后面会用到。现在操作每一个Pillar。每一个Pillar中的每一个点云Point,本身有4个维度x, y, z, r。(反射强度-归一化)。对点云的维度进行处理。xc, yc, zc表示Pillar中所有点云x, y, z的均值。另外,xp, yp表示当前点云与Pillar中心点的偏移量(offset)。这样一个点云的维度就从4维升到了9维 D=(x, y, z, r, xc, yc, zc, xp, yp)其中N是Pillar中的点云个数,一般取32,如果Pillar点数不够,则用0补全,如果多于32,则采样32个点。这样我们就得到了一个3维的Tensor: [D, P, N]。
c. Learned Feature
作者对处理好的3维Tensor: [D, P, N]通过PointNet和全连接网络进行Pillar的Encoder,得到一个新的Tensor: [C, P, N]。再通过一个Maxpooling操作,把pillar中所有点N进行一个取最大值,这样3维就降到2维Tensor: [C, P]。
上面3步(a, b, c)代码都在类PillarVFE中:
import torch
from torch._C import _is_tracing
import torch.nn as nn
import torch.nn.functional as F
from .vfe_template import VFETemplate
class PFNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
use_norm=True,
last_layer=False):
super().__init__()
self.last_vfe = last_layer
self.use_norm = use_norm
if not self.last_vfe:
out_channels = out_channels // 2
if self.use_norm:
self.linear = nn.Linear(in_channels, out_channels, bias=False)
self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01)
else:
self.linear = nn.Linear(in_channels, out_channels, bias=True)
#self.part = torch.tensor([50000])
def forward(self, inputs):
# comment out for tracing
# if inputs.shape[0] > self.part:
# # nn.Linear performs randomly when batch size is too large
# num_parts = inputs.shape[0] // self.part
# part_linear_out = [self.linear(inputs[num_part*self.part:(num_part+1)*self.part])
# for num_part in range(num_parts+1)]
# x = torch.cat(part_linear_out, dim=0)
# else:
# x = self.linear(inputs)
x = self.linear(inputs) # input: [16000, 32, 10]
torch.backends.cudnn.enabled = False
x = self.norm(x.permute(0, 2, 1)).permute(0, 2, 1) if self.use_norm else x
torch.backends.cudnn.enabled = True
x = F.relu(x) # [16000, 32, 64]
x_max = torch.max(x, dim=1, keepdim=True)[0] # [16000, 1, 64]
if self.last_vfe:
return x_max
else:
x_repeat = x_max.repeat(1, inputs.shape[1], 1)
x_concatenated = torch.cat([x, x_repeat], dim=2)
return x_concatenated
class PillarVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range, **kwargs):
super().__init__(model_cfg=model_cfg)
self.is_tracing = kwargs.get('is_tracing', False)
self.use_norm = self.model_cfg.USE_NORM
self.with_distance = self.model_cfg.WITH_DISTANCE
self.use_absolute_xyz = self.model_cfg.USE_ABSLOTE_XYZ
num_point_features += 6 if self.use_absolute_xyz else 3
if self.with_distance:
num_point_features += 1
self.num_filters = self.model_cfg.NUM_FILTERS
assert len(self.num_filters) > 0
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
for i in range(len(num_filters) - 1):
in_filters = num_filters[i]
out_filters = num_filters[i + 1]
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm, last_layer=(i >= len(num_filters) - 2))
)
self.pfn_layers = nn.ModuleList(pfn_layers)
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1]
self.voxel_z = voxel_size[2]
self.x_offset = self.voxel_x / 2 + point_cloud_range[0]
self.y_offset = self.voxel_y / 2 + point_cloud_range[1]
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1]
def get_paddings_indicator(self, actual_num, max_num, axis=0):
actual_num = torch.unsqueeze(actual_num, axis + 1)
max_num_shape = [1] * len(actual_num.shape)
