






目录
1.简介
数据基本信息
本数据集中包含 1 万余条电影信息,信息来源为“电影数据库”(TMDb,The Movie Database),包括21个特征指标:id、热度、票房、预算、片名、演职人员、导演、类型、用户评分、评分人数、发行时间等21个特征。*
时间:1960-2015年
主要分析数据
热度(popularity)、预算(budget),电影类型(genre),上映时间(release_date),票房收入(revenue ),平均评分(vote_average),评分次数(vote_count)*
分析内容
分析工具:python、Power BI
2.分析结果
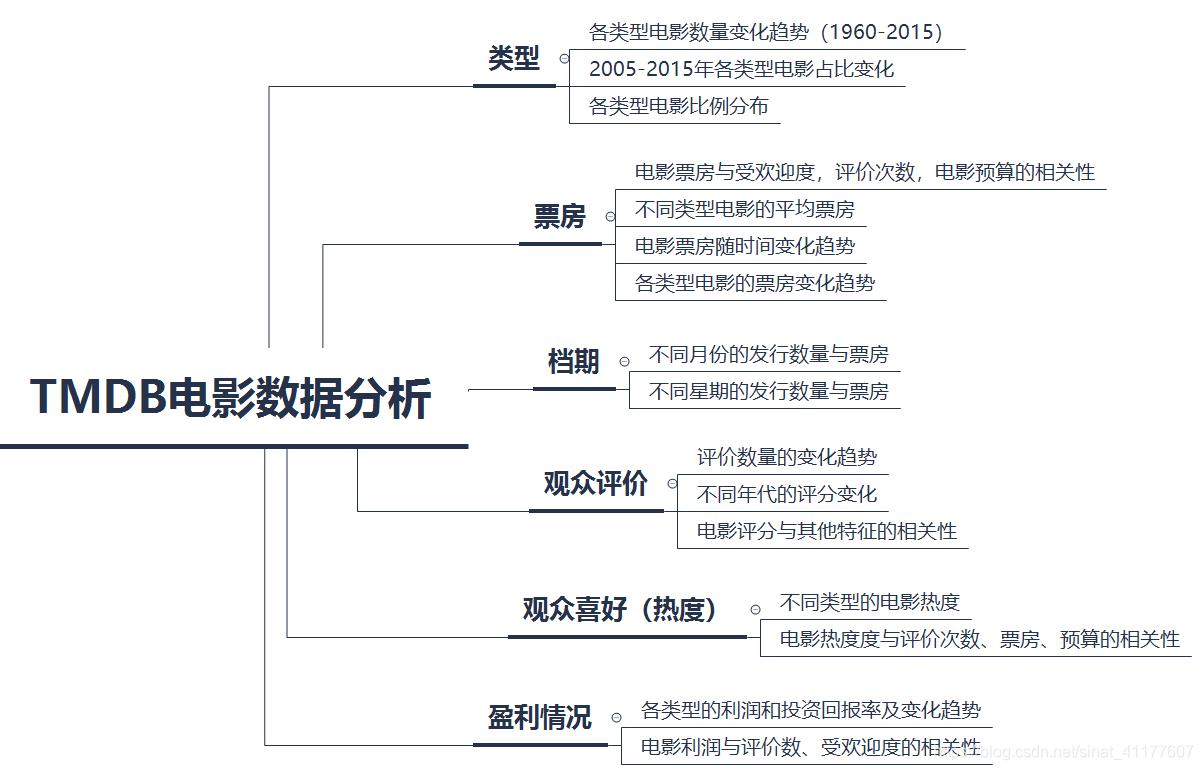
2.1 电影类型(市场分布)
2.2 票房

2.3 档期
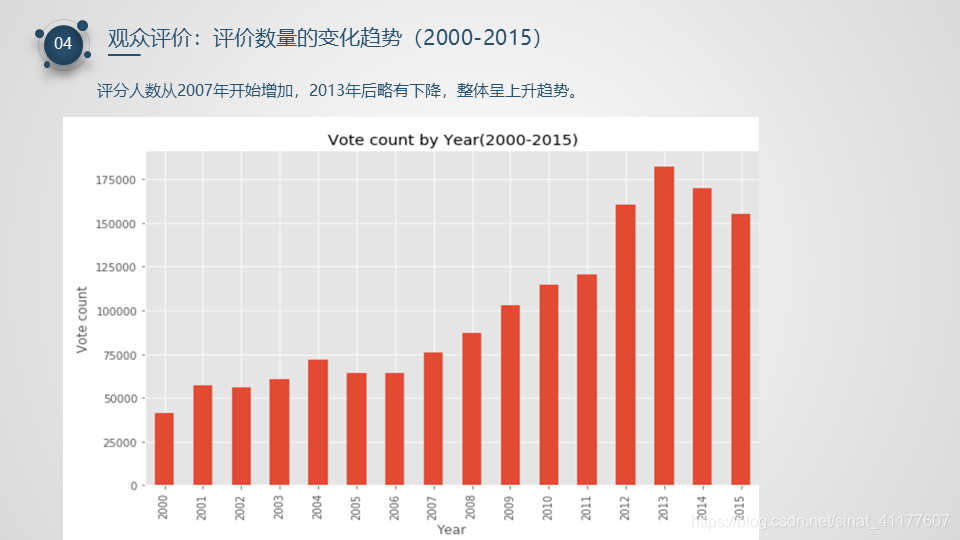
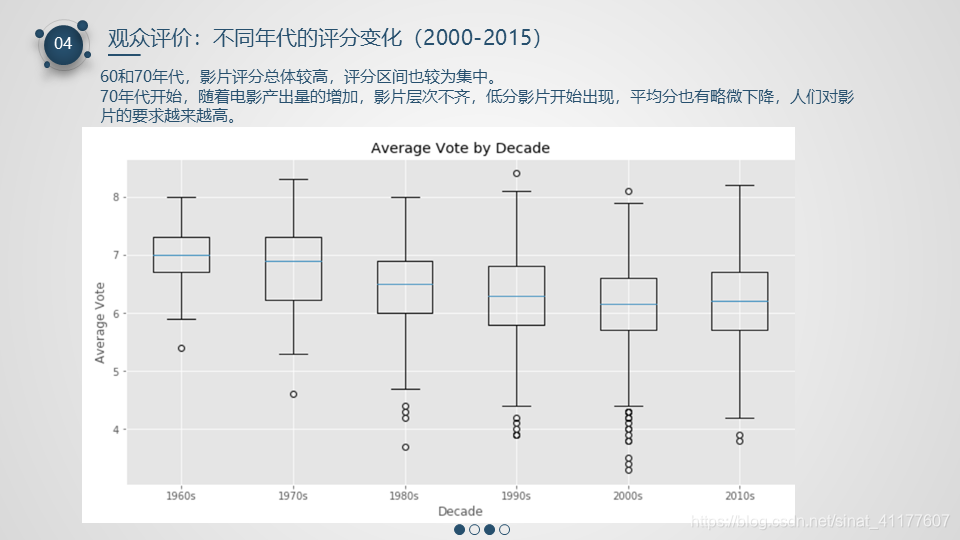
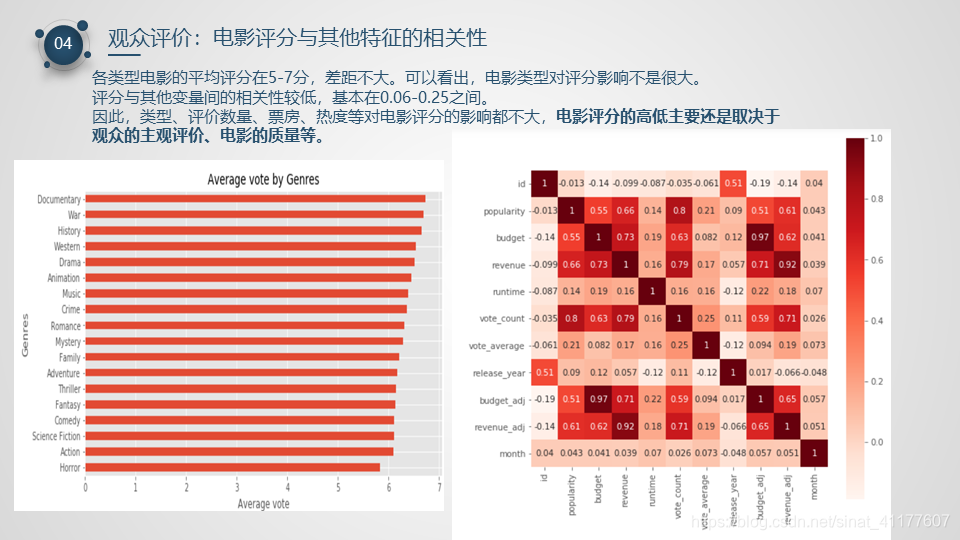
2.4 观众评价(评分&评价人数)
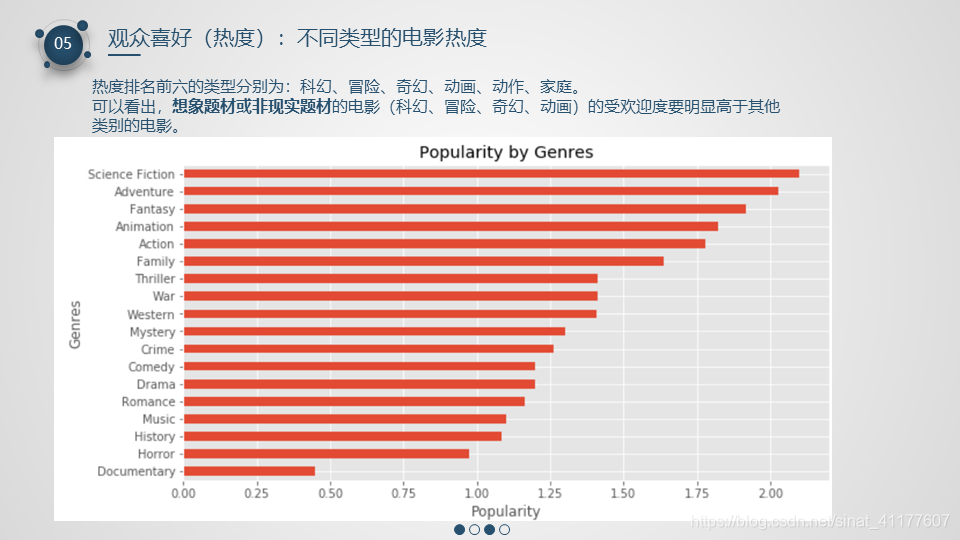
2.5 观众喜好(热度)
2.6 盈利情况
3. 结论
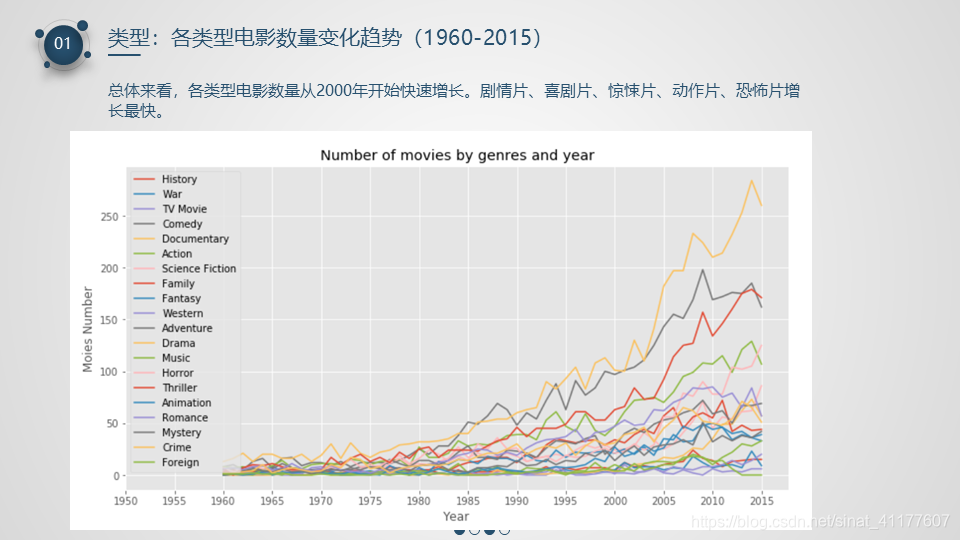
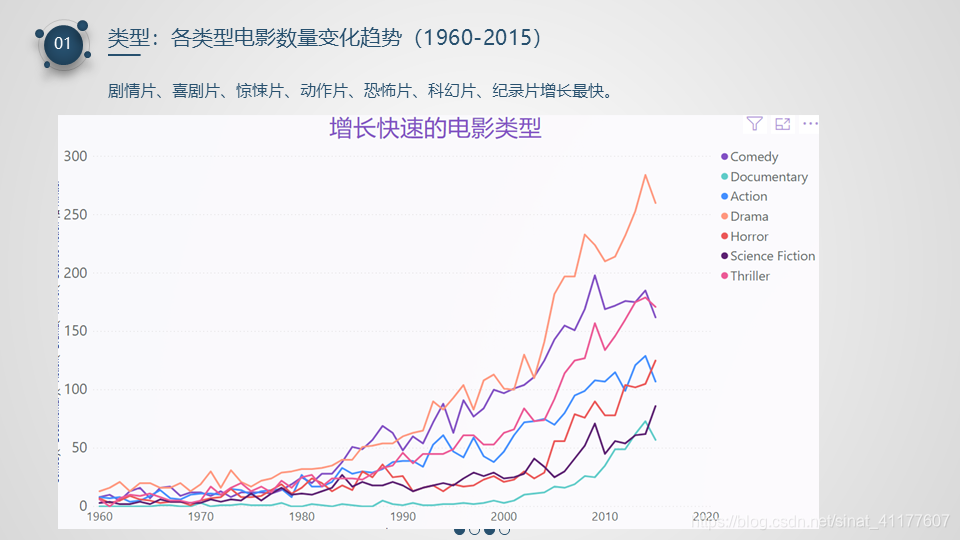
1、电影类型:
- 总体来看,电影数量从2000年开始快速增长,其中剧情片、喜剧片、惊悚片、动作片、恐怖片、科幻片、纪录片增长最快。
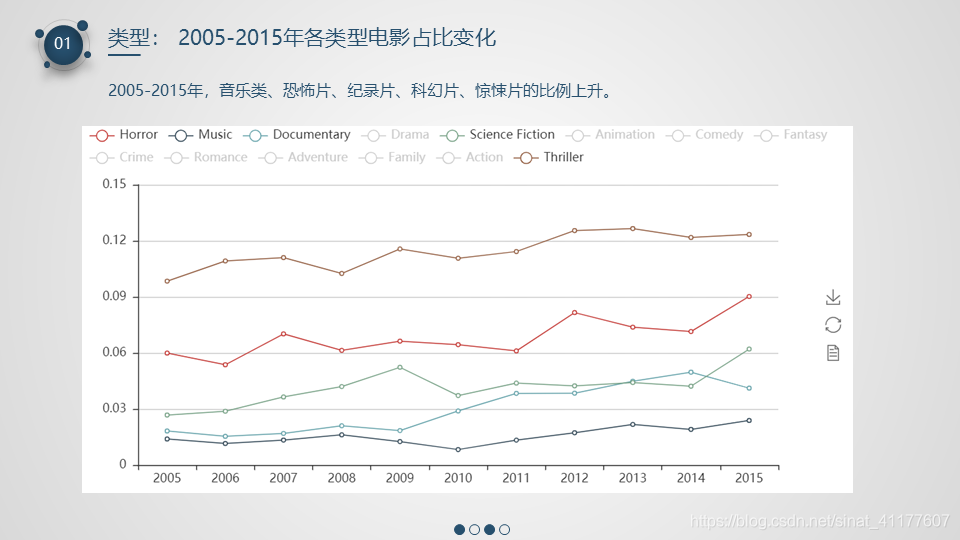
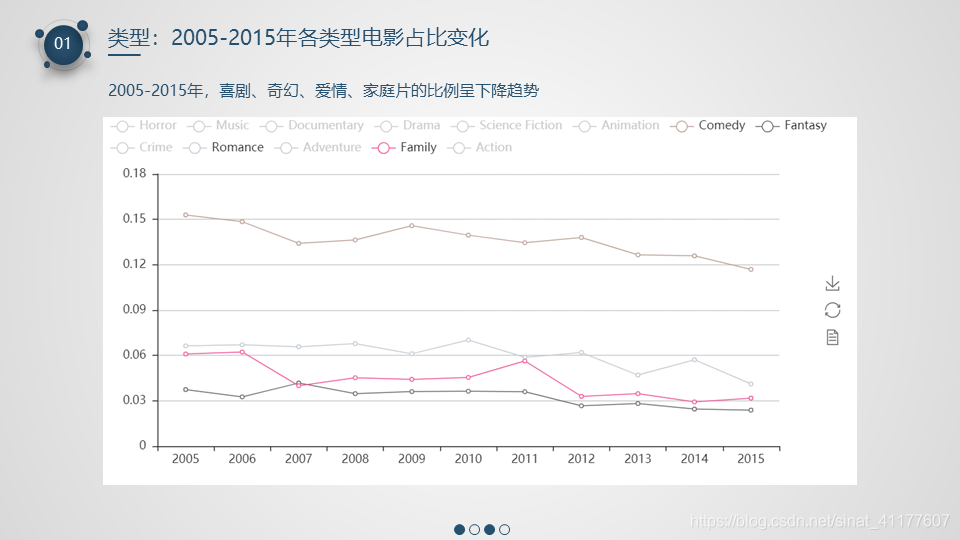
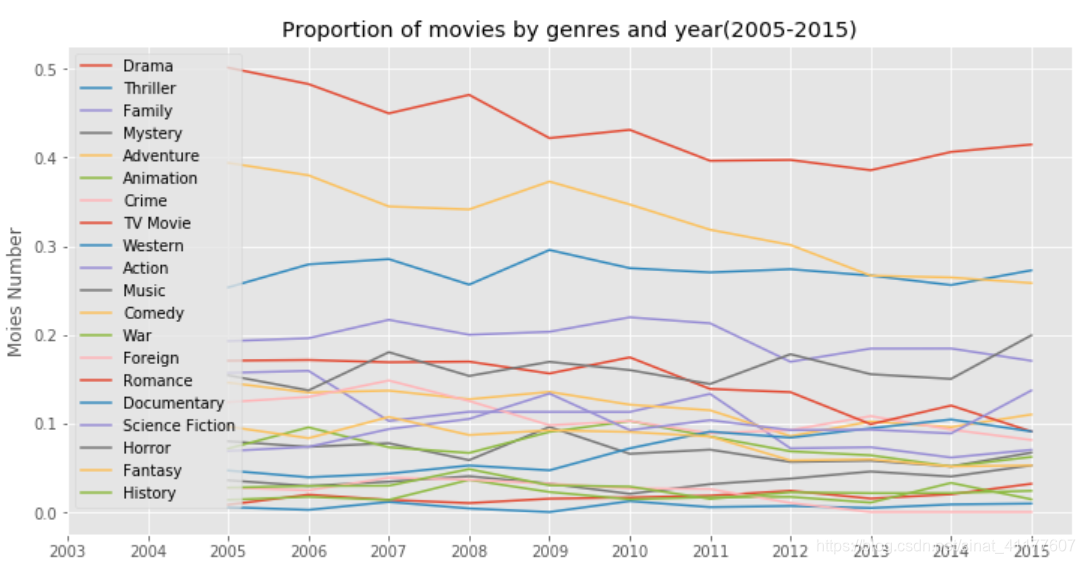
- 2005-2015年,喜剧、奇幻、爱情、家庭片的比例呈下降趋势,音乐类、恐怖片、纪录片、科幻片、惊悚片的比例上升。
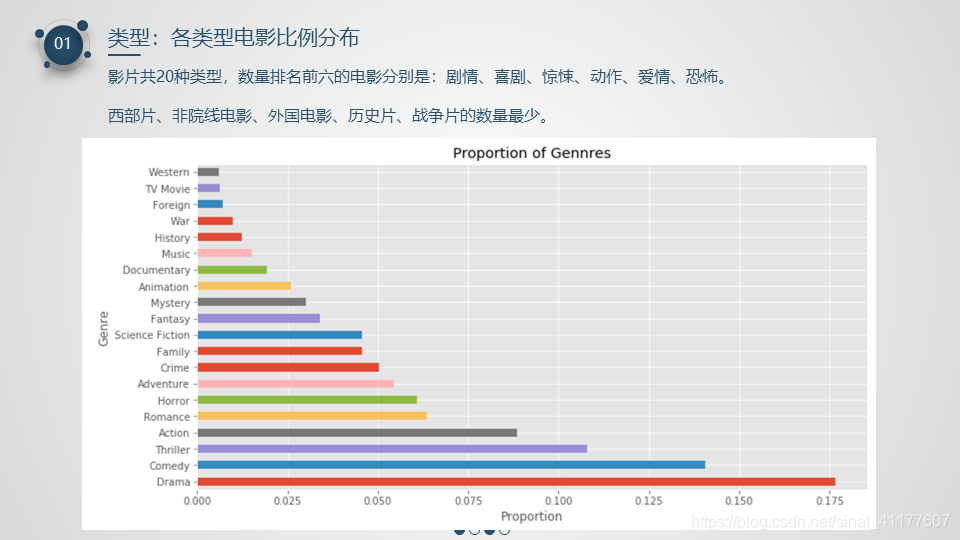
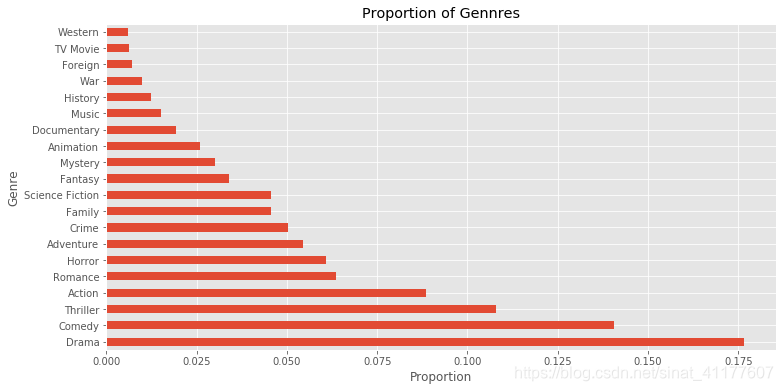
- 在20种电影类型中,数量排名前六的电影分别是:剧情、喜剧、惊悚、动作、爱情、恐怖。数量最少的是西部片、非院线电影、外国电影、历史片、战争片。
2、票房:
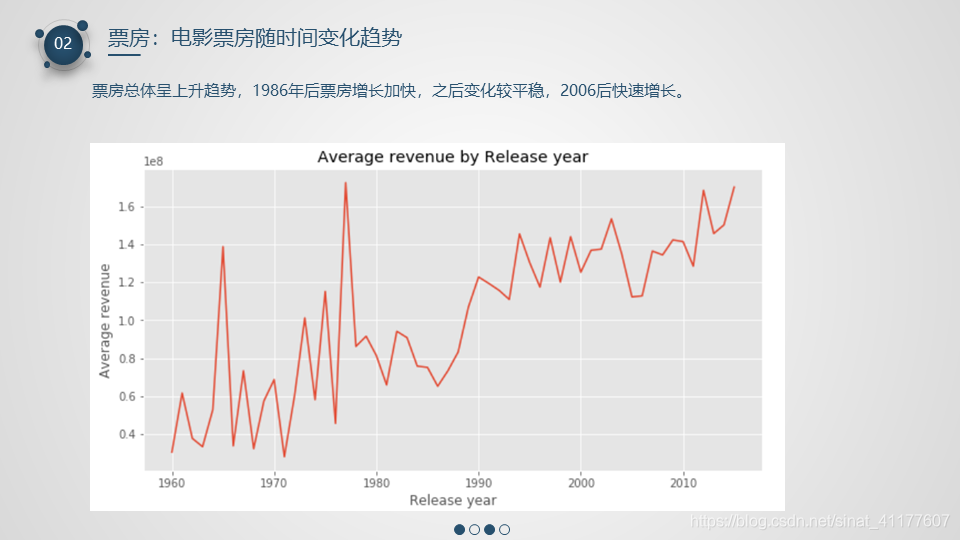
- 票房总体呈上升趋势,1986年后票房增长加快,之后变化较平稳,2006后快速增长。
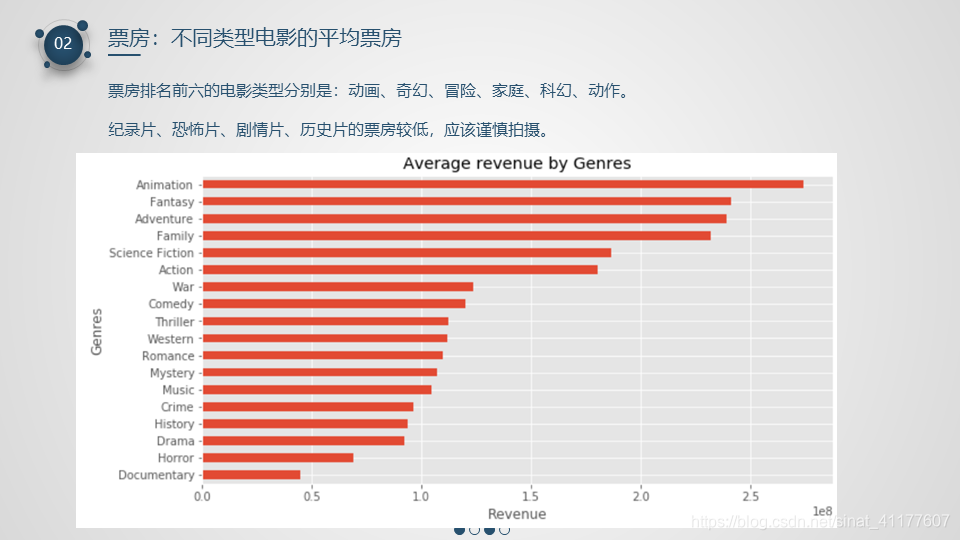
- 票房排名前六的电影类型分别是:动画、奇幻、冒险、家庭、科幻、动作,其变化趋势较平缓。其中冒险、动作呈下降趋势。 而纪录片、恐怖片、外国片、剧情片、历史片的票房较低,应该谨慎拍摄。
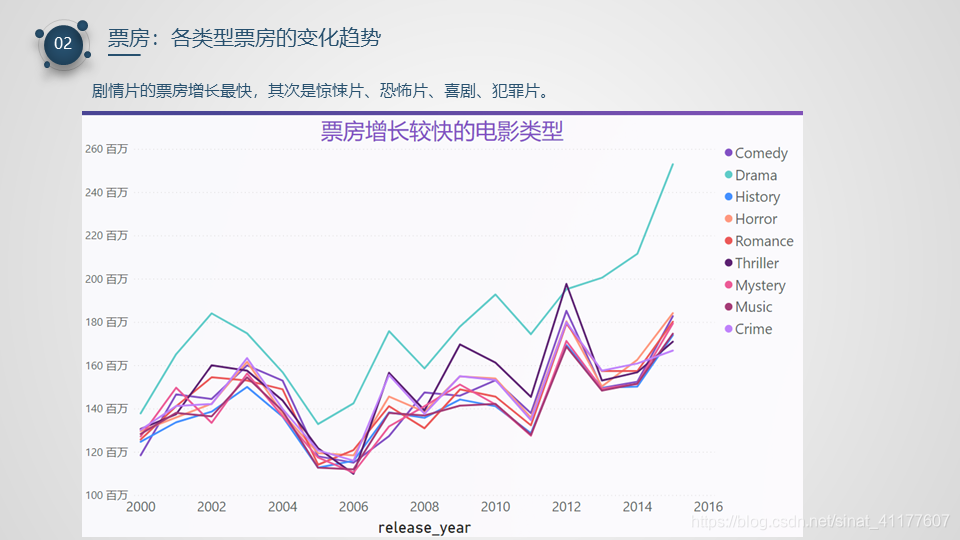
- 剧情片的票房增长最快,其次是惊悚片、恐怖片、喜剧、犯罪片。
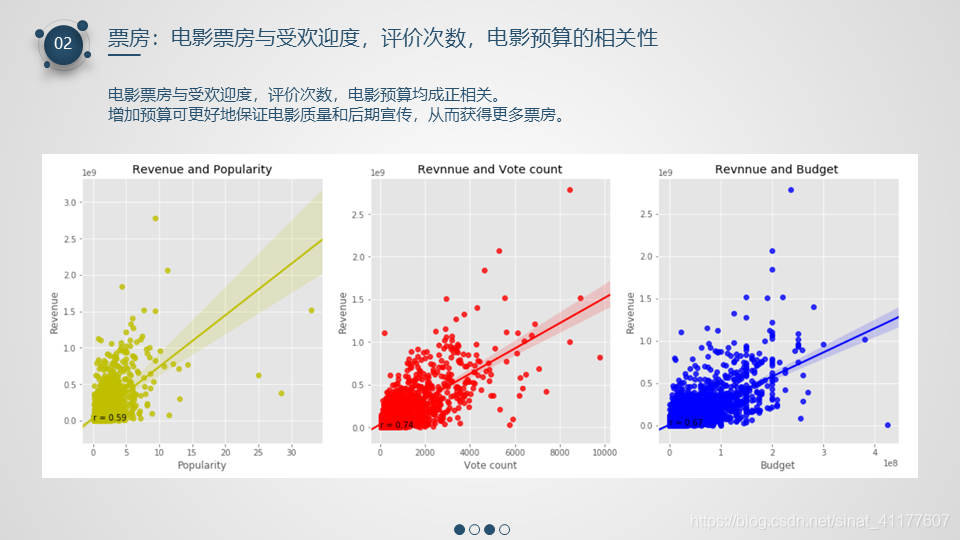
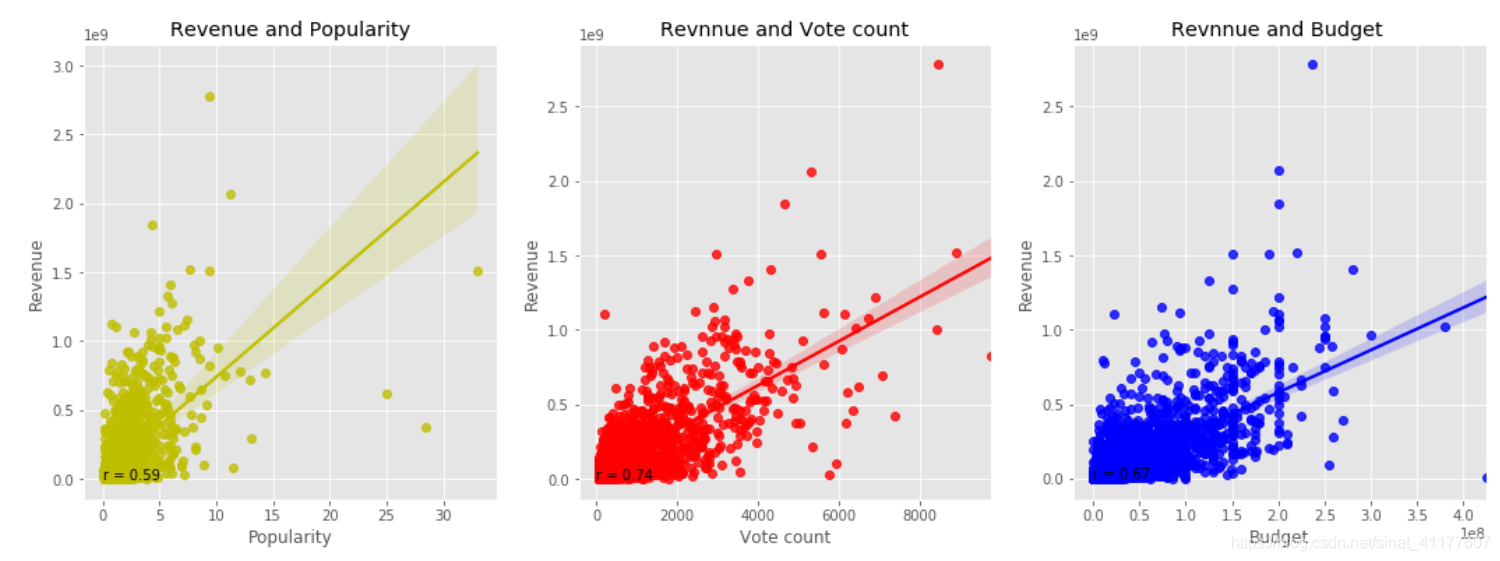
- 电影票房与受欢迎度,评价次数,电影预算均成正相关。增加预算可更好地保证电影质量和后期宣传,有助于获得更多票房。
3、档期:
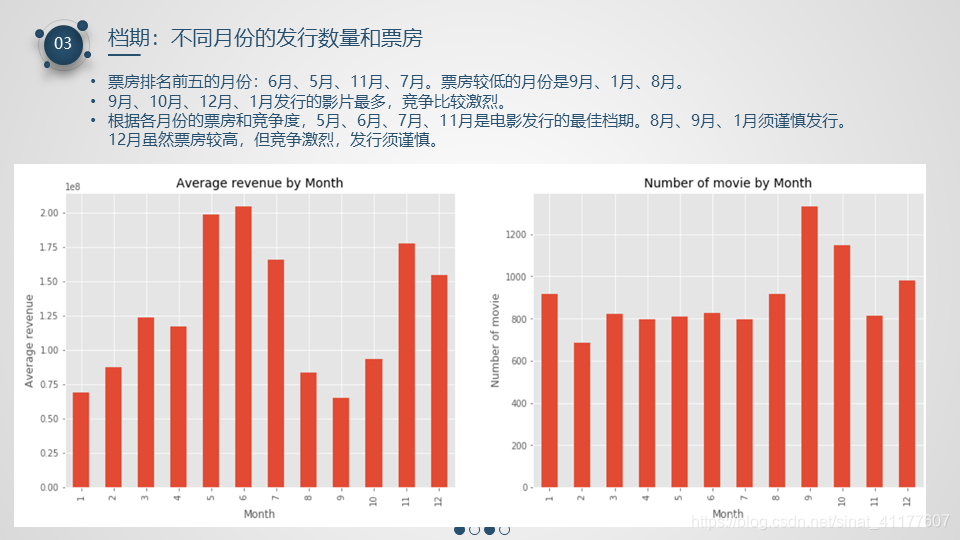
- 票房排名前五的月份:6月、5月、11月、7月。票房较低的月份是9月、1月、8月。
9月、10月、12月、1月发行的影片最多,竞争比较激烈。- 根据各月份的票房和竞争度,5月、6月、7月、11月是电影发行的最佳档期。8月、9月、1月须谨慎发行。12月虽然票房较高,但竞争激烈,挑战与机遇并存。
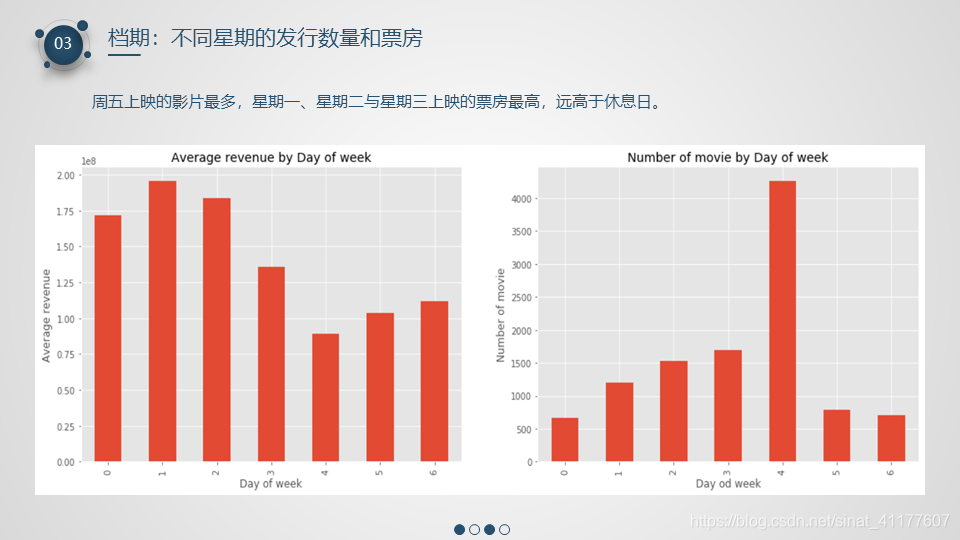
- 周五上映的影片最多,星期一、星期二与星期三上映的票房最高,远高于休息日。
4、评分:
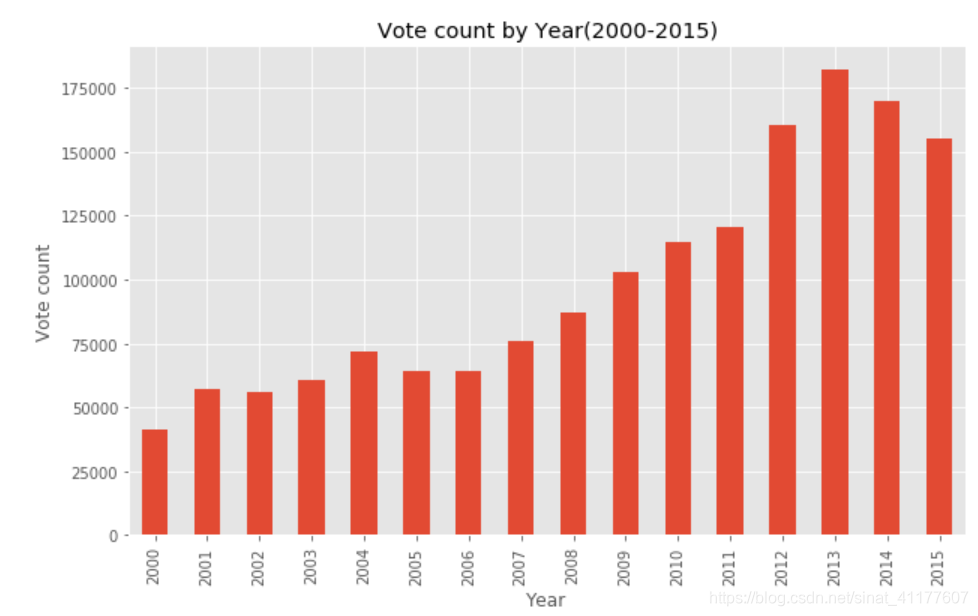
- 评分人数整体呈上升趋势,从2007年开始增加,2013年后略有下降。
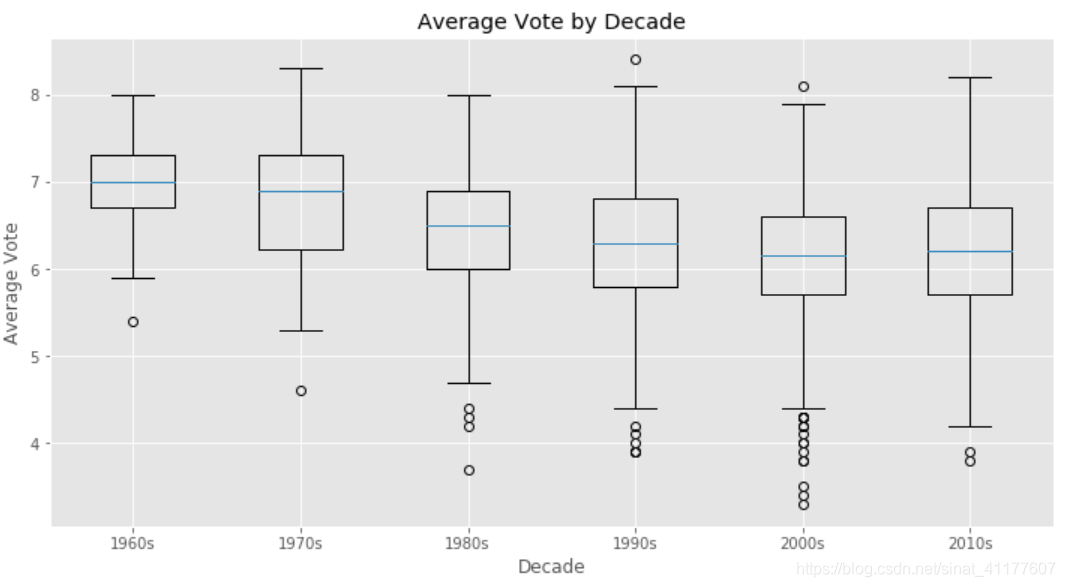
- 70年代开始,随着电影产出量的增加,影片层次不齐,低分影片开始出现,平均分也有略微下降,人们对影片的要求越来越高。
- 各类型电影的平均评分在5-7分,差距不大。可以看出,电影类型对评分影响不是很大。同时,类型、评价数量、票房、热度等对电影评分的影响都不大,电影评分的高低主要还是取决于观众的主观评价、电影的质量等。
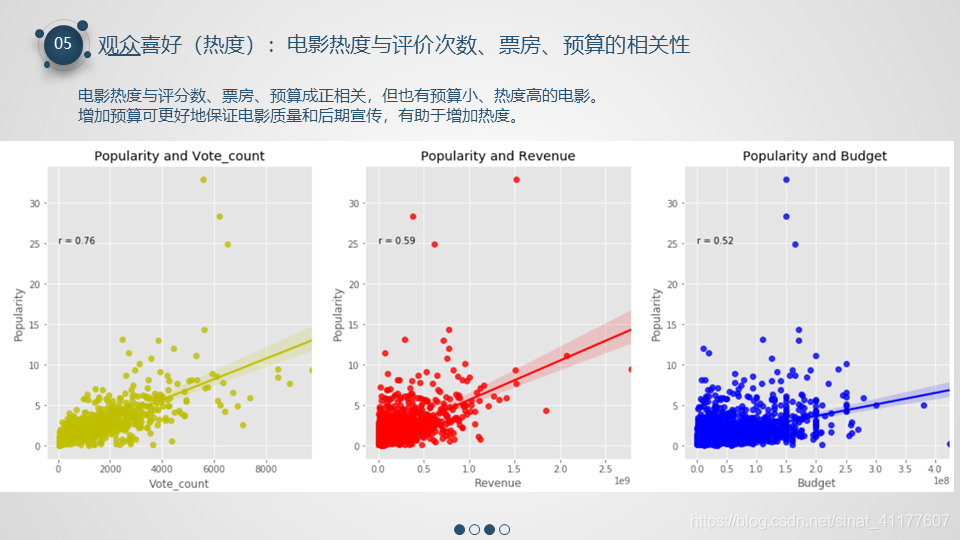
5、观众喜好(热度)
