









0. 前言
本文是2019年发表在IEEE Transactions On Image Processing期刊上的一篇关于弱监督的城市场景语义分割的文章,文章中采用两个域分类器进行对抗训练,从而提高模型的性能。
1.本文动机
- 现有方法在合成数据上训练的模型在真实数据上应用时性能不佳。(换言之,训练数据和测试数据存在域间漂移,导致网络泛化性能不佳);
- 现在还没有利用弱监督学习来解决全场景分割问题的算法。
2.本文方法
为更好讲解本文方法,首先先定义一些数学符号:
- S \mathcal{S} S表示合成数据的域
- T \mathcal{T} T表示真实场景数据的域
- I S I_\mathcal{S} IS表示合成数据集里的图像
- I T I_\mathcal{T} IT表示真实场景数据集里的图像
- A S o b j A_\mathcal{S}^{obj} ASobj表示合成数据集里的图像的目标级标签
- A S p i x A_\mathcal{S}^{pix} ASpix表示合成数据集里的图像的像素级标签
- A T o b j A_\mathcal{T}^{obj} ATobj表示真实场景数据集里的图像的目标级标签
为了让标签获取有更小的代价,本文使用弱监督学习的方法,所以真实场景的数据集里只有目标级标签,也就是Inexact的标注。所以本文一下的方法的设计,都是针对只有合成数据有pixel-level和object-level的标签,而真实数据只有object-level标签的情况。
整体方法pipeline如下图所示:(这个图中有一处小错误,Target Domain下面应该是only object-level labels)
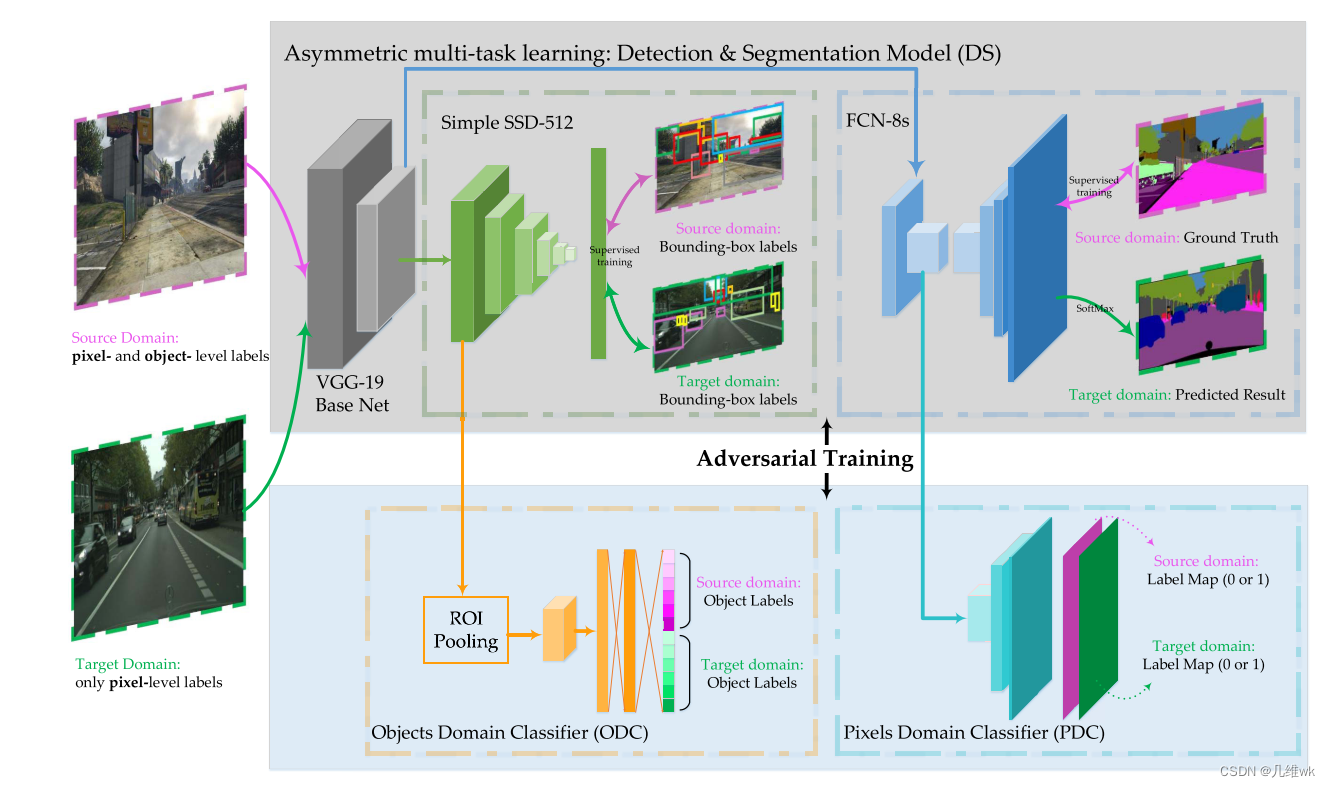
2.1 弱监督分割
之前的方法大多基于FCN,因为FCN比较关注图像的local feature,比如纹理特征、颜色特征等等,这些local特征在不同数据域上的表现是不同的,所以面对cross-domain的数据,FCN的就远不如面对one-domain那样从容。这时,图像的structured feature就十分重要,因为它是在不同的域上表现都差不多的图像的最根本特征,也可以称作domain-invariant feature. 同时,因为对于真实的数据,我们只有object-level的标签,所以之前的全监督方法对于分割任务根本无法使用,故只能采用半监督的方式。