max_num_shape[axis + 1] = -1
max_num = torch.arange(max_num, dtype=torch.int, device=actual_num.device).view(max_num_shape)
paddings_indicator = actual_num.int() > max_num
return paddings_indicator
def forward(self, batch_dict, **kwargs):
if self.is_tracing:
features = batch_dict['voxels']
else:
# voxel_features: [16000, 32, 4], voxel_num_points: [16000], coords: [16000, 4]
voxel_features, voxel_num_points, coords = batch_dict['voxels'], batch_dict['voxel_num_points'], batch_dict['voxel_coords']
points_mean = voxel_features[:, :, :3].sum(dim=1, keepdim=True) / voxel_num_points.type_as(voxel_features).view(-1, 1, 1)
f_cluster = voxel_features[:, :, :3] - points_mean
# voxel_coords, [B, 4], orders bzyx
f_center = torch.zeros_like(voxel_features[:, :, :3]) # f_center: [16000, 32, 3]
f_center[:, :, 0] = voxel_features[:, :, 0] - (coords[:, 3].to(voxel_features.dtype).unsqueeze(1) * self.voxel_x + self.x_offset)
f_center[:, :, 1] = voxel_features[:, :, 1] - (coords[:, 2].to(voxel_features.dtype).unsqueeze(1) * self.voxel_y + self.y_offset)
f_center[:, :, 2] = voxel_features[:, :, 2] - (coords[:, 1].to(voxel_features.dtype).unsqueeze(1) * self.voxel_z + self.z_offset)
if self.use_absolute_xyz:
features = [voxel_features, f_cluster, f_center]
else:
features = [voxel_features[..., 3:], f_cluster, f_center]
if self.with_distance:
points_dist = torch.norm(voxel_features[:, :, :3], 2, 2, keepdim=True)
features.append(points_dist)
features = torch.cat(features, dim=-1) # features: [16000, 32, 10]
voxel_count = features.shape[1] # 32
mask = self.get_paddings_indicator(voxel_num_points, voxel_count, axis=0)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
features *= mask
for pfn in self.pfn_layers:
features = pfn(features) # features: [16000, 1, 64]
features = features.squeeze(dim=1) # features: [16000, 64]
batch_dict['pillar_features'] = features
return batch_dict
d. Pseudo Image
每个Pillar有C维的通道,这时通过步骤a中记录的index,将PIllar映射回原BEV Grid-Map[C, H, W]。
PointPillarScatter
import torch.nn as nn
from pcdet.utils import common_utils
class PointPillarScatter(nn.Module):
def __init__(self, model_cfg, grid_size, **kwargs):
super().__init__()
self.is_tracing = kwargs.get('is_tracing', False)
self.model_cfg = model_cfg
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES
self.nx, self.ny, self.nz = grid_size
assert self.nz == 1
def forward(self, batch_dict, **kwargs):
pillar_features, coords = batch_dict['pillar_features'], batch_dict['voxel_coords'] # pillar_features: [16000, 4], coords: [16000, 4]
new_grid_size = [self.nz, self.ny, self.nx] # new_grid_size: [1, 256, 256]
batch_dict['spatial_features'] = common_utils.pillarScatterToBEV(pillar_features, coords, new_grid_size, self.num_bev_features, self.is_tracing)
batch_dict.pop("pillar_features") # for tensorrt
return batch_dict
common_utils.pillarScatterToBEV
def pillarScatterToBEV(features:torch.Tensor, coords:torch.Tensor, grid_size:list, num_bev_features:int, is_tracing= False):
'''
scatter pillar feature to bev feature
coords: bzyx
grid_size: zyx
'''
nz, ny, nx = grid_size
assert nz==1
if not is_tracing:
batch_spatial_features = []
batch_size = coords[:, 0].max().int().item() + 1
