







【参考资料】
1.CSDN:python爬虫自动下载网页链接
1 需求
在 UIUC CEE300 Lab02(该链接可能已失效) 这样一个有多层且多种数据的网页上,爬取所需要的指定格式的文件(在此案例中需要爬取的是所有 .jpg 与 .csv ),并维持原层级关系:
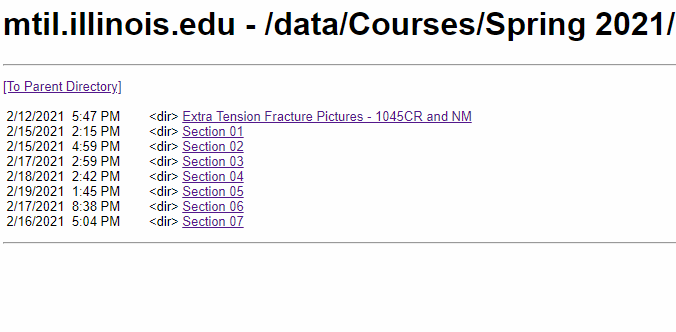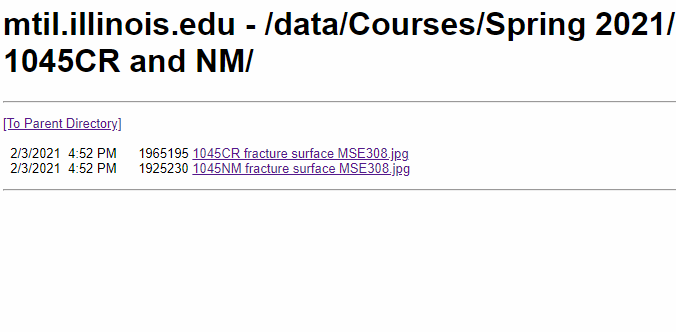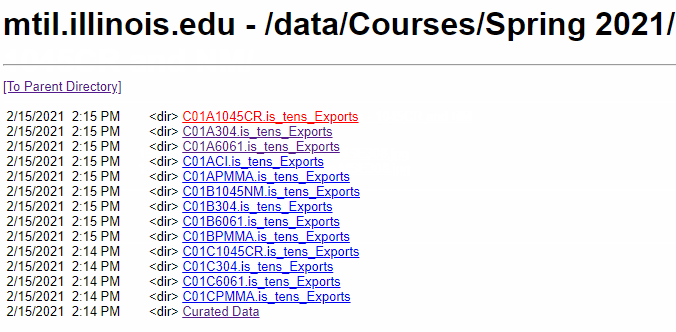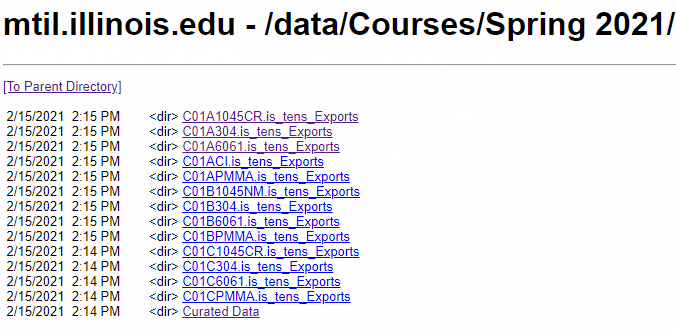
2 分析
2.1 使用以下代码分析目标网页,查看所读取的内容
import urllib.request # url request
import os # dirs
url = 'http://mtil.illinois.edu/data/Courses/Spring%202021/CEE300-TAM324/Lab%2001%20-%20Tension%20Testing/'
# pull request
headers = {'111', '666'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
content = opener.open(url).read().decode('utf8')
注意:这段代码中
headers内的内容可以随便设置,一般如果碰到HTTPError: HTTP Error 400: Bad Request这样的报错,只要自己随便更改一下其中的内容即可(除非是网站本身的问题)
随后读取 content 的内容:
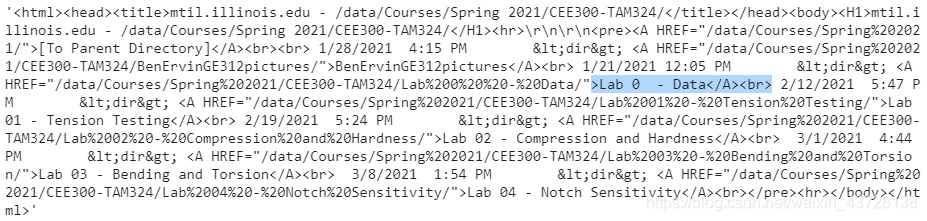
结合下图中的具体页面,可得我们所需要的信息都被包含在 > ... </A><br> 这样的一个结构中(除了 > [To Parent Directory]</A><br> ),因此可以通过一系列的判断来提取这些信息,具体代码见文末。(这里没有用到正则表达式,主要是因为目标信息比较复杂,不好构建表达式来囊括所有的信息)
2.2 下载还是访问
该案例中,链接主要有两种形式,一种是次级目录的访问链接,一种是以文件类型为后缀的下载链接。因此我们可以通过一个简单的函数实现区别:
- 如果是下载,则下载对应的文件到当前文件夹中
- 如果是访问,则在当前目录下新建一个同名的子文件夹
def downloadOrEnter(name):
# 判断是否要下载还是进入链接
# 需要下载的文件类型有:'.csv', '.jpg', '.txt'
if name[-4:] == '.csv' or name[-4:] == '.jpg' or '.txt':
return 1
else:
return 0
具体的创建文件夹以及下载文件的代码见文末
3 具体代码
引入相关库,并定义一个简易爬虫
import urllib.request # url request
import os # dirs
# pull request
headers = {'111', '666'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