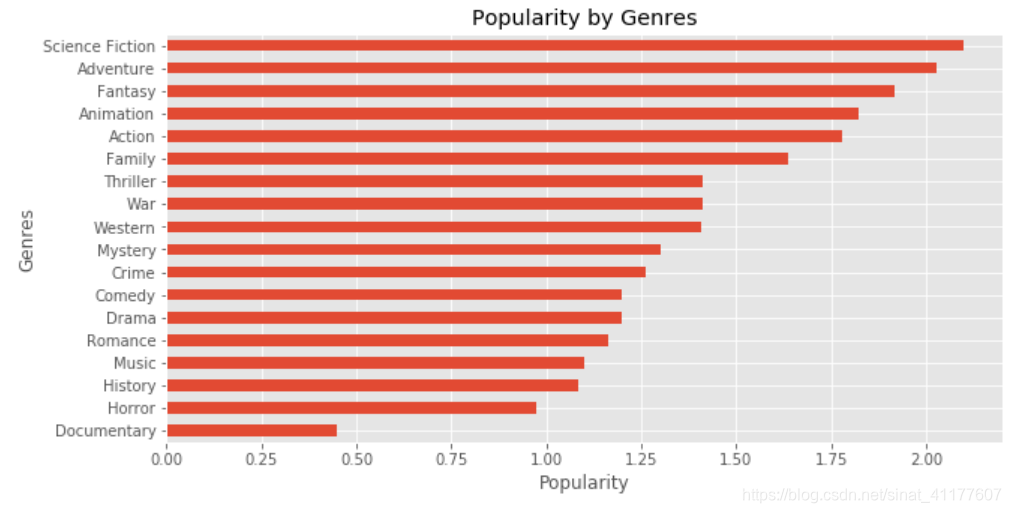
- 热度排名前六的类型分别为:科幻、冒险、奇幻、动画、动作、家庭。想象题材或非现实题材的电影(科幻、冒险、奇幻、动画)的受欢迎度要明显高于其他类别的电影。
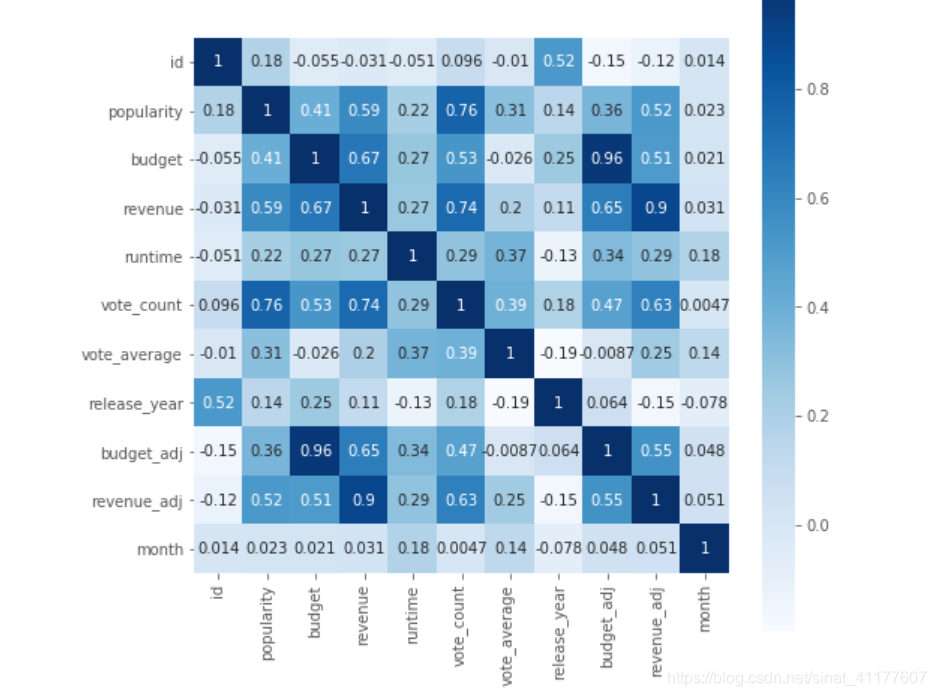
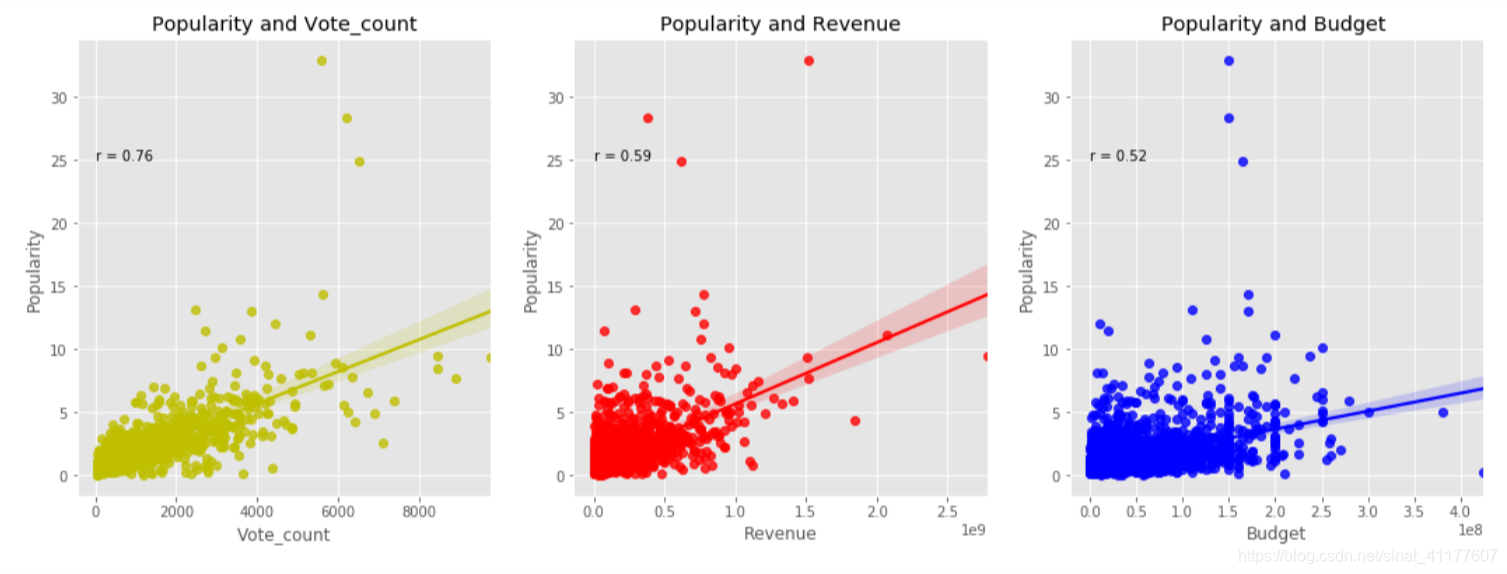
- 电影热度与评分数、票房、预算成正相关,但也有预算小、热度高的电影。增加预算可更好地保证电影质量和后期宣传,有助于增加热度。
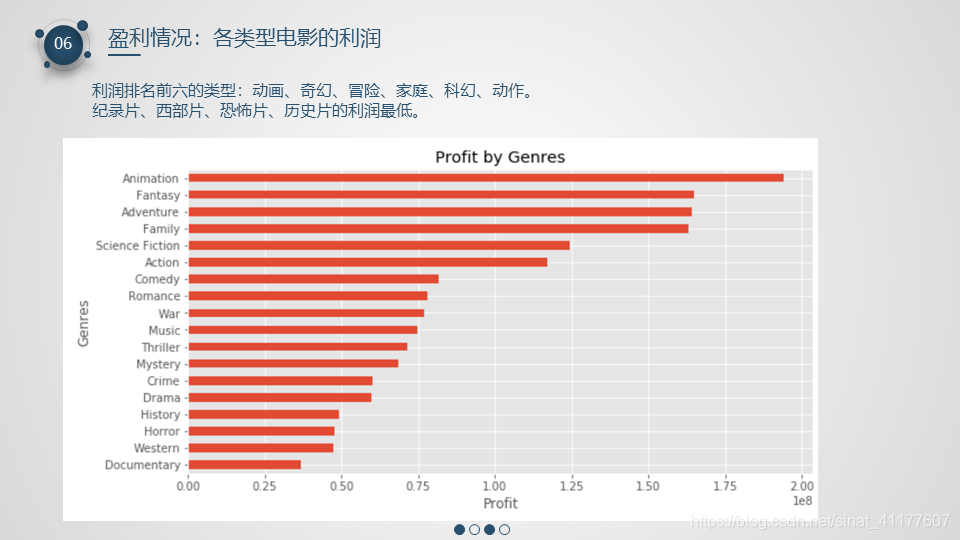
6、电影盈利情况:
- 利润:排名前六的类型:动画、奇幻、冒险、家庭、科幻、动作。纪录片、西部片、恐怖片、历史片的利润最低。
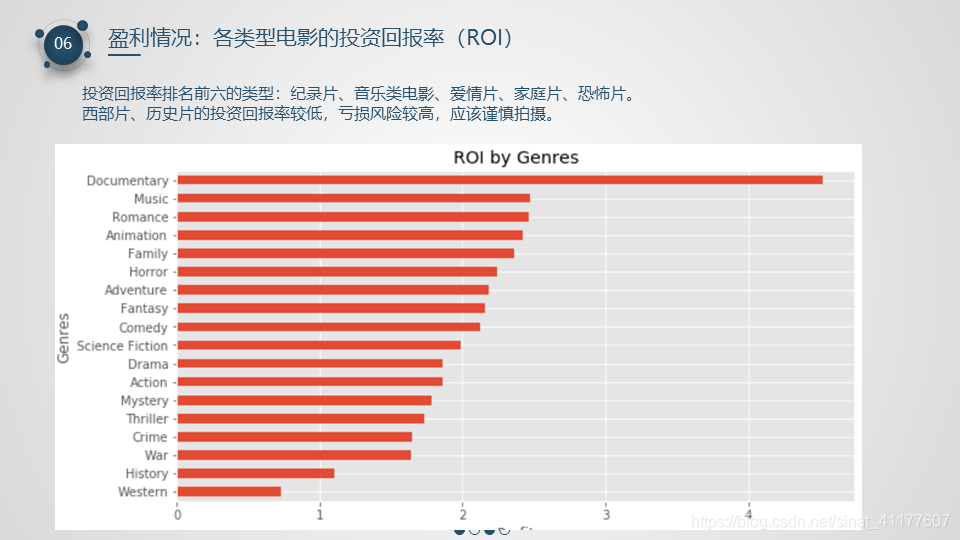
- 投资回报率:排名前六的类型:纪录片、音乐类电影、爱情片、家庭片、恐怖片。西部片、历史片的投资回报率较低,亏损风险较高,应该谨慎拍摄。
7、分析局限性:
- 60%的数据存在票房、预算缺失,去除异常值后数据集仅有3000多条,分析准确度可能有所下降。
4.数据处理过程(python)
# 导入模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
3.1 数据清洗
常规属性
# 加载数据并打印几行。进行这几项操作,来检查数据
df = pd.read_csv('tmdb_movies.csv')
df.head()
| id | imdb_id | popularity | budget | revenue | original_title | cast | homepage | director | tagline | ... | overview | runtime | genres | production_companies | release_date | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 135397 | tt0369610 | 32.985763 | 150000000 | 1513528810 | Jurassic World | Chris Pratt|Bryce Dallas Howard|Irrfan Khan|Vi... | http://www.jurassicworld.com/ | Colin Trevorrow | The park is open. | ... | Twenty-two years after the events of Jurassic ... | 124 | Action|Adventure|Science Fiction|Thriller | Universal Studios|Amblin Entertainment|Legenda... | 6/9/15 | 5562 | 6.5 | 2015 | 1.379999e+08 | 1.392446e+09 |
| 1 | 76341 | tt1392190 | 28.419936 | 150000000 | 378436354 | Mad Max: Fury Road | Tom Hardy|Charlize Theron|Hugh Keays-Byrne|Nic... | http://www.madmaxmovie.com/ | George Miller | What a Lovely Day. | ... | An apocalyptic story set in the furthest reach... | 120 | Action|Adventure|Science Fiction|Thriller | Village Roadshow Pictures|Kennedy Miller Produ... | 5/13/15 | 6185 | 7.1 | 2015 | 1.379999e+08 | 3.481613e+08 |
| 2 | 262500 | tt2908446 | 13.112507 | 110000000 | 295238201 | Insurgent | Shailene Woodley|Theo James|Kate Winslet|Ansel... | http://www.thedivergentseries.movie/#insurgent | Robert Schwentke | One Choice Can Destroy You | ... | Beatrice Prior must confront her inner demons ... | 119 | Adventure|Science Fiction|Thriller | Summit Entertainment|Mandeville Films|Red Wago... | 3/18/15 | 2480 | 6.3 | 2015 | 1.012000e+08 | 2.716190e+08 |