for batch_idx in range(batch_size):
spatial_feature = torch.zeros( # spatial_feature: [64, 167936(656*256)]
(num_bev_features, nz * nx * ny), # num_bev_features: 64
dtype=features.dtype,
device=features.device)
batch_mask = coords[:, 0] == batch_idx
this_coords = coords[batch_mask, :] # this_coords: [16000, 4]
indices = this_coords[:, 1] + this_coords[:, 2] * nx + this_coords[:, 3] # indices 编码方式
indices = indices.long() # indices: [16000]
pillars = features[batch_mask, :].t() # pillars: [64, 16000]
spatial_feature[:, indices] = pillars # 将pillar的特征,scatter回去 spatial_feature: [64, 167936]
batch_spatial_features.append(spatial_feature)
batch_spatial_features = torch.stack(batch_spatial_features, 0) # batch_spatial_features: [1, 64, 167936]
batch_spatial_features = batch_spatial_features.view(batch_size, num_bev_features*nz, ny, nx) # batch_spatial_features: [1, 64, 256, 656]
else:
# to avoid introduce NonZero op into onnx model
batch_size = 1
batch_spatial_features = torch.zeros(
(num_bev_features, nz * ny * nx),
dtype=features.dtype,
device=features.device)
this_coords = coords
indices = this_coords[:, 1] + this_coords[:, 2] * nx + this_coords[:, 3]
indices = indices.long()
batch_spatial_features[:, indices] = features.t()
batch_spatial_features = batch_spatial_features.view(1, num_bev_features*nz, ny, nx)
return batch_spatial_features
Backbone(2D CNN)
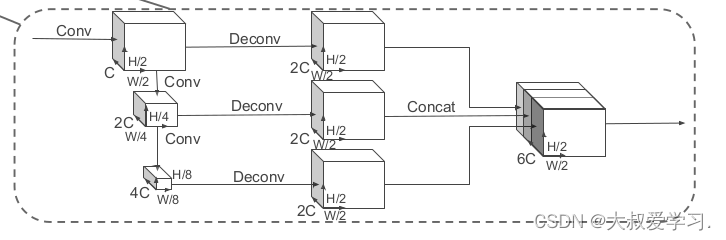
2D Backbone作用是对BEV Map进行特征编码提取,让网络提取出更多的特征供下游网络使用。这里更像是Neck的作用,对不同维度的特征进行融合,以增强模型的泛化能力。
自上而下:
用一系列的Block(S, L, F)。来操作。每过一个Block维度上升1倍,特征图分辨率下降1倍。S是步长,L表示有L个 3 * 3的2D Conv,F表示输出的通道数。每一个Block跟着一个BN和Relu。
上采样(反卷积):
通过Deconv反卷积操作,对上面的每一个Block输出的特征图进行上采样。每一个原始特征图通过反卷积分别得到尺寸同为[H/2, W/2]。通道数为2C 的特征图。最后再将3个相同通道和尺寸的特征图进行Concat连接。输出下游目标检测的输入特征H/2, W/2. 6C]。
import numpy as np
import torch
import torch.nn as nn
class BaseBEVBackbone(nn.Module):
def __init__(self, model_cfg, input_channels, **kwargs):
super().__init__()
self.model_cfg = model_cfg
if self.model_cfg.get('LAYER_NUMS', None) is not None:
assert len(self.model_cfg.LAYER_NUMS) == len(self.model_cfg.LAYER_STRIDES) == len(self.model_cfg.NUM_FILTERS)
layer_nums = self.model_cfg.LAYER_NUMS
layer_strides = self.model_cfg.LAYER_STRIDES
num_filters = self.model_cfg.NUM_FILTERS
else:
layer_nums = layer_strides = num_filters = []
if self.model_cfg.get('UPSAMPLE_STRIDES', None) is not None:
assert len(self.model_cfg.UPSAMPLE_STRIDES) == len(self.model_cfg.NUM_UPSAMPLE_FILTERS)
num_upsample_filters = self.model_cfg.NUM_UPSAMPLE_FILTERS
upsample_strides = self.model_cfg.UPSAMPLE_STRIDES
else:
upsample_strides = num_upsample_filters = []
num_levels = len(layer_nums)
c_in_list = [input_channels, *num_filters[:-1]]
self.blocks = nn.ModuleList()
self.deblocks = nn.ModuleList()
for idx in range(num_levels):
cur_layers = [
nn.ZeroPad2d(1),
nn.Conv2d(
c_in_list[idx], num_filters[idx], kernel_size=3,
stride=layer_strides[idx], padding=0, bias=False
),
nn.BatchNorm2d(num_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
]
for k in range(layer_nums[idx]):
cur_layers.extend([