综上所述,我们需要一个分割方法,它既能兼顾图像的structured、local 特征,还能使用object-level标签来训练出分割网络,故本文首先提出了一个Detection and Segmentation stream (DS),如整体pipeline图的上半部分所示。DS结构包括Base-Net、SSD-512 detection Network和FCN-8s Segmentation Network,可以说是一个把分割和检测融为一体的多任务模型。DS的输入包括
I
S
I_\mathcal{S}
IS和
I
T
I_\mathcal{T}
IT,
I
S
I_\mathcal{S}
IS既有pixel-level又有object-level的标签,所以参与整个网络的训练,而
I
T
I_\mathcal{T}
IT只有object-level的标签,所以它只参与SSD-512的训练。整体的损失函数如下:
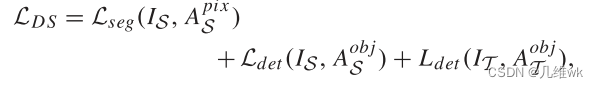
作者甚至没有加权,只是简单粗暴地把分割和检测的损失加到一起。
2.2 对抗学习适应不同域
2.1中提出的DS弱监督DS框架,能够学习到一些domain-invariant特征,但是纹理、颜色等local特征在不同域上的缺口还没有被学习到。所以这里引入对抗学习,训练一个辨别器去区分特征属于哪个域,训练一个生成器生成特征去迷惑辨别器。
本文依据对抗学习的思想,引入两个辨别器:PDC和ODC,分别辨别像素级和目标级的特征,之前的弱监督框架就可以看做生成器,通过对抗学习就能够让网络适应不同的域。
2.3 像素级域适应
PDC如图所示,是由一个卷积层和两个反卷积层组成,输入为像素级特征,输出为通道数为2的label图。
训练PDC的损失函数如下:
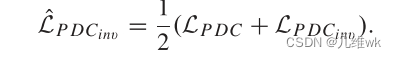
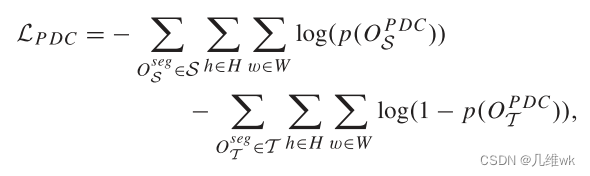
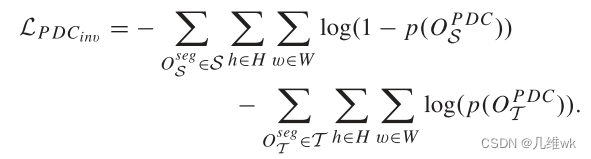
这个损失函数包括两项
L
P
D
C
\mathcal{L}_{PDC}
LPDC和
L
P
D
C
i
n
v
\mathcal{L}_{PDC_{inv}}
LPDCinv,
O
S
P
D
C
O_{\mathcal{S}}^{PDC}
OSPDC和
O
T
P
D
C
O_{\mathcal{T}}^{PDC}
OTPDC分别表示两个通道的label图,也就是PDC最后的输出,而
p
(
.