| 3 | 140607 | tt2488496 | 11.173104 | 200000000 | 2068178225 | Star Wars: The Force Awakens | Harrison Ford|Mark Hamill|Carrie Fisher|Adam D... | http://www.starwars.com/films/star-wars-episod... | J.J. Abrams | Every generation has a story. | ... | Thirty years after defeating the Galactic Empi... | 136 | Action|Adventure|Science Fiction|Fantasy | Lucasfilm|Truenorth Productions|Bad Robot | 12/15/15 | 5292 | 7.5 | 2015 | 1.839999e+08 | 1.902723e+09 |
| 4 | 168259 | tt2820852 | 9.335014 | 190000000 | 1506249360 | Furious 7 | Vin Diesel|Paul Walker|Jason Statham|Michelle ... | http://www.furious7.com/ | James Wan | Vengeance Hits Home | ... | Deckard Shaw seeks revenge against Dominic Tor... | 137 | Action|Crime|Thriller | Universal Pictures|Original Film|Media Rights ... | 4/1/15 | 2947 | 7.3 | 2015 | 1.747999e+08 | 1.385749e+09 |
5 rows × 21 columns
#类型,以及是否有缺失数据或错误数据的情况
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10866 entries, 0 to 10865
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 10866 non-null int64
1 imdb_id 10856 non-null object
2 popularity 10866 non-null float64
3 budget 10866 non-null int64
4 revenue 10866 non-null int64
5 original_title 10866 non-null object
6 cast 10790 non-null object
7 homepage 2936 non-null object
8 director 10822 non-null object
9 tagline 8042 non-null object
10 keywords 9373 non-null object
11 overview 10862 non-null object
12 runtime 10866 non-null int64
13 genres 10843 non-null object
14 production_companies 9836 non-null object
15 release_date 10866 non-null object
16 vote_count 10866 non-null int64
17 vote_average 10866 non-null float64
18 release_year 10866 non-null int64
19 budget_adj 10866 non-null float64
20 revenue_adj 10866 non-null float64
dtypes: float64(4), int64(6), object(11)
memory usage: 1.7+ MB
数据清理(清除多余列、丢空、去重。)
#清除多余列
df.drop(['imdb_id','cast','homepage', 'director', 'tagline', 'keywords', 'overview','production_companies'], axis = 1, inplace = True)
df.head(2)
