







文章目录
41 不平衡数据是否会影响神经网络的分类效果?
当数据集不平衡时(如一个类的样本比另一个类还多),那么神经网络可能就无法学会如何区分这些类。
参见《常见类别不均衡解决方法》:
https://zhuanlan.zhihu.com/p/166232820
参见《类别不平衡问题全面总结》:
https://zhuanlan.zhihu.com/p/306040236
参见《分类中解决类别不平衡问题》:
https://blog.csdn.net/program_developer/article/details/80287033
41 无监督降维提供的是帮助还是摧毁?
当处理非常高维的数据时,神经网络可能难以学习正确的分类边界。在这些情况下,可以考虑在将数据传递到神经网络之前进行无监督的降维。
参见《基于神经网络进行数据降维》:
https://zhuanlan.zhihu.com/p/453444431
参见《神经网络中的降维和升维方法 (tensorflow & pytorch)》:
https://blog.csdn.net/qq_34218078/article/details/112424172
42 是否可以将任何非线性作为激活函数?
根据万能逼近定理(Universal Approximation Theory),神经网络能以任意精度逼近连续函数。线性函数的线性组合还是线性函数,所以线性函数不能以任意精度逼近连续函数。
训练神经网络时,先随机初始化卷积核参数,把卷积层的结果输入激活函数层,达到某个阈值则激活该神经元,否则设置为0(ReLU),之后进入池化层。把池化层的输出与真值相减,得到损失函数loss,沿着loss的负梯度方向反向传播,更新卷积核参数。
如果没有非线性激活函数的话,多层神经网络和一层神经网络是一样的,都是卷积核的线性组合[1]。
参见《非线性激活函数( Activation Function)》:
https://zhuanlan.zhihu.com/p/260970955


43 批大小如何影响测试正确率?
方法:我们生成两个 12 维高斯混合。高斯具有相同的协方差矩阵,但在每个维度上都有一个由 1 隔开的均值。该数据集由 500 个高斯组成,其中 400 个用于训练,100 个用于测试。我们在这个数据集上训练一个神经网络,使用不同的批大小,从 1 到 400。我们测量了之后的正确率。假设:我们期望较大的批大小会增加正确率(较少的噪声梯度更新),在一定程度上,测试的正确率将会下降。我们预计随着批大小的增加,运行时间应有所下降。


结论:正如我们预期那样,运行时间确实随着批大小的增加而下降。然而,这导致了测试正确率的妥协,因为测试正确率随着批大小的增加而单调递减。讨论:这很有趣,但这与普遍的观点不一致,严格来说,即中等规模的批大小更适用于训练。这可能是由于我们没有调整不同批大小的学习率。因为更大的批大小运行速度更快。总体而言,对批大小的最佳折衷似乎是为 64 的批大小。
参见《深度学习中的batch的大小对学习效果有何影响?》:
https://www.zhihu.com/question/32673260
参见《Batch_size参数的作用:决定了下降的方向》:
https://www.cnblogs.com/demo-deng/p/10189630.html
44 初始化如何影响训练?
神经网络中的参数是基于梯度下降法进行优化的,通过一步步迭代,求得最小的损失函数和最优的模型权重。网络训练之前会给每个参数赋一个初始值。
对一些简单的机器学习模型,或当损失函数是convex function时,零初始化和随机初始化方法是有效的。然而对于深度学习而言,非线性函数疯狂叠加,产生很复杂的non-convex function,合适的参数初始值对于模型的收敛至关重要。
参见《神经网络初始化方式》:
https://zhuanlan.zhihu.com/p/336706725
参见《神经网络参数初始化的学问》:
https://zhuanlan.zhihu.com/p/39076763
45 不同层的权重是否以不同的速度收敛?
这道题不知道怎么回答。网上没找到合适的答案,下面找了一些相关的回答,但无法回答本题。这道题需要做实验回答吧。
参见《深度神经网络中不同超参数的调整规则》:
https://www.sohu.com/a/337191494_468740
参见《神经网络不收敛的 11 个原因》:
https://zhuanlan.zhihu.com/p/369716572
46 正则化如何影响权重?
在神经网络出现high variance也就是overfitting的时候,regularization(正则化)是一个很常用的方法。现在应用最为广泛的包括两种regularization方式:L1/L2 regularization,dropout regularization。
参见《神经网络正则化(1):L1/L2正则化》:
https://zhuanlan.zhihu.com/p/35893078
参见《聊聊神经网络中的正则化》:
https://zhuanlan.zhihu.com/p/36794078
参见《小结深度学习中的正则化(超详细分析)》:
https://blog.csdn.net/qq_16137569/article/details/81584165
参见《DNN的L1&L2正则化》:
https://www.cnblogs.com/pinard/p/6472666.html
47 多标签loss


参见《多标签分类、BCELoss和BCEWithLogitsLoss用法》:
https://blog.csdn.net/qq_36201400/article/details/109490010
参见《深度学习基础----损失函数:BCELoss,BCEWithLogitsLoss,BPRLoss,TOP1Loss》:
https://blog.csdn.net/weiwei935707936/article/details/109518612
48 多标签分类的准确率

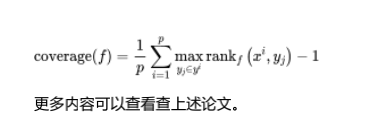

49 数据类不平衡

参见《分类中解决类别不平衡问题》:
https://blog.csdn.net/program_developer/article/details/80287033
50 欠拟合和过拟合


参见《如何防止过拟合和欠拟合》:
https://zhuanlan.zhihu.com/p/85373781
参见《欠拟合、过拟合及如何防止过拟合》:
https://zhuanlan.zhihu.com/p/72038532
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