)
p(.)
p(.)表示经过SOFTMAX。当你最小化
L
P
D
C
\mathcal{L}_{PDC}
LPDC时,
p
(
O
S
P
D
C
)
p(O_{\mathcal{S}}^{PDC})
p(OSPDC)是变大的,
p
(
O
T
P
D
C
)
p(O_{\mathcal{T}}^{PDC})
p(OTPDC)是变小的,故而判别器能够更好的识别source类。对称地,在优化
L
P
D
C
i
n
v
\mathcal{L}_{PDC_{inv}}
LPDCinv时,判别器能够更好的识别target类,这样优化整体就能够训练好一个domain classifier,使得其能够区分pixel-level的特征属于哪个domain的特征。这个非常对称的损失函数可以理解为二分类交叉熵损失的变体,但是我没想明白为啥不直接用二分类交叉熵损失,或者用这个损失函数的意义在哪里?
训练的过程就是交替优化下面的式子:
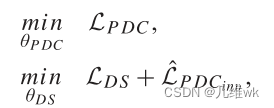
先固定DS的参数,优化
L
P
D
C
\mathcal{L}_{PDC}
LPDC以获得PDC的参数,然后固定PDC,通过优化
L
D
S
+
L
^
P
D
C
\mathcal{L}_{DS}+\mathcal{\hat{L}}_{PDC}
LDS+L^PDC
2.4 目标级域适应
目标级域适应构建一个目标级域分类器(ODC),通过对抗学习,有助于更好地提取出domain-invariant特征。
ODC的输入是从Base-Net输出的特征图,可以看做是目标级特征,这个特征经过ROI-pooling的操作(其它论文的方法)获得比较准确的目标特征,然后通过几层网络最后输出一个向量,这个向量由2N个置信度组成,1-N表示source域,N+1-2N表示target域,比如其中第4个置信度(N>4)就表示这个目标是source域的第4类的概率。
优化ODC,很好理解,采用交叉熵损失,因为是两大类中细分了N小类,所以有两个交叉熵加到一起,如下:

接下来的操作我不太能理解,作者又提出了个inverse的损失:
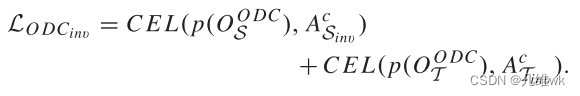
这个的区别好像就是把两个大类交换了一下位置,比如原来1-N表示source域,现在N+1-2N表示source域。
把这两个合到一块,就有一个域混淆目标函数如下:
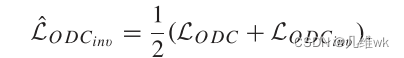
整体的学习过程如下:
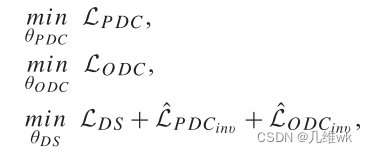
如此看来,PDC和ODC引入的inverse损失都是在更新DS的参数才用到的,这是为了让DS能够更好地提取object-level和pixel-level的特征,而在训练PDC或ODC的参数时,并不使用inverse的损失。
一个小小的疑问:
L
O
D
C
\mathcal{L}_{ODC}
LODC是两个交叉熵损失的合体,优化它很显然能够训练好一个ODC。但是
L
P
D
C
\mathcal{L}_{PDC}
LPDC好像仅仅是关注其中一类?它能够训练好PDC吗。
3.总结
本文着眼场景分割,主要解决在合成数据上训练的模型在真实数据上测试的性能下降的问题。通过构建一个DS网络,提取不同域中的object-level和pixel-level的特征,通过ODC和PDC进行对抗训练,从而使得DS能够更好地提取出domain-invariant的特征。整个训练过程中,Target域的数据只用到了object-level的标签,通过不精确(inexact)监督学习实现了Target域上的比较好的分割结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