| id | popularity | budget | revenue | original_title | runtime | genres | release_date | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 135397 | 32.985763 | 150000000 | 1513528810 | Jurassic World | 124 | Action|Adventure|Science Fiction|Thriller | 6/9/15 | 5562 | 6.5 | 2015 | 1.379999e+08 | 1.392446e+09 |
| 1 | 76341 | 28.419936 | 150000000 | 378436354 | Mad Max: Fury Road | 120 | Action|Adventure|Science Fiction|Thriller | 5/13/15 | 6185 | 7.1 | 2015 | 1.379999e+08 | 3.481613e+08 |
#查看缺失值数量
df.isnull().sum()
id 0
popularity 0
budget 0
revenue 0
original_title 0
runtime 0
genres 23
release_date 0
vote_count 0
vote_average 0
release_year 0
budget_adj 0
revenue_adj 0
dtype: int64
#去除含有任何空值的行
df.dropna(inplace = True)
#检查任何列是否还有空值
df.isnull().sum().any()
False
#查看数据重复数量
sum(df.duplicated())
1
#去除重复行
df.drop_duplicates(inplace = True)
#确认重复数据是否删除
sum(df.duplicated())
0
df.describe()
| id | popularity | budget | revenue | runtime | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 10842.000000 | 10842.000000 | 1.084200e+04 | 1.084200e+04 | 10842.000000 | 10842.000000 | 10842.000000 | 10842.000000 | 1.084200e+04 | 1.084200e+04 |
| mean | 65870.675521 | 0.647461 | 1.465531e+07 | 3.991138e+07 | 102.138443 | 217.823649 | 5.974064 | 2001.314794 | 1.758712e+07 | 5.147797e+07 |
| std | 91981.355752 | 1.001032 | 3.093971e+07 | 1.171179e+08 | 31.294612 | 576.180993 | 0.934257 | 12.813617 | 3.433437e+07 | 1.447723e+08 |
| min | 5.000000 | 0.000065 | 0.000000e+00 | 0.000000e+00 | 0.000000 | 10.000000 | 1.500000 | 1960.000000 | 0.000000e+00 | 0.000000e+00 |
| 25% | 10589.250000 | 0.208210 | 0.000000e+00 | 0.000000e+00 | 90.000000 | 17.000000 | 5.400000 | 1995.000000 | 0.000000e+00 | 0.000000e+00 |
| 50% | 20557.000000 | 0.384532 | 0.000000e+00 | 0.000000e+00 | 99.000000 | 38.000000 | 6.000000 | 2006.000000 | 0.000000e+00 | 0.000000e+00 |
| 75% | 75186.000000 | 0.715393 | 1.500000e+07 | 2.414118e+07 | 111.000000 | 146.000000 | 6.600000 | 2011.000000 | 2.092507e+07 | 3.387838e+07 |
| max | 417859.000000 | 32.985763 | 4.250000e+08 | 2.781506e+09 | 900.000000 | 9767.000000 | 9.200000 | 2015.000000 | 4.250000e+08 | 2.827124e+09 |
3.2 探索性数据分析
电影类型分析:各类型电影数量分布及随时间变化趋势如何?
