









1. 传统GAN回顾
GAN网络有一个生成器和一个判别器,生成器的输入是一个随机噪声,输出是生成的图像,而判别器的输入是一副图像,输出是0或1,也就是fake或者real(可以理解为二分类)。判别器判别一副生成的图像是真的还是假的,而生成器的目标是生成能够骗过判别器的图像,如此对抗学习下去,判别器能够变得更强,能够更好地分辨一幅图像是real还是fake,而同样地,生成器也能够变得更强,生成出几乎判别器也无法判别出真假的图像。
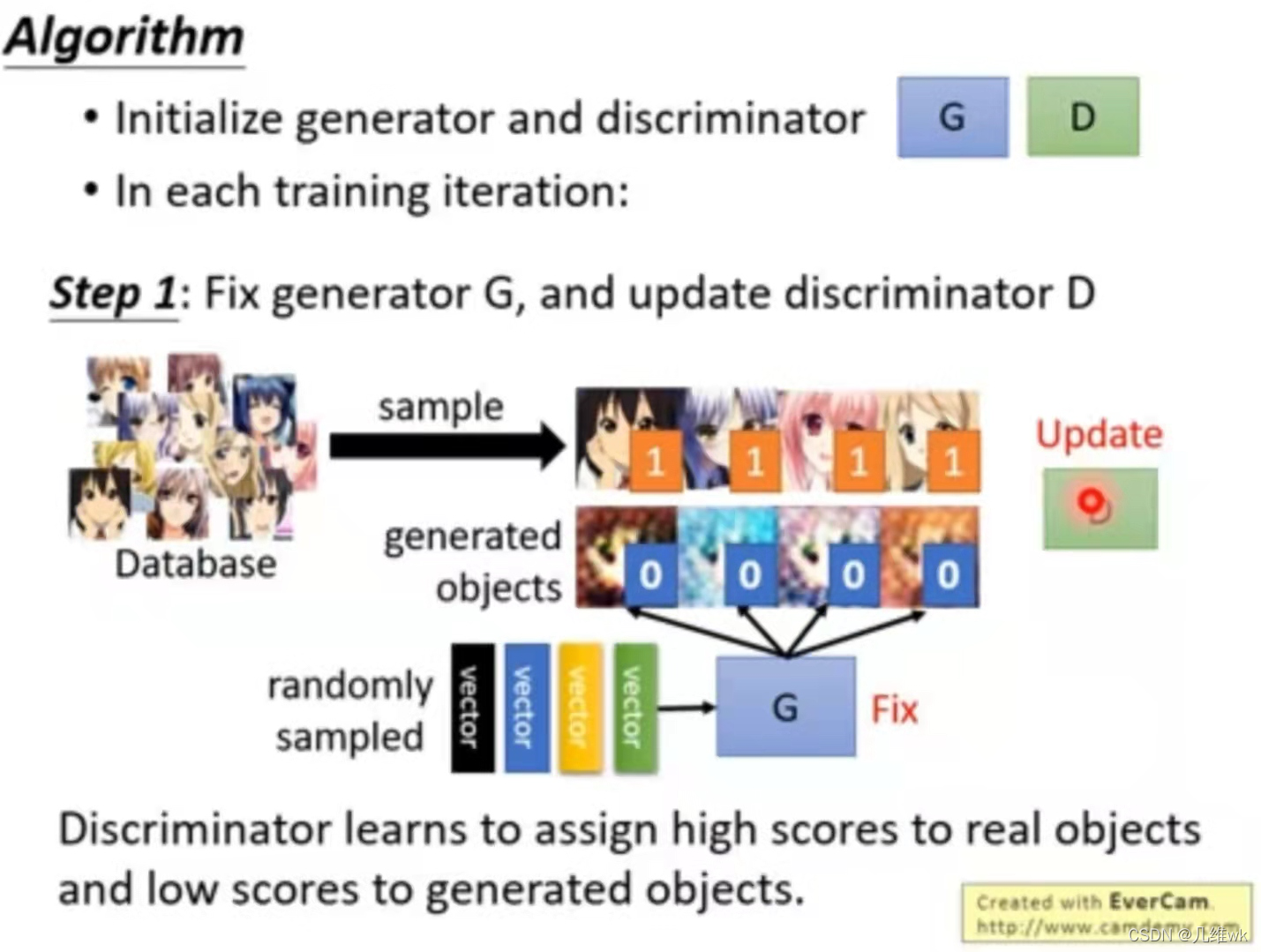
训练GAN网络的第一步是固定生成器,更新判别器,生成器生成的图像是fake,数据集(Database)中的图像是real,训练判别器学会判别这两类图像。
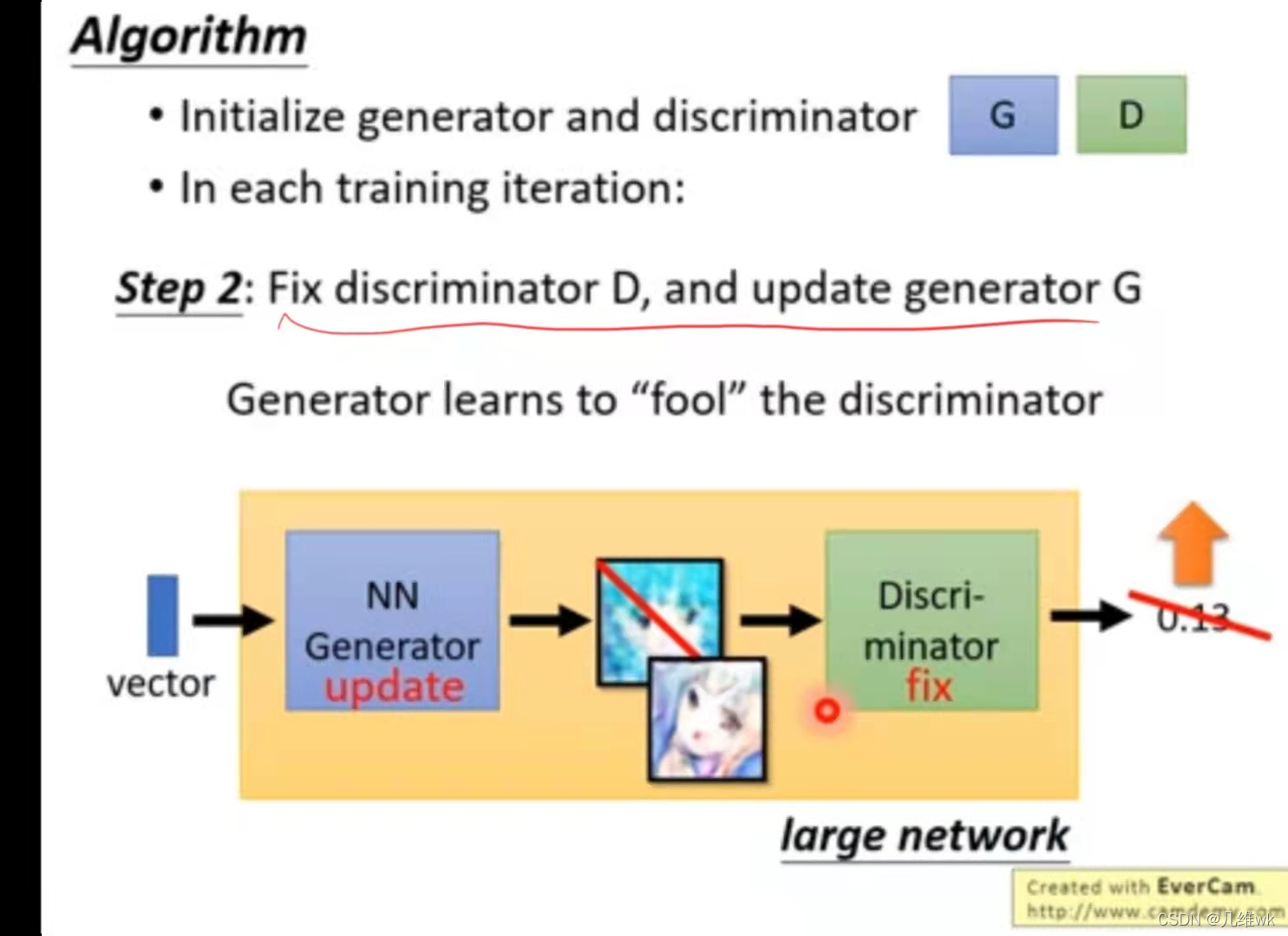
第二步,假设判别器已经能很好地判别real和fake,把判别器的参数固定,更新生成器的参数,此时可以把生成器和判别器这两部分看成一个大网络,训练的时候最后几层的判别器参数时固定的,训练的目标就是让最后的概率值更大(判别器判别生成器生成的图像为real的概率)。
如此反复循环,即可训练好生成对抗网络。

损失如上图。
2. 本文动机
本文想要通过条件生成对抗网络来实现图像到图像的转换。(之前的生成网络是实现噪声到图像的转换)。
应用L1loss和L2loss这类损失时,对高频信息不能做出贡献,仅仅能表示出低频信息,导致生成的图像比较模糊,所以设计PatchGAN的方法来解决这一问题。
3. 本文方法
传统GAN网络学习的是噪声z到y的映射,而条件GAN学习的是从观测图像x和z到y的映射,这个观测图像x可以理解为增加的条件。而与创痛的GAN不同的另一点是,在训练判别器时,不仅要把生成的图像送入判别器,还要把条件一起送入,比如下面的这个图:
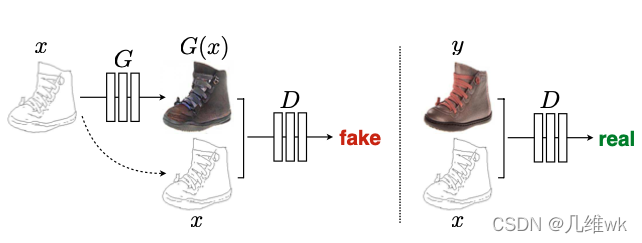
这里的x实际上就是条件,我们如果是要训练一个从边缘到图像的映射,采用条件GAN,它的判别器是需要这样训练的(应该可以理解为两张图cat在一起送入判别器)。
3.1 目标函数
加上条件之后,GAN网络的目标函数也略有不同,如下:
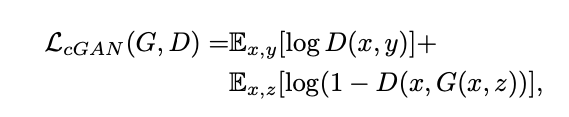
D(x,y)是真实图像y被判别器判别为真实的概率,D(x,G(x, z))是生成图像G(x, z)被判别为真实的概率。前面说过,判别器的输入不仅有图像,还有x,同样的生成器的输入也有条件x,所以这个式子里存在x。
在训练生成器时,我们是要最小化这个目标函数,达到的效果就是让D(x,y)减小,D(x,G(x, z))增大,让生成器生成的图像更容易被判别为Real。
而在训练判别器时,我们是要最大化这个函数,达到的效果是让D(x,y)增大,D(x,G(x, z))减小,因为y就是真实的图像,我们要让判别器能够更好地辨别出真实图像。
这样循环下去,即可实现我们让生成器生成能够判别器的图像,同时判别器能够很强地判别图像是真是假的目标。
之前的方法还发现了在GAN的目标函数中混入传统的损失,例如L2或L1损失也能够实现一个更好的效果,这是因为生成器不仅要能骗过判别器,而且还有尽可能生成与ground truth相近的图像。作者发现L1损失相比L2损失,能够带来更少的模糊,所以最终采用L1损失,如下:
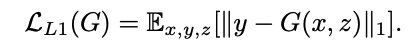
所以最终的目标函数如下:
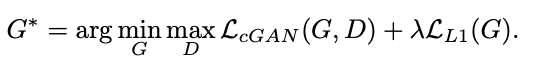