定义函数 readContent,用于读取网页内容,并筛选出目标链接的信息
定义函数 downloadOrEnter,用于判断要进行下载还是访问操作
定义函数 process,主程序,实现文件夹的创建以及文件下载的功能
def readContent(opener, url):
content = opener.open(url).read().decode('utf8')
lis = []
for i in range(len(content)):
if content[i] == '<':
if content[i:i+8] == '</A><br>':
j = i
while content[j-1] != '>':
j = j-1
if content[j] != '[':
lis.append(content[j:i])
return lis
def downloadOrEnter(name):
# 判断是否要下载还是进入链接
# 需要下载的文件类型有:'.csv', '.jpg', '.txt'
if name[-4:] == '.csv' or name[-4:] == '.jpg' or '.txt':
return 1
else:
return 0
def process(opener, url, loc):
lis = readContent(opener, url)
if len(lis) == 1 and downloadOrEnter(lis[0]):
# 如果只读取到一个连接,并且这个链接是的类型为目标文件
# 则只需要进行下载操作
urllib.request.urlretrieve(url + '/' + '%20'.join(lis[0].split()), os.path.join(loc, lis[0]))
else:
# 除此之外,可能需要同时进行文件夹创建以及文件下载
for i in lis:
if downloadOrEnter(i):
# 下载文件至当前目录
urlnew = url + '/' + '%20'.join(i.split())
urllib.request.urlretrieve(urlnew, os.path.join(loc, i))
print(urlnew) # 打印已下载的文件链接,以显示进度
else:
# 在当前目录创建新的文件夹
urlnew = url + '/' + '%20'.join(i.split())
locnew = loc + '/' + i
os.makedirs(locnew[2:])
# 递归调用,直至完成全部下载任务
process(opener, urlnew, locnew)
最后运行以下代码,即可成功实现网页链接的爬取:
url = 'http://mtil.illinois.edu/data/Courses/Spring%202021/CEE300-TAM324/Lab%2001%20-%20Tension%20Testing'
loc = './data'
os.makedirs('data')
process(opener, url, loc)
运行截图:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