(1)获取电影类型
# 创建一个集合,有去重功能
genres_set = set()
#切割genres列,创建一个循环
for i in df['genres']:
genres_set.update(i.split('|'))
genres_set.discard(' ')
genres_set
{'Action',
'Adventure',
'Animation',
'Comedy',
'Crime',
'Documentary',
'Drama',
'Family',
'Fantasy',
'Foreign',
'History',
'Horror',
'Music',
'Mystery',
'Romance',
'Science Fiction',
'TV Movie',
'Thriller',
'War',
'Western'}
#新建一个数据框
genres_df = pd.DataFrame()
#判断每部电影的类型,电影包含某个类型就返回1,否则返回0
for gen in genres_set:
genres_df[gen] = df['genres'].str.contains(gen).map(lambda x: 1 if x else 0)
genres_df.head(10)
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
#查看各类型电影数量
g1 = pd.DataFrame(index = [0,1])
for gen in genres_set:
g1[gen] =genres_df[gen].value_counts()
g1
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10434 | 8458 | 7935 | 9205 | 10572 | 9926 | 10675 | 9611 | 9613 | 7049 | 10032 | 9488 | 10143 | 6082 | 10654 | 9371 | 10677 | 10508 | 10322 | 9130 |
| 1 | 408 | 2384 | 2907 | 1637 | 270 | 916 | 167 | 1231 | 1229 | 3793 | 810 | 1354 | 699 | 4760 | 188 | 1471 | 165 | 334 | 520 | 1712 |
#在数据框中加入年份
genres_df['release_year'] = df['release_year']
genres_df['release_year'] = df['release_year']
#数据框按年份分组,求和
gen_year = genres_df.groupby('release_year').sum()
gen_year.head()
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| release_year | ||||||||||||||||||||
| 1960 | 1 | 8 | 6 | 7 | 2 | 2 | 0 | 3 | 3 | 8 | 0 | 2 | 0 | 13 | 1 | 5 | 6 | 5 | 0 | 6 |
| 1961 | 2 | 7 | 0 | 3 | 2 | 2 | 0 | 5 | 4 | 10 | 1 | 2 | 1 | 16 | 1 | 6 | 3 | 3 | 0 | 7 |
| 1962 | 1 | 8 | 7 | 5 | 3 | 1 | 0 | 2 | 2 | 5 | 4 | 3 | 0 | 21 | 1 | 7 | 3 | 4 | 0 | 5 |
| 1963 | 0 | 4 | 10 | 9 | 1 | 2 | 0 | 3 | 2 | 13 | 6 | 4 | 1 | 13 | 2 | 7 | 2 | 4 | 0 | 8 |
| 1964 | 5 | 5 | 9 | 6 | 3 | 4 | 0 | 4 | 4 | 16 | 4 | 10 | 2 | 20 | 1 | 5 | 1 | 3 | 0 | 9 |
(2)1960-2015年各类型电影数量变化
plt.figure(figsize = (12, 6))
plt.plot(gen_year, label = gen_year.columns)
plt.title('Number of movies by genres and year')
plt.xticks(range(1950, 2020, 5))
plt.xlabel('Year')
plt.ylabel('Moies Number')
plt.legend(gen_year)#图例

#每年各类型电影总数
genres_sum_year = gen_year.sum( axis=1)
#每年各类型电影占比
gen_proportion_year = pd.DataFrame()
for i in gen_year.columns:
gen_proportion_year[i] = gen_year[i]/genres_sum_year
gen_proportion_year.head()
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| release_year | ||||||||||||||||||||
| 1960 | 0.012821 | 0.102564 | 0.076923 | 0.089744 | 0.025641 | 0.025641 | 0.0 | 0.038462 | 0.038462 | 0.102564 | 0.000000 | 0.025641 | 0.000000 | 0.166667 | 0.012821 | 0.064103 | 0.076923 | 0.064103 | 0.0 | 0.076923 |
| 1961 | 0.026667 | 0.093333 | 0.000000 | 0.040000 | 0.026667 | 0.026667 | 0.0 | 0.066667 | 0.053333 | 0.133333 | 0.013333 | 0.026667 | 0.013333 | 0.213333 | 0.013333 | 0.080000 | 0.040000 | 0.040000 | 0.0 | 0.093333 |
| 1962 | 0.012195 | 0.097561 | 0.085366 | 0.060976 | 0.036585 | 0.012195 | 0.0 | 0.024390 | 0.024390 | 0.060976 | 0.048780 | 0.036585 | 0.000000 | 0.256098 | 0.012195 | 0.085366 | 0.036585 | 0.048780 | 0.0 | 0.060976 |
| 1963 | 0.000000 | 0.043956 | 0.109890 | 0.098901 | 0.010989 | 0.021978 | 0.0 | 0.032967 | 0.021978 | 0.142857 | 0.065934 | 0.043956 | 0.010989 | 0.142857 | 0.021978 | 0.076923 | 0.021978 | 0.043956 | 0.0 | 0.087912 |
| 1964 | 0.045045 | 0.045045 | 0.081081 | 0.054054 | 0.027027 | 0.036036 | 0.0 | 0.036036 | 0.036036 | 0.144144 | 0.036036 | 0.090090 | 0.018018 | 0.180180 | 0.009009 | 0.045045 | 0.009009 | 0.027027 | 0.0 | 0.081081 |
#2005-2015年各类型电影占比
gen_proportion_year1 = gen_proportion_year.loc[2005:,:]
gen_proportion_year1
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| release_year | ||||||||||||||||||||
| 2005 | 0.013904 | 0.074866 | 0.098396 | 0.059893 | 0.005348 | 0.037433 | 0.003209 | 0.060963 | 0.026738 | 0.152941 | 0.031016 | 0.048128 | 0.027807 | 0.194652 | 0.010695 | 0.056684 | 0.002139 | 0.010695 | 0.018182 | 0.066310 |
| 2006 | 0.011494 | 0.076628 | 0.109195 | 0.053640 | 0.006705 | 0.032567 | 0.007663 | 0.062261 | 0.028736 | 0.148467 | 0.028736 | 0.050766 | 0.037356 | 0.188697 | 0.009579 | 0.052682 | 0.000958 | 0.011494 | 0.015326 | 0.067050 |
| 2007 | 0.013321 | 0.084369 | 0.111012 | 0.070160 | 0.005329 | 0.041741 | 0.005329 | 0.039964 | 0.036412 | 0.134103 | 0.030195 | 0.057726 | 0.028419 | 0.174956 | 0.015098 | 0.053286 | 0.004440 | 0.011545 | 0.016874 | 0.065719 |
| 2008 | 0.016142 | 0.079903 | 0.102502 | 0.061340 | 0.014528 | 0.034705 | 0.004036 | 0.045198 | 0.041969 | 0.136400 | 0.023406 | 0.050040 | 0.026634 | 0.188055 | 0.014528 | 0.050847 | 0.001614 | 0.019370 | 0.020985 | 0.067797 |
| 2009 | 0.012518 | 0.079529 | 0.115611 | 0.066274 | 0.008837 | 0.036082 | 0.005891 | 0.044183 | 0.052283 | 0.145803 | 0.037555 | 0.038292 | 0.035346 | 0.164948 | 0.012518 | 0.053019 | 0.000000 | 0.011782 | 0.018409 | 0.061119 |
| 2010 | 0.008258 | 0.088357 | 0.110652 | 0.064410 | 0.005780 | 0.036334 | 0.006606 | 0.045417 | 0.037159 | 0.139554 | 0.026424 | 0.041288 | 0.041288 | 0.173410 | 0.010735 | 0.048720 | 0.004955 | 0.011561 | 0.028902 | 0.070190 |
| 2011 | 0.013302 | 0.089984 | 0.114241 | 0.061033 | 0.007042 | 0.035994 | 0.007825 | 0.056338 | 0.043818 | 0.134585 | 0.029734 | 0.037559 | 0.035994 | 0.167449 | 0.010955 | 0.048513 | 0.002347 | 0.006260 | 0.038341 | 0.058685 |
| 2012 | 0.017255 | 0.077647 | 0.125490 | 0.081569 | 0.007843 | 0.026667 | 0.010980 | 0.032941 | 0.042353 | 0.138039 | 0.025882 | 0.042353 | 0.031373 | 0.181961 | 0.004706 | 0.039216 | 0.003137 | 0.010196 | 0.038431 | 0.061961 |
| 2013 | 0.021692 | 0.087491 | 0.126537 | 0.073753 | 0.005061 | 0.028200 | 0.007231 | 0.034707 | 0.044107 | 0.126537 | 0.027477 | 0.051338 | 0.030369 | 0.182936 | 0.000000 | 0.048445 | 0.002169 | 0.010123 | 0.044830 | 0.046999 |
| 2014 | 0.019048 | 0.087755 | 0.121769 | 0.071429 | 0.015646 | 0.024490 | 0.009524 | 0.029252 | 0.042177 | 0.125850 | 0.024490 | 0.044218 | 0.024490 | 0.193197 | 0.000000 | 0.045578 | 0.004082 | 0.010204 | 0.049660 | 0.057143 |
| 2015 | 0.023810 | 0.077201 | 0.123377 | 0.090188 | 0.006494 | 0.023810 | 0.014430 | 0.031746 | 0.062049 | 0.116883 | 0.030303 | 0.036797 | 0.028139 | 0.187590 | 0.000000 | 0.049784 | 0.004329 | 0.010823 | 0.041126 | 0.041126 |
(3)2005-2015年各类型电影占比变化
#2005-2015年各类型电影占比变化
plt.figure(figsize = (12, 6))
plt.plot(gen_proportion_year.loc[2005:, :], label = gen_year.columns)
plt.title('Proportion of movies by genres and year(2005-2015)')
plt.xticks(range(2003, 2016, 1))
plt.xlabel('Year')
plt.ylabel('Moies Number')
plt.legend(gen_proportion_year)#图例
(4)各类型电影比例分布
#各电影类型数量
genres_sum = genres_df.sum().sort_values(ascending = False).drop('release_year')
genres_sum
Drama 4760
Comedy 3793
Thriller 2907
Action 2384
Romance 1712
Horror 1637
Adventure 1471
Crime 1354
Family 1231
Science Fiction 1229
Fantasy 916
Mystery 810
Animation 699
Documentary 520
Music 408
History 334
War 270
Foreign 188
TV Movie 167
Western 165
dtype: int64
genres_total = genres_sum.sum()
#各电影类型比例
genres_proportion = genres_sum/ genres_total
genres_proportion
Drama 0.176591
Comedy 0.140716
Thriller 0.107846
Action 0.088444
Romance 0.063513
Horror 0.060731
Adventure 0.054572
Crime 0.050232
Family 0.045669
Science Fiction 0.045595
Fantasy 0.033983
Mystery 0.030050
Animation 0.025932
Documentary 0.019291
Music 0.015136
History 0.012391
War 0.010017
Foreign 0.006975
TV Movie 0.006196
Western 0.006121
dtype: float64
#绘制柱形图
genres_proportion.plot.barh(label = 'genre', figsize = (12, 6))
plt.title('Proportion of Gennres')
plt.xlabel('Proportion')
plt.ylabel('Genre')
进一步做数据清洗,将清洗后的数据放在df2数据集中:
筛选评分人数大于50的数据。评分人数(vote_count)过低的电影,其评分(vote_average)不具有统计意义。
筛去票房、预算等为0的数据。
#筛选评分人数大于50的数据
df2 = df.query('vote_count > 50')
#筛去票房、预算等为0的数据
df2=df2[~df2['budget'].isin([0.000000e+00])]
df2=df2[~df2['revenue'].isin([0.000000e+00])]
df2.head()
| id | popularity | budget | revenue | original_title | runtime | genres | release_date | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 135397 | 32.985763 | 150000000 | 1513528810 | Jurassic World | 124 | Action|Adventure|Science Fiction|Thriller | 6/9/15 | 5562 | 6.5 | 2015 | 1.379999e+08 | 1.392446e+09 |
| 1 | 76341 | 28.419936 | 150000000 | 378436354 | Mad Max: Fury Road | 120 | Action|Adventure|Science Fiction|Thriller | 5/13/15 | 6185 | 7.1 | 2015 | 1.379999e+08 | 3.481613e+08 |
| 2 | 262500 | 13.112507 | 110000000 | 295238201 | Insurgent | 119 | Adventure|Science Fiction|Thriller | 3/18/15 | 2480 | 6.3 | 2015 | 1.012000e+08 | 2.716190e+08 |
| 3 | 140607 | 11.173104 | 200000000 | 2068178225 | Star Wars: The Force Awakens | 136 | Action|Adventure|Science Fiction|Fantasy | 12/15/15 | 5292 | 7.5 | 2015 | 1.839999e+08 | 1.902723e+09 |
| 4 | 168259 | 9.335014 | 190000000 | 1506249360 | Furious 7 | 137 | Action|Crime|Thriller | 4/1/15 | 2947 | 7.3 | 2015 | 1.747999e+08 | 1.385749e+09 |
df2.describe()
| id | popularity | budget | revenue | runtime | vote_count | vote_average | release_year | budget_adj | revenue_adj | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 3123.000000 | 3123.000000 | 3.123000e+03 | 3.123000e+03 | 3123.000000 | 3123.000000 | 3123.000000 | 3123.000000 | 3.123000e+03 | 3.123000e+03 |
| mean | 42688.892731 | 1.392294 | 4.261919e+07 | 1.296105e+08 | 110.037464 | 644.723343 | 6.254371 | 2002.292027 | 4.968112e+07 | 1.629720e+08 |
| std | 71354.906196 | 1.569972 | 4.461333e+07 | 1.891287e+08 | 19.588370 | 939.891310 | 0.760518 | 10.935365 | 4.697721e+07 | 2.311534e+08 |
| min | 5.000000 | 0.010335 | 1.000000e+00 | 2.000000e+00 | 26.000000 | 51.000000 | 3.300000 | 1960.000000 | 9.693980e-01 | 2.861934e+00 |
| 25% | 4000.000000 | 0.617888 | 1.300000e+07 | 2.496112e+07 | 96.000000 | 135.000000 | 5.700000 | 1997.000000 | 1.657964e+07 | 3.145014e+07 |
| 50% | 10585.000000 | 0.976612 | 2.800000e+07 | 6.556987e+07 | 106.000000 | 299.000000 | 6.300000 | 2005.000000 | 3.463336e+07 | 8.285793e+07 |
| 75% | 44927.500000 | 1.593279 | 5.950000e+07 | 1.556332e+08 | 120.000000 | 717.500000 | 6.800000 | 2011.000000 | 6.911341e+07 | 1.967146e+08 |
| max | 336004.000000 | 32.985763 | 4.250000e+08 | 2.781506e+09 | 248.000000 | 9767.000000 | 8.400000 | 2015.000000 | 4.250000e+08 | 2.827124e+09 |
df2.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3123 entries, 0 to 10822
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 3123 non-null int64
1 popularity 3123 non-null float64
2 budget 3123 non-null int64
3 revenue 3123 non-null int64
4 original_title 3123 non-null object
5 runtime 3123 non-null int64
6 genres 3123 non-null object
7 release_date 3123 non-null object
8 vote_count 3123 non-null int64
9 vote_average 3123 non-null float64
10 release_year 3123 non-null int64
11 budget_adj 3123 non-null float64
12 revenue_adj 3123 non-null float64
dtypes: float64(4), int64(6), object(3)
memory usage: 341.6+ KB
2、票房分析:票房和哪些特征有关?