那么有人可能会有疑问,为啥都有了x还要加噪声z呢?直接用x生成对应的图像会不会更?这里文章的解释是,如果没有噪声z,这个网络可能还会学习到一个从x到y的映射,但是可能会一直产生比较确定的输出,因此就不能匹配其它的分布。就可能我输入的是一个边缘,他满足于某个Z分布,生成的图像还基本满足于某个Z分布,这就限制了网络的性能。而加了随机的噪声,网络就会产生一个比较随机的输出,也就是增加了随机性,效果更好。(这里理解不是特别透彻,文章中还说作者一开始不能很好地把噪声融入进去训练,因为生成器会学习如何忽略这个噪声,导致结果的随机性变低。为了避免这样的问题发生,作者采用dropout的形式来输入噪声,我理解的是可能在有的时候输入噪声,有的时候不输入噪声,在训练和测试的时候都这样操作,从这来看噪声可能和x是直接加到一起的,并不是cat的,这样做下来,网络的输出就具有了一定的随机性,效果会比较好。)
3.2 PatchGAN
加入L1loss或L2loss时有点小问题,那就是生成的图像比较模糊,并且大多情况下他们不能对生成的图像的高频清晰度做出贡献,仅仅能够捕捉低频信息,如下图

本文解决的方法是设计了一个PatchGAN的方案,它主要是在判别器训练上采用了一些新的策略。
在PatchGAN训练判别器时,不是把整个图片直接放进判别器中进行判别,而是像下面这样,先把一幅图切成NxN的小块,再把每个小块送入判别器中进行判别,最后把整体的结果取平均。这样做就达到了一个不错的效果,实现起来采用卷积的方式阐述更少,在大图像上运行得更快。作者还在文中介绍PatchGAN的这段说了一下其实PatchGAN也可以被理解为一种纹理损失。
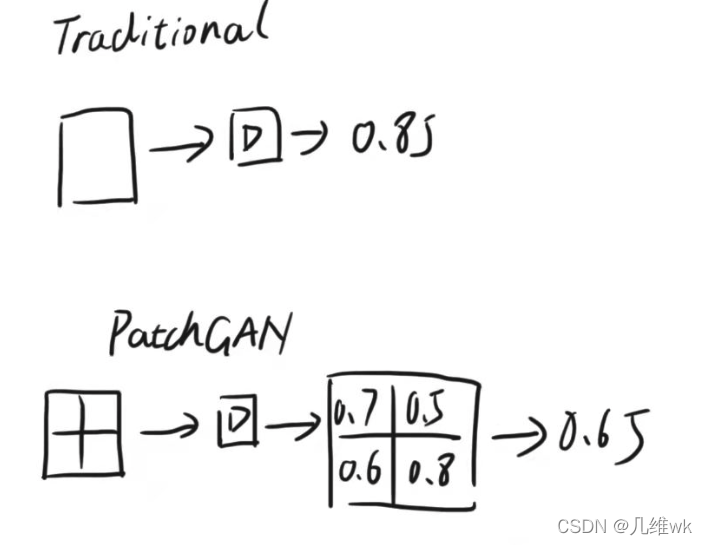
在这里插入图片描述

















 8208
8208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}