nn.Conv2d(num_filters[idx], num_filters[idx], kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(num_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
])
self.blocks.append(nn.Sequential(*cur_layers))
if len(upsample_strides) > 0:
stride = upsample_strides[idx]
if stride >= 1:
self.deblocks.append(nn.Sequential(
nn.ConvTranspose2d(
num_filters[idx], num_upsample_filters[idx],
upsample_strides[idx],
stride=upsample_strides[idx], bias=False
),
nn.BatchNorm2d(num_upsample_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
))
else:
stride = np.round(1 / stride).astype(np.int)
self.deblocks.append(nn.Sequential(
nn.Conv2d(
num_filters[idx], num_upsample_filters[idx],
stride,
stride=stride, bias=False
),
nn.BatchNorm2d(num_upsample_filters[idx], eps=1e-3, momentum=0.01),
nn.ReLU()
))
c_in = sum(num_upsample_filters)
if len(upsample_strides) > num_levels:
self.deblocks.append(nn.Sequential(
nn.ConvTranspose2d(c_in, c_in, upsample_strides[-1], stride=upsample_strides[-1], bias=False),
nn.BatchNorm2d(c_in, eps=1e-3, momentum=0.01),
nn.ReLU(),
))
self.num_bev_features = c_in
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features
Returns:
"""
spatial_features = data_dict['spatial_features'] # spatial_features: [1, 64, 256, 656]
ups = []
x = spatial_features
for i in range(len(self.blocks)): # len(self.blocks): 3
x = self.blocks[i](x) # 每个block: 1个ZeroPad2d, 3个conv2d, BN, Relu组合
if len(self.deblocks) > 0: #len(self.deblocks): 3
ups.append(self.deblocks[i](x)) # 每个deblock: 1个ConvTranspose2d, BN, Relu
else:
ups.append(x)
if len(ups) > 1: # ups存了3个反卷积之后的特征,每个: [1, 128(2C), 128(H), 328(W)]
x = torch.cat(ups, dim=1) # x: [1, 384(6C), 128, 328]
elif len(ups) == 1:
x = ups[0]
if len(self.deblocks) > len(self.blocks):
x = self.deblocks[-1](x)
data_dict['spatial_features_2d'] = x
data_dict.pop("spatial_features") # for tensorrt
return data_dict
Detection Head(SSD)
由于本项目下游目标检测使用的CenterPoint的Head头。所有这里只讲一下原理部分。具体实战代码请看中篇(CenterPoint)。
PointPillar的主要思想其实已经在上面讲完,为了完成端到端的训练,PointPillar使用了SSD作为Detection Head。SSD是基于Anchor的方法做回归。输出每个Anchor的类别,位置,大小,角度。与SSD类似,这里只采用2D IOU匹配GT和Anchor。目标框的高度不参与匹配,但参与到了回归当中。
关于Anchor:
这里多说一些,点云和图像的Anchor设计机制有些不同。图像是透视结构,物体的大小会随着距离大小很大变化。物体形状在不同角度也会有差别。不同物体类别,大小和长宽比也会不一样。所以需要设计不同大小的Anchor,来识别不同远近,不同类别的目标。
3种不同的长宽比。1:1,2:1,1:2.每个有3个不同的尺度。每个位置有9个anchor,来适应不同类别,不同大小,不同长宽比的物体。
但是点云是俯视图,点云如果采用前视图的方式,Anchor设计与图像比较类似,但是基于俯视图的Anchor设计会有点不同。俯视图,物体大小和长宽比都是不变的,都是对应真是世界坐标系下的大小。同一物体,基本上也不会差别太大。这时候设计Anchor,就是根据不同类别设计。比如车辆的Anchor或者行人的Anchor。一般定义一个0度的Anchor,和一个90度的Anchor。Anchor越多,效果越好,计算量也就越大。Anchor是3D的,有长宽高信息。在与gt匹配时,我们高度信息是忽略的。如果anchor与gt高于IOU,就是positve的anchor,否则就是negative的anchor。
在俯视图下,不同类别,大小差别比较大。这对Anchor的positive和negative差别会很大。所以车辆的IOU的threshold会高一些,行人的threshold会低一些。更容易找到正样本。
损失函数
PointPillar使用了和SECOND一样的损失函数,公式如图4,其中gt表示ground truth,a表示anchor。所以回归的是gt与anchor的差值(residuals)。其中 da为缩放因子,公式图中已给出。另外回归差值(residuals)是7个值的smoothL1的求和。Classification用了Focal Loss。

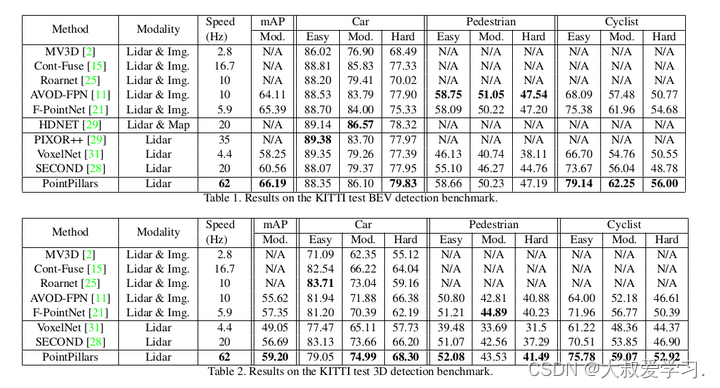
评价指标
从指标看,PointPillar会比基于Voxel的SECOND好,但是我们实际项目用,还是用了3d 稀疏卷积的SECOND更好一些。另外,nvidia也开源了3d spconv的库,可以进行实时推理。不过我和领导探讨了这个问题,他讲,如果我们说一个行人的话,在激光雷达点云质量有限的情况下,根据经验,还是PointPillar好一些。工程上面的答案,还要去实际操作才有结论。

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