(1)电影票房的影响因素(数值型变量)
#绘制相关系数热力图
plt.subplots(figsize=(8,8))#调节图像大小
sns.heatmap(df2.corr(), annot = True, vmax = 1, square = True, cmap = 'Reds' )
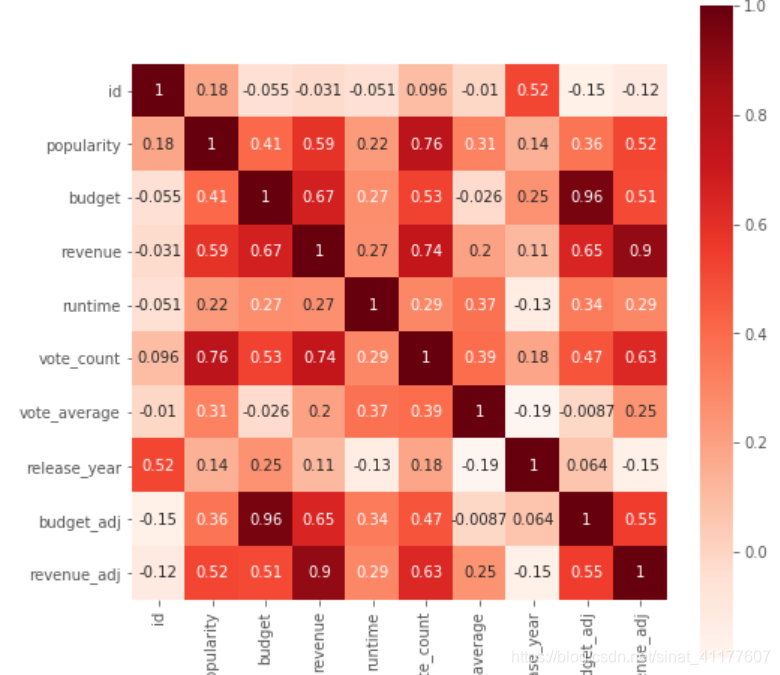
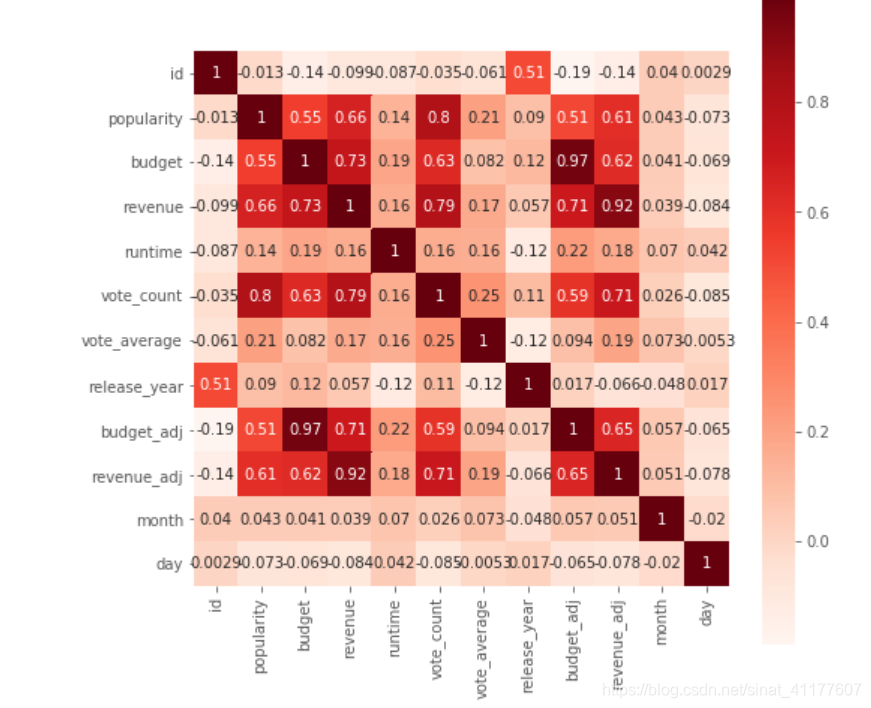
可以看出,电影票房和评价次数(0.74)、预算(0.67)、受欢迎度(0.59)相关性较强。
绘制电影票房与受欢迎度,评价次数,电影预算的相关性散点图及其线性回归线
#创建票房与受欢迎度,评价次数,电影预算的数据框
revenue = df2[['vote_count', 'budget', 'popularity', 'revenue']]
plt.figure(figsize = (18,6))
#电影票房与受欢迎度的相关性散点图及其线性回归线
ax1 = plt.subplot(1, 3, 1)
ax1 = sns.regplot(x = 'popularity', y = 'revenue', data = revenue, color = 'y')
ax1.text(0, 2.5, 'r = 0.59')
plt.title('Revenue and Popularity')
plt.xlabel('Popularity')
plt.ylabel('Revenue')
#电影票房与评价次数的相关性散点图及其线性回归线
ax2 = plt.subplot(1, 3, 2)
ax2 = sns.regplot(x ='vote_count' , y = 'revenue', data = revenue, color = 'r')
ax2.text(0, 2.5, 'r = 0.74')
plt.title('Revnnue and Vote count')
plt.xlabel('Vote count')
plt.ylabel('Revenue')
#电影票房与预算的相关性散点图及其线性回归线
ax3 = plt.subplot(1, 3, 3)
ax3 = sns.regplot(x = 'budget' , y ='revenue', data = revenue, color = 'B')
ax3.text(0, 2.5, 'r = 0.67')
plt.title('Revnnue and Budget ')
plt.xlabel('Budget')
plt.ylabel('Revenue')
(2)票房和电影类型
#新建一个数据框
genres_df2 = pd.DataFrame()
#判断每部电影的类型,电影包含某个类型就返回1,否则返回0
for gen in genres_set:
genres_df2[gen] = df2['genres'].str.contains(gen).map(lambda x: 1 if x else 0)
genres_df2.head()
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
#查看各类型电影数量
g0 = pd.DataFrame(index = [0,1])
for gen in genres_set:
g0[gen] =genres_df2[gen].value_counts()
g0
| Music | Action | Thriller | Horror | War | Fantasy | TV Movie | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Foreign | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3023 | 2198 | 2095 | 2747 | 3023 | 2769 | 3123.0 | 2758 | 2671 | 2058 | 2836 | 2570 | 2937 | 1768 | 3122 | 2446 | 3084 | 3014 | 3108 | 2625 |
| 1 | 100 | 925 | 1028 | 376 | 100 | 354 | NaN | 365 | 452 | 1065 | 287 | 553 | 186 | 1355 | 1 | 677 | 39 | 109 | 15 | 498 |
#删掉样本数量少的类型
genres_df2.drop(['TV Movie','Foreign'],axis = 1, inplace = True)
genres_df2.head()
| Music | Action | Thriller | Horror | War | Fantasy | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
#创建电影类型与票房、评分、预算、热度、评价数量数据框
genres_df3 = pd.DataFrame()
genres_df3 = pd.concat([genres_df2, df2.iloc[:, [1, 2, 3, 7, 8, 9, 10]]], axis = 1)
genres_df3.head()
| Music | Action | Thriller | Horror | War | Fantasy | Family | Science Fiction | Comedy | Mystery | ... | History | Documentary | Romance | popularity | budget | revenue | release_date | vote_count | vote_average | release_year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 32.985763 | 150000000 | 1513528810 | 6/9/15 | 5562 | 6.5 | 2015 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 28.419936 | 150000000 | 378436354 | 5/13/15 | 6185 | 7.1 | 2015 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 13.112507 | 110000000 | 295238201 | 3/18/15 | 2480 | 6.3 | 2015 |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 11.173104 | 200000000 | 2068178225 | 12/15/15 | 5292 | 7.5 | 2015 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 9.335014 | 190000000 | 1506249360 | 4/1/15 | 2947 | 7.3 | 2015 |
5 rows × 25 columns
genres_set.remove('TV Movie')
genres_set.remove('Foreign')
genres_set
{'Action',
'Adventure',
'Animation',
'Comedy',
'Crime',
'Documentary',
'Drama',
'Family',
'Fantasy',
'History',
'Horror',
'Music',
'Mystery',
'Romance',
'Science Fiction',
'Thriller',
'War',
'Western'}
分别计算不同电影的平均评分、平均受欢迎度、平均票房
#创建三个数组,
vote_by_genre = pd.Series(index = genres_set)
pop_by_genre = pd.Series(index = genres_set)
rev_by_genre = pd.Series(index = genres_set)
bud_by_genre = pd.Series(index = genres_set)
#分别计算不同电影的平均评分、平均受欢迎度、平均票房
for gen in genres_set:
vote_by_genre[gen] = genres_df3.groupby(gen, as_index = False).mean().loc[1, 'vote_average']
pop_by_genre[gen] = genres_df3.groupby(gen, as_index = False).mean().loc[1, 'popularity']
rev_by_genre[gen] = genres_df3.groupby(gen, as_index = False).mean().loc[1, 'revenue']
bud_by_genre[gen] = genres_df3.groupby(gen, as_index = False).mean().loc[1, 'budget']
#合并三个数组
movie_by_genre = pd.DataFrame({ 'vote_average': vote_by_genre, 'popularity': pop_by_genre, 'revenue': rev_by_genre, 'budget': bud_by_genre})
movie_by_genre
| vote_average | popularity | revenue | budget | |
|---|---|---|---|---|
| Music | 6.385000 | 1.101270 | 1.047237e+08 | 3.013560e+07 |
| Action | 6.099568 | 1.777369 | 1.802467e+08 | 6.309883e+07 |
| Thriller | 6.143093 | 1.413200 | 1.123881e+08 | 4.111380e+07 |
| Horror | 5.834840 | 0.974864 | 6.870872e+07 | 2.116128e+07 |
| War | 6.691000 | 1.412921 | 1.238682e+08 | 4.698285e+07 |
| Fantasy | 6.135876 | 1.916209 | 2.413179e+08 | 7.649616e+07 |
| Family | 6.210137 | 1.638098 | 2.320525e+08 | 6.898803e+07 |
| Science Fiction | 6.107522 | 2.097370 | 1.865328e+08 | 6.238452e+07 |
| Comedy | 6.115305 | 1.200185 | 1.200283e+08 | 3.844007e+07 |
| Mystery | 6.283275 | 1.300413 | 1.071573e+08 | 3.850171e+07 |
| Crime | 6.366004 | 1.261440 | 9.649637e+07 | 3.647491e+07 |
| Animation | 6.454839 | 1.821527 | 2.740895e+08 | 8.015984e+07 |
| Drama | 6.519188 | 1.197703 | 9.213394e+07 | 3.224194e+07 |
| Adventure | 6.177400 | 2.027486 | 2.392040e+08 | 7.520216e+07 |
| Western | 6.541026 | 1.407328 | 1.119227e+08 | 6.475754e+07 |
| History | 6.659633 | 1.085134 | 9.390964e+07 | 4.473635e+07 |
| Documentary | 6.726667 | 0.449032 | 4.494842e+07 | 8.142680e+06 |
| Romance | 6.317470 | 1.163230 | 1.097685e+08 | 3.171751e+07 |
不同类型电影的平均票房图
movie_by_genre.sort_values(by = ['revenue'])['revenue'].plot.barh(figsize = (10, 5))
plt.title('Average revenue by Genres')
plt.xlabel('Revenue')
plt.ylabel('Genres')
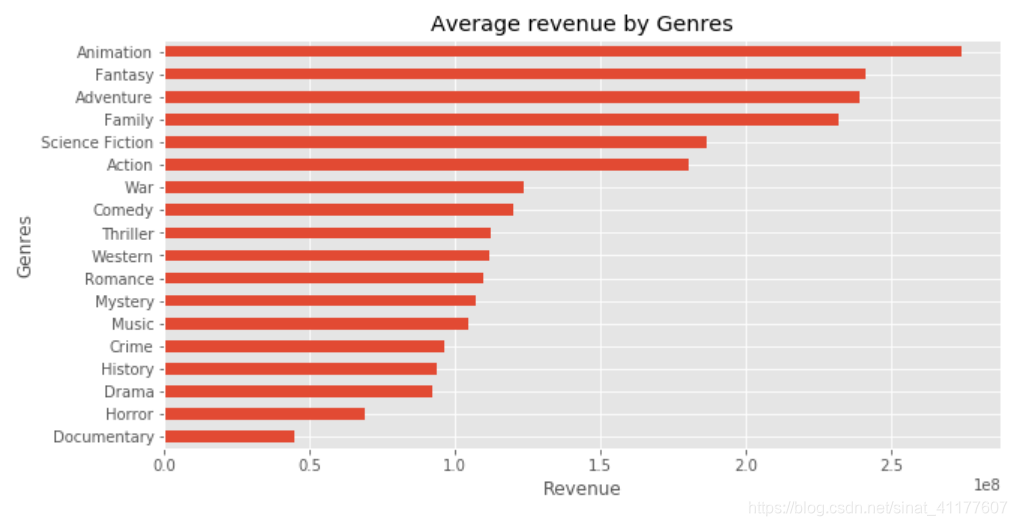
(3)电影票房随时间变化趋势
plt.figure(figsize = (10, 5))
revenue_by_year = df2.groupby('release_year').mean().sort_values(by = 'release_year')['revenue']
plt.plot(revenue_by_year)
plt.title('Average revenue by Release year')
plt.xlabel('Release year')
plt.ylabel('Average revenue')
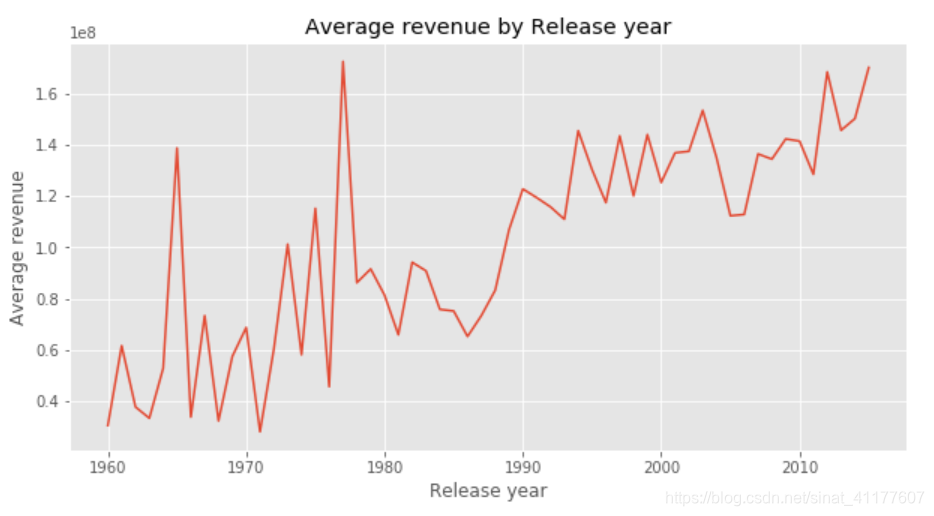
(4)各类型票房的变化趋势
#每年各类型电影的票房
revnue_genre_year = pd.DataFrame(index = gen_proportion_year.index)
for gen in genres_set:
revnue_genre_year[gen] = genres_df3.groupby(['release_year', gen]).revenue.mean().xs(0, level = 1)
revnue_genre_year.head()
| Music | Action | Thriller | Horror | War | Fantasy | Family | Science Fiction | Comedy | Mystery | Crime | Animation | Drama | Adventure | Western | History | Documentary | Romance | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| release_year | ||||||||||||||||||
| 1960 | 30476250.0 | 2.850000e+07 | 2.996833e+07 | 2.996833e+07 | 3.047625e+07 | 30476250.0 | 30476250.00 | 3.047625e+07 | 3.230167e+07 | 30476250.0 | 3.047625e+07 | 3.047625e+07 | 4.905000e+06 | 3.900000e+07 | 3.900000e+07 | 2.063500e+07 | 3.047625e+07 | 3.230167e+07 |
