






 该代码片段展示了如何读取并处理SketchyCOCO数据集中annotations_trainval2017.zip文件中的caption信息,将图片ID与其对应的caption写入txt文件中以便后续使用。
该代码片段展示了如何读取并处理SketchyCOCO数据集中annotations_trainval2017.zip文件中的caption信息,将图片ID与其对应的caption写入txt文件中以便后续使用。
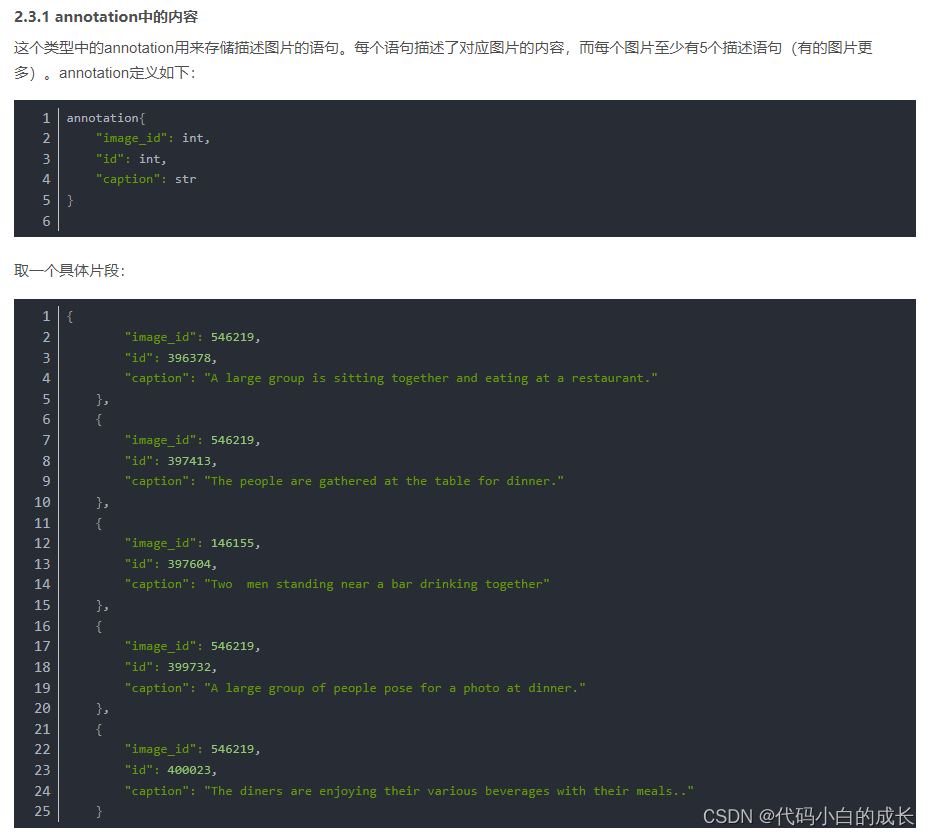
import os
import shutil
import json
captions_path = r"G:\SketchDiffusion\Sketchycoco\Dataset\annotations\captions_train2017.json"
# 读取json文件
with open(captions_path, 'r') as f1:
dictortary = json.load(f1)
# 得到images和annotations信息
images_value = dictortary.get("images")
annotations_value = dictortary.get("annotations")
# 使用images下的图像名的id创建txt文件
list=[]
id2name = dict()
for i in images_value:
list.append(i.get("id"))
id2name[i.get("id")] = i.get("file_name")
# 将id对应图片的caption写入txt文件中
txt_path = r"G:\SketchDiffusion\Sketchycoco\Dataset\caption"
for i in list:
for j in annotations_value:
if j.get("image_id") == i:
imgname = id2name.get(i).split(".")[0]
file_name = txt_path + "\\coco_" + imgname + '.txt'
if not os.path.exists(file_name):
open(file_name, 'w')
with open(file_name, 'a') as f2:
f2.write(j.get("caption")+"\n")
print('over!')
结果:
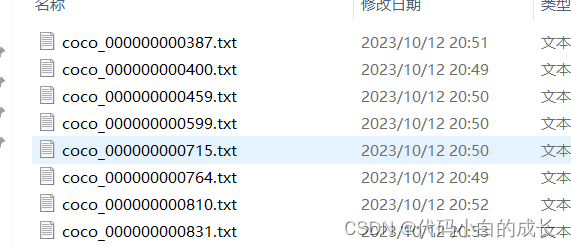



















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