| 1961 | 66070003.5 | 6.975921e+07 | 6.158737e+07 | 6.158737e+07 | 6.975921e+07 | 61587367.2 | 23014205.50 | 6.158737e+07 | 2.751894e+07 | 61587367.2 | 6.607000e+07 | 2.301421e+07 | 2.158800e+08 | 2.105227e+07 | 6.158737e+07 | 7.448421e+07 | 6.158737e+07 | 7.460921e+07 |
| 1962 | 37682461.5 | 3.037662e+07 | 3.037662e+07 | 3.768246e+07 | 2.690995e+07 | 37682461.5 | 37682461.50 | 3.768246e+07 | 3.768246e+07 | 37682461.5 | 4.586667e+07 | 3.768246e+07 | 3.380000e+07 | 1.056492e+07 | 4.757662e+07 | 2.690995e+07 | 3.768246e+07 | 3.768246e+07 |
| 1963 | 33305376.4 | 2.190703e+07 | 3.457676e+07 | 3.878084e+07 | 4.038172e+07 | 33305376.4 | 33305376.40 | 3.330538e+07 | 3.826307e+07 | 38263073.5 | 3.330538e+07 | 3.330538e+07 | 3.459229e+07 | 2.754271e+07 | 3.330538e+07 | 3.459229e+07 | 3.330538e+07 | 3.176743e+07 |
| 1964 | 47113424.0 | 3.834271e+07 | 4.617839e+07 | 5.276892e+07 | 6.143466e+07 | 42868164.2 | 35585205.25 | 5.276892e+07 | 6.796667e+07 | 61922709.6 | 6.192271e+07 | 5.276892e+07 | 7.605776e+07 | 3.834271e+07 | 5.276892e+07 | 5.276892e+07 | 5.276892e+07 | 4.892271e+07 |
#用0填充nan值
revnue_genre_year = revnue_genre_year.fillna(0)
plt.figure(figsize = (12, 6))
plt.plot(revnue_genre_year, label = revnue_genre_year.columns)
plt.title('Average revenue by genres and year')
plt.xticks(range(1950, 2020, 5))
plt.xlabel('Year')
plt.ylabel('Average revenue')
plt.legend(revnue_genre_year)#图例
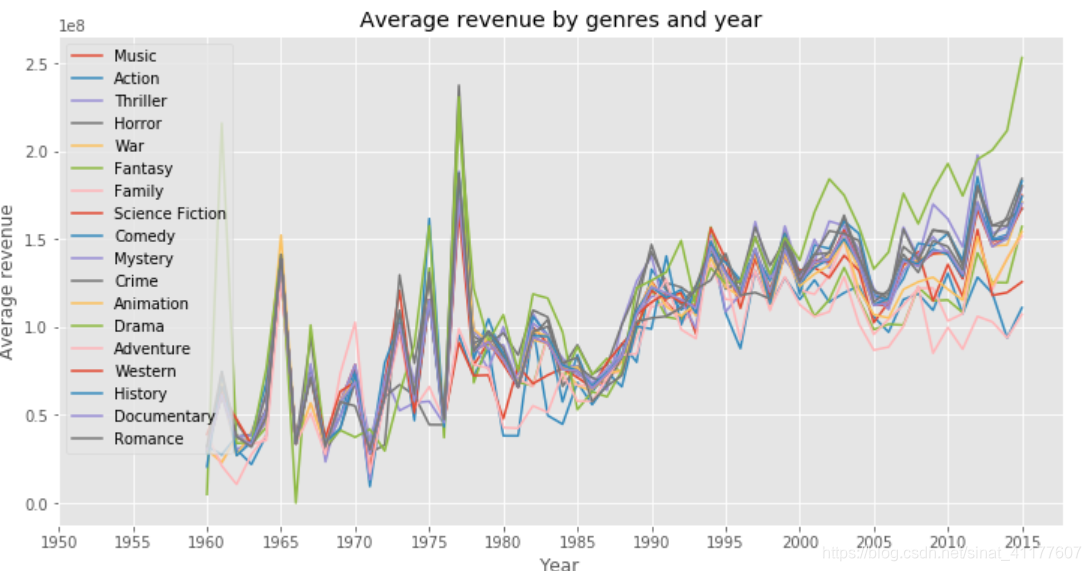
3.档期
(1)不同月份的发行数量和票房
genres_df3['release_date'] = pd.to_datetime(genres_df3['release_date'])
genres_df3['month'] = genres_df3['release_date'].dt.month
genres_df3['day'] = genres_df3['release_date'].dt.weekday
genres_df3.head()
| Music | Action | Thriller | Horror | War | Fantasy | Family | Science Fiction | Comedy | Mystery | ... | Romance | popularity | budget | revenue | release_date | vote_count | vote_average | release_year | month | day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 32.985763 | 150000000 | 1513528810 | 2015-06-09 | 5562 | 6.5 | 2015 | 6 | 1 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 28.419936 | 150000000 | 378436354 | 2015-05-13 | 6185 | 7.1 | 2015 | 5 | 2 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 13.112507 | 110000000 | 295238201 | 2015-03-18 | 2480 | 6.3 | 2015 | 3 | 2 |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ... | 0 | 11.173104 | 200000000 | 2068178225 | 2015-12-15 | 5292 | 7.5 | 2015 | 12 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 9.335014 | 190000000 | 1506249360 | 2015-04-01 | 2947 | 7.3 | 2015 | 4 | 2 |
5 rows × 27 columns
plt.figure(figsize = (18,6))
#各月份的电影票房
revenue_by_month = genres_df3.groupby('month')['revenue'].mean()
plt.subplot(1, 2, 1)
revenue_by_month.plot(kind = 'bar')
plt.title('Average revenue by Month')
plt.xlabel('Month')
plt.ylabel('Average revenue')
#各月份的电影发行数
df['release_date'] = pd.to_datetime(df['release_date'])
df['month'] = df['release_date'].dt.month
num_by_month = df.groupby('month')['revenue'].count()
plt.subplot(1, 2, 2)
num_by_month.plot(kind = 'bar')
plt.title('Number of movie by Month')
plt.xlabel('Month')
plt.ylabel('Number of movie')
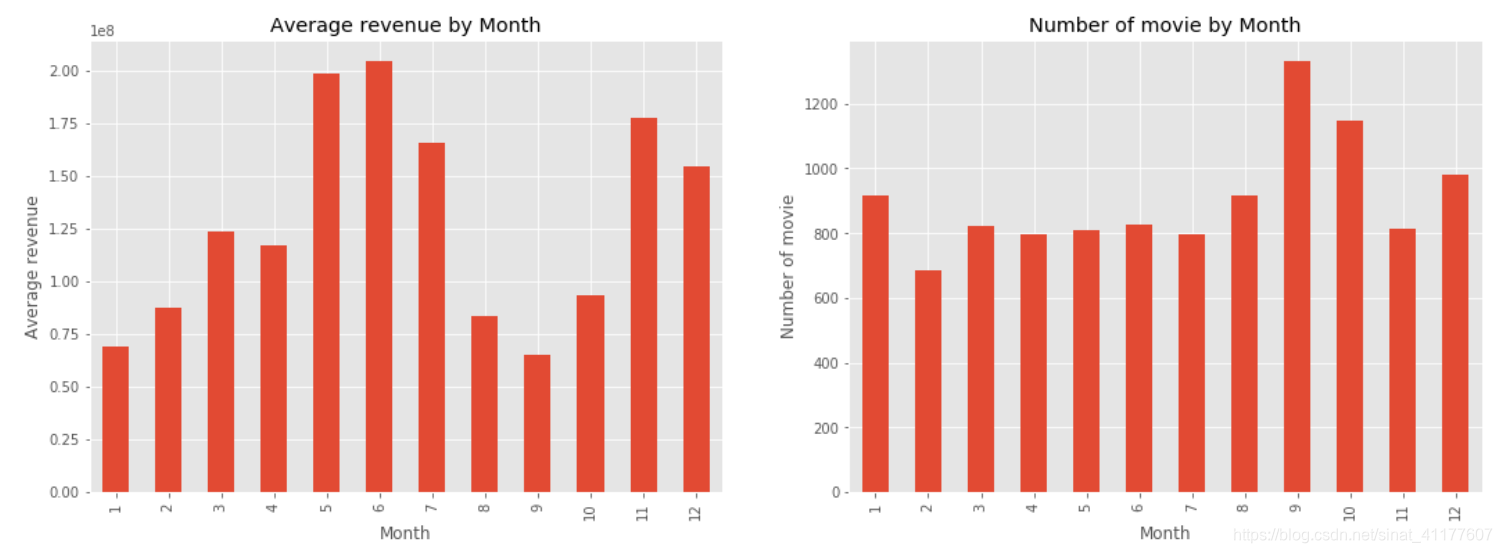
(2)不同星期的发行数量和票房
plt.figure(figsize = (18,6))
#各月份的电影票房
revenue_by_month = genres_df3.groupby('day')['revenue'].mean()
plt.subplot(1, 2, 1)
revenue_by_month.plot(kind = 'bar')
plt.title('Average revenue by Day of week')
plt.xlabel('Day of week')
plt.ylabel('Average revenue')
#各月份的电影发行数
df['release_date'] = pd.to_datetime(df['release_date'])
df['day'] = df['release_date'].dt.weekday#返回0—6,分别对应星期一到星期日
num_by_month = df.groupby('day')['revenue'].count()
plt.subplot(1, 2, 2)
num_by_month.plot(kind = 'bar')
plt.title('Number of movie by Day of week')
plt.xlabel('Day od week')
plt.ylabel('Number of movie')
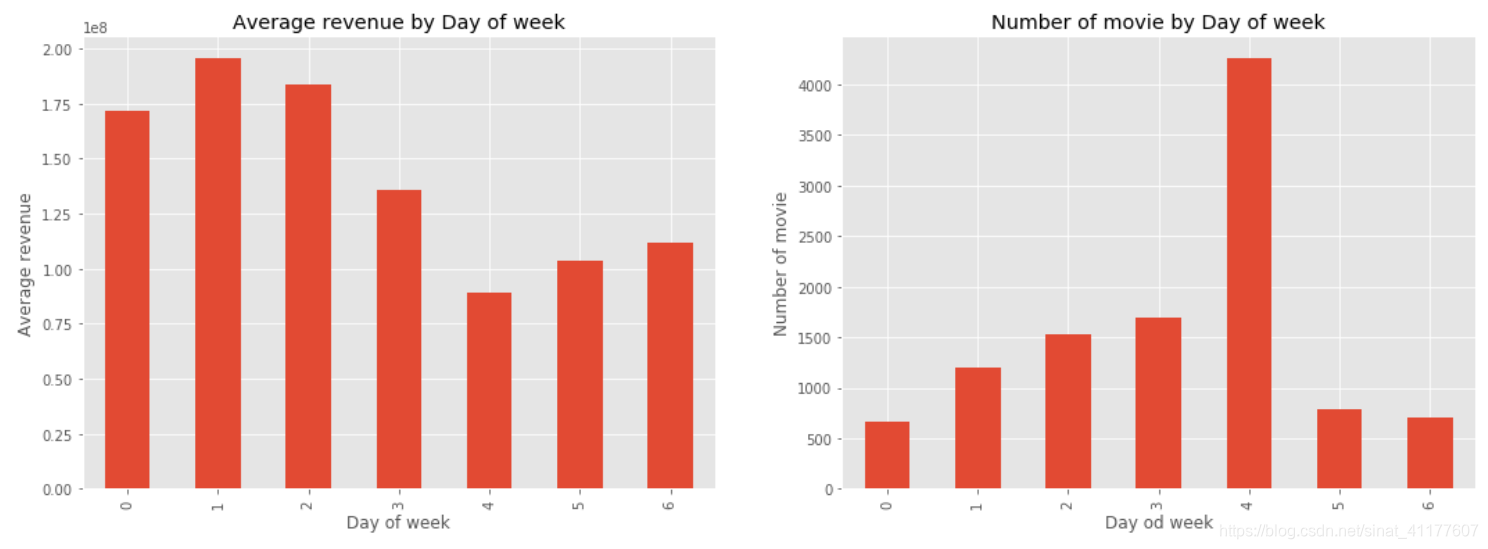
4、观众评价: 电影的评分与哪些特征有关?
(1)评分与电影类型
movie_by_genre.sort_values(by = ['vote_average'])['vote_average'].plot.barh(figsize = (10, 5))
plt.title('Average vote by Genres')
plt.xlabel('Average vote')
plt.ylabel('Genres')
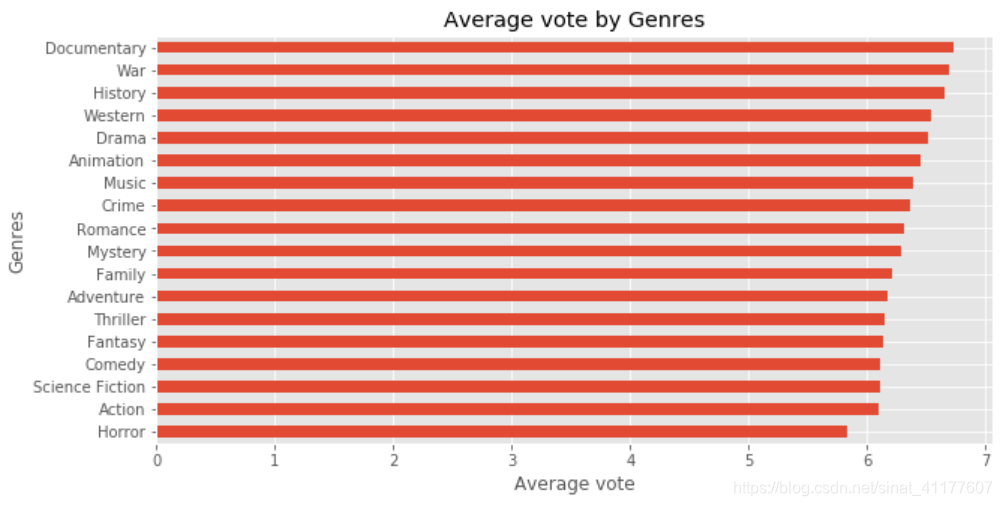
(2)评分与其他变量
plt.subplots(figsize=(8,8))#调节图像大小
sns.heatmap(df.corr(), annot = True, vmax = 1, square = True, cmap = 'Reds' )
(3)评分人数的变化趋势(2000-2015)
#不同年代的评分变化
plt.figure(figsize = (10,6))
vote_count_by_year = genres_df3.groupby('release_year')['vote_count'].sum().loc[2000:]
vote_count_by_year.plot(kind = 'bar')
plt.title('Vote count by Year(2000-2015)')
plt.xlabel('Year')
plt.ylabel('Vote count')
(4)不同年代的评分变化
#绘制箱线图
s1960 = genres_df3.query('release_year <= 1970').vote_average
s1970 = genres_df3.query('release_year > 1970').query('release_year <= 1980').vote_average
s1980 = genres_df3.query('release_year > 1980').query('release_year <= 1990').vote_average
s1990 = genres_df3.query('release_year >1990').query('release_year <= 2000').vote_average
s2000 = genres_df3.query('release_year > 2000').query('release_year <= 2010').vote_average
s2010 = genres_df3.query('release_year > 2010').query('release_year <= 2020').vote_average
plt.figure(figsize = (12, 6))
plt.boxplot([s1960,s1970,s1980,s1990,s2000,s2010],labels = ['1960s', '1970s', '1980s', '1990s', '2000s', '2010s'])
plt.title('Average Vote by Decade')
plt.xlabel('Decade')
plt.ylabel('Average Vote')
4、热度分析:电影热度与哪些特征有关?
(1)热度与电影类型
movie_by_genre.sort_values(by = ['popularity'])['popularity'].plot.barh(figsize = (10, 5))
plt.title('Popularity by Genres')
plt.xlabel('Popularity')
plt.ylabel('Genres')
plt.show()
 (2)受欢迎度与其他变量
(2)受欢迎度与其他变量
plt.subplots(figsize=(8,8))#调节图像大小
sns.heatmap(df2.corr(), annot = True, vmax = 1, square = True, cmap = 'Blues' )
绘制电影热度与评价次数、票房、预算的相关性散点图及其线性回归线
#创建电影受欢迎度与评价次数、票房、预算的数据框
poularity = df2[['vote_count', 'budget', 'popularity', 'revenue']]
plt.figure(figsize = (18,6))
#电影受欢迎度与评价次数的相关性散点图及其线性回归线
ax1 = plt.subplot(1, 3, 1)
ax1 = sns.regplot(x = 'vote_count', y = 'popularity', data = poularity, color = 'y')
ax1.text(0, 25, 'r = 0.76')
plt.title('Popularity and Vote_count')
plt.xlabel('Vote_count')
plt.ylabel('Popularity')
#电影受欢迎度与票房的相关性散点图及其线性回归线
ax2 = plt.subplot(1, 3, 2)
ax2 = sns.regplot(x ='revenue' , y = 'popularity', data = poularity, color = 'r')
ax2.text(0, 25, 'r = 0.59')
plt.title('Popularity and Revenue')
plt.xlabel('Revenue')
plt.ylabel('Popularity')
#电影受欢迎度与预算的相关性散点图及其线性回归线
ax3 = plt.subplot(1, 3, 3)
ax3 = sns.regplot(x = 'budget' , y ='popularity', data = poularity, color = 'B')
ax3.text(0, 25, 'r = 0.52')
plt.title('Popularity and Budget ')
plt.xlabel('Budget')
plt.ylabel('Popularity')
5、电影盈利情况分析:电影利润与哪些因素有关?
(1)电影利润与类型
#计算各类型电影利润
movie_by_genre['profit'] = movie_by_genre['revenue'] - movie_by_genre['budget']
movie_by_genre
| vote_average | popularity | revenue | budget | profit | |
|---|---|---|---|---|---|
| Music | 6.385000 | 1.101270 | 1.047237e+08 | 3.013560e+07 | 7.458808e+07 |
| Action | 6.099568 | 1.777369 | 1.802467e+08 | 6.309883e+07 | 1.171479e+08 |
| Thriller | 6.143093 | 1.413200 | 1.123881e+08 | 4.111380e+07 | 7.127430e+07 |
| Horror | 5.834840 | 0.974864 | 6.870872e+07 | 2.116128e+07 | 4.754744e+07 |
| War | 6.691000 | 1.412921 | 1.238682e+08 | 4.698285e+07 | 7.688537e+07 |
| Fantasy | 6.135876 | 1.916209 | 2.413179e+08 | 7.649616e+07 | 1.648217e+08 |
| Family | 6.210137 | 1.638098 | 2.320525e+08 | 6.898803e+07 | 1.630644e+08 |
| Science Fiction | 6.107522 | 2.097370 | 1.865328e+08 | 6.238452e+07 | 1.241483e+08 |
| Comedy | 6.115305 | 1.200185 | 1.200283e+08 | 3.844007e+07 | 8.158827e+07 |
| Mystery | 6.283275 | 1.300413 | 1.071573e+08 | 3.850171e+07 | 6.865555e+07 |
| Crime | 6.366004 | 1.261440 | 9.649637e+07 | 3.647491e+07 | 6.002145e+07 |
| Animation | 6.454839 | 1.821527 | 2.740895e+08 | 8.015984e+07 | 1.939297e+08 |
| Drama | 6.519188 | 1.197703 | 9.213394e+07 | 3.224194e+07 | 5.989200e+07 |
| Adventure | 6.177400 | 2.027486 | 2.392040e+08 | 7.520216e+07 | 1.640018e+08 |
| Western | 6.541026 | 1.407328 | 1.119227e+08 | 6.475754e+07 | 4.716515e+07 |
| History | 6.659633 | 1.085134 | 9.390964e+07 | 4.473635e+07 | 4.917329e+07 |
| Documentary | 6.726667 | 0.449032 | 4.494842e+07 | 8.142680e+06 | 3.680574e+07 |
| Romance | 6.317470 | 1.163230 | 1.097685e+08 | 3.171751e+07 | 7.805097e+07 |
movie_by_genre.profit.sort_values().plot.barh(figsize = (10, 5))
plt.title('Profit by Genres')
plt.xlabel('Profit')
plt.ylabel('Genres')
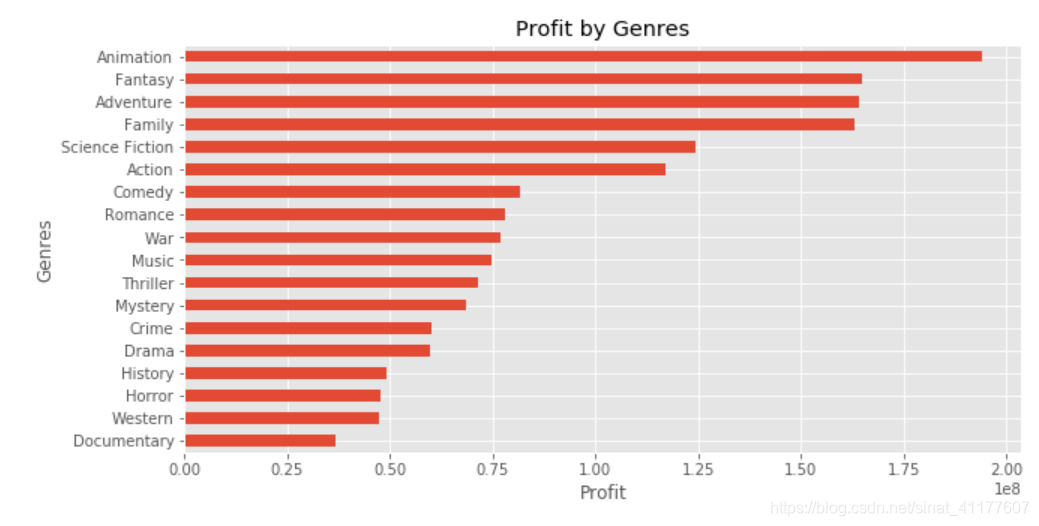
(2)各类型的投资回报率(ROI)
movie_by_genre['ROI'] = movie_by_genre['profit']/movie_by_genre['budget']
movie_by_genre
| vote_average | popularity | revenue | budget | profit | ROI | |
|---|---|---|---|---|---|---|
| Music | 6.385000 | 1.101270 | 1.047237e+08 | 3.013560e+07 | 7.458808e+07 | 2.475082 |
| Action | 6.099568 | 1.777369 | 1.802467e+08 | 6.309883e+07 | 1.171479e+08 | 1.856577 |
| Thriller | 6.143093 | 1.413200 | 1.123881e+08 | 4.111380e+07 | 7.127430e+07 | 1.733586 |
| Horror | 5.834840 | 0.974864 | 6.870872e+07 | 2.116128e+07 | 4.754744e+07 | 2.246908 |
| War | 6.691000 | 1.412921 | 1.238682e+08 | 4.698285e+07 | 7.688537e+07 | 1.636456 |
| Fantasy | 6.135876 | 1.916209 | 2.413179e+08 | 7.649616e+07 | 1.648217e+08 | 2.154640 |
| Family | 6.210137 | 1.638098 | 2.320525e+08 | 6.898803e+07 | 1.630644e+08 | 2.363663 |
| Science Fiction | 6.107522 | 2.097370 | 1.865328e+08 | 6.238452e+07 | 1.241483e+08 | 1.990050 |
| Comedy | 6.115305 | 1.200185 | 1.200283e+08 | 3.844007e+07 | 8.158827e+07 | 2.122480 |
| Mystery | 6.283275 | 1.300413 | 1.071573e+08 | 3.850171e+07 | 6.865555e+07 | 1.783182 |
| Crime | 6.366004 | 1.261440 | 9.649637e+07 | 3.647491e+07 | 6.002145e+07 | 1.645554 |
| Animation | 6.454839 | 1.821527 | 2.740895e+08 | 8.015984e+07 | 1.939297e+08 | 2.419287 |
| Drama | 6.519188 | 1.197703 | 9.213394e+07 | 3.224194e+07 | 5.989200e+07 | 1.857581 |
| Adventure | 6.177400 | 2.027486 | 2.392040e+08 | 7.520216e+07 | 1.640018e+08 | 2.180812 |
| Western | 6.541026 | 1.407328 | 1.119227e+08 | 6.475754e+07 | 4.716515e+07 | 0.728335 |
| History | 6.659633 | 1.085134 | 9.390964e+07 | 4.473635e+07 | 4.917329e+07 | 1.099180 |
| Documentary | 6.726667 | 0.449032 | 4.494842e+07 | 8.142680e+06 | 3.680574e+07 | 4.520101 |
| Romance | 6.317470 | 1.163230 | 1.097685e+08 | 3.171751e+07 | 7.805097e+07 | 2.460817 |
#各类型电影的投资回报率
movie_by_genre['ROI'].sort_values().plot.barh(figsize = (10, 5))
plt.title('ROI by Genres')
plt.xlabel('Profit')
plt.ylabel('Genres')
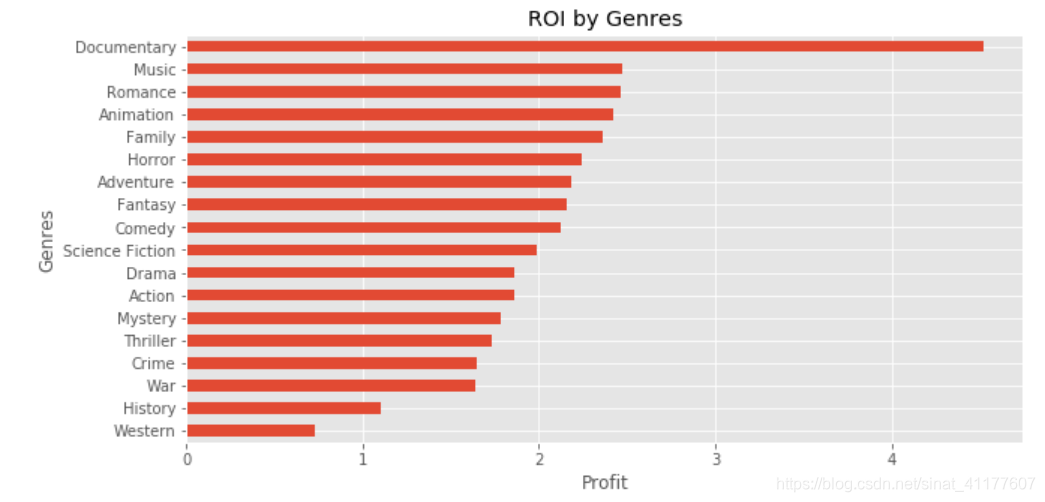
(3) 电影利润与其他变量
df2['profit'] = df2['revenue'] - df2['budget']
plt.subplots(figsize=(8,8))#调节图像大小
sns.heatmap(df2.corr(), annot = True, vmax = 1, square = True, cmap = 'Reds' )
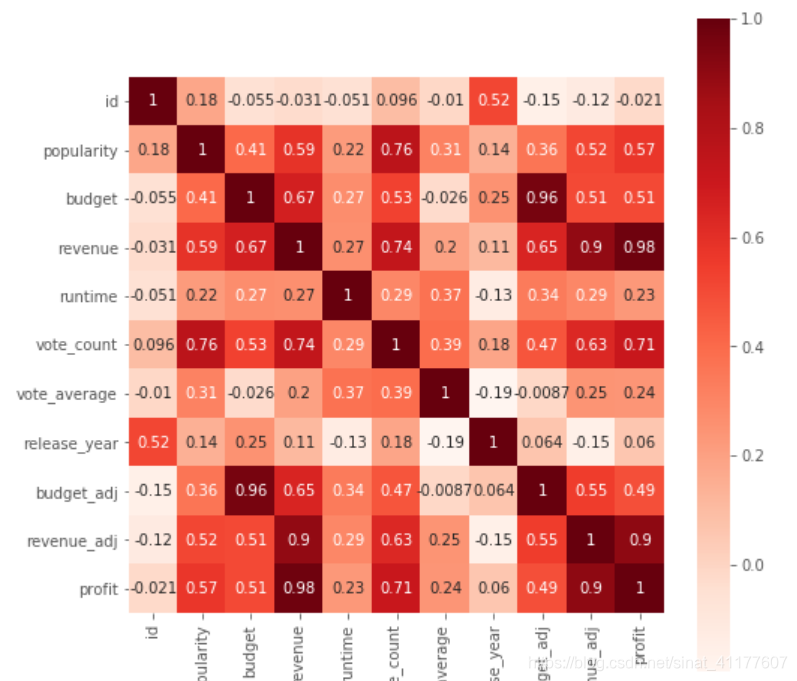
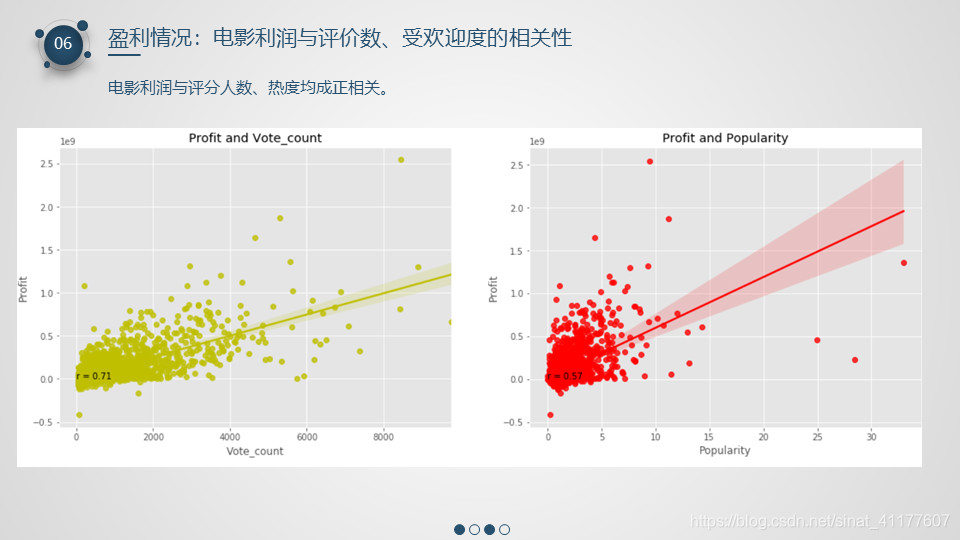
绘制电影利润与评价数、受欢迎度的散点图和趋势线
#创建利润与评价次数,受欢迎度的数据框
profit = df2[['vote_count', 'popularity', 'profit']]
plt.figure(figsize = (18,6))
#电影利润与评价次数的相关性散点图及其线性回归线
ax1 = plt.subplot(1, 2, 1)
ax1 = sns.regplot(x = 'vote_count', y = 'profit', data = profit, color = 'y')
ax1.text(0, 2.5, 'r = 0.71')
plt.title('Profit and Vote_count')
plt.xlabel('Vote_count')
plt.ylabel('Profit')
#电影利润与受欢迎度的相关性散点图及其线性回归线
ax2 = plt.subplot(1, 2, 2)
ax2 = sns.regplot(x ='popularity' , y = 'profit', data = profit, color = 'r')
ax2.text(0, 2.5, 'r = 0.57')
plt.title('Profit and Popularity')
plt.xlabel('Popularity')
plt.ylabel('Profit')
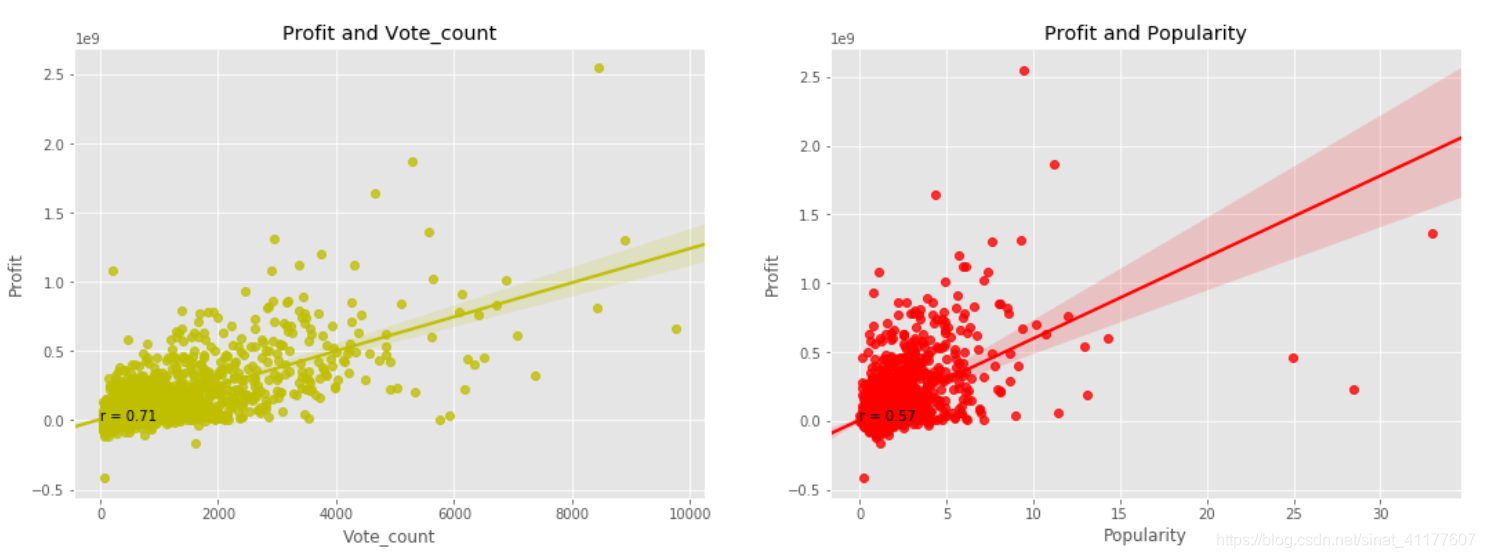

















 2223
2223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









