










0. 经典CAM技术发展时间线

1. 开山之作:Learning Deep Features for Discriminative Localization
Learning deep features for discriminative localization发表在2016年CVPR上。
1.1 动机与发现
本文发现将CNN在学特征时,会学习到位置信息,即使标签只有图像级标签。结合NiN(Network in network)里提出的全局池化和本文的CAM,就可以将这种位置信息用到很多其他的任务上去。

1.2 方法
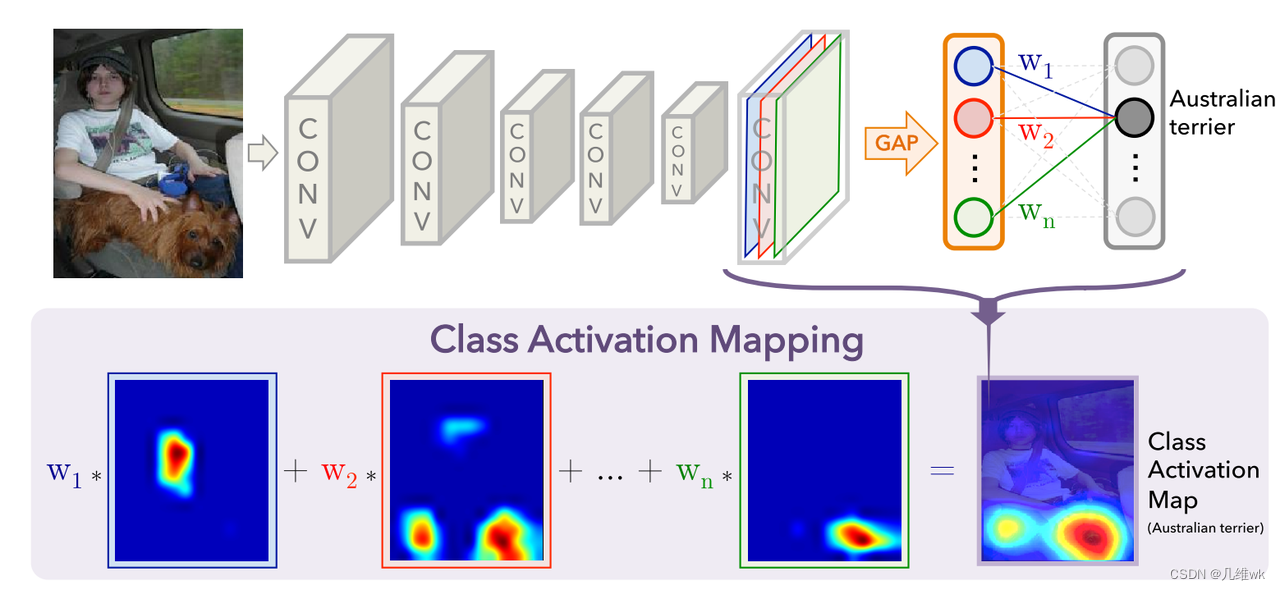
GAP指的就是NiN里提出的GLobal Average Pool。
本文的backbone是和NiN和GoogleNet类似的。
图中画的权重其实就是分类头最后一层的权重,激活图就是以这样的权重将卷积层最后一层的特征组合到一起的。
2. Grad-CAM:Visual Explanations from Deep Networks via Gradient-Based Localization
本文发在ICCV 2017,IJCV 2019都有发表。
2.1 动机
使CAM不局限于使用GAP,而适用于所有的CNN模型中,不需要重新训练和更改结构,也不局限于图像分类任务。
2.2 本文方法
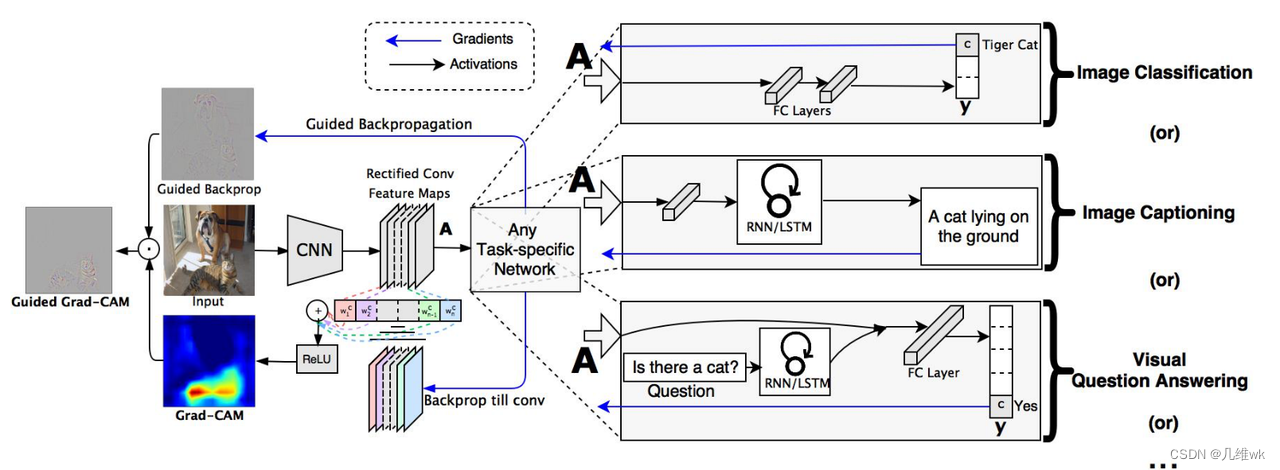
本文方法关键就在于权重的获取,之前的CAM是通过GAP生成特征向量,特征向量通过一个FC生成最后的分类向量结果,这个FC的权重就是特征组合为CAM的权重。CAM依赖GAP和FC,这是它方法的局限。而本文方法可以免除这种依赖,各种任务下都有一个yc,比如在分类任务中,yc其实就是logit回归的结果,经过softmax就是最终的分类结果。使用这个每个通道的特征矩阵对这个yc做偏导,然后进行GAP就会获得一个权值,这个权值就作为CAM组合的权重,具体公式如下:

通过实验,作者发现加个ReLU,效果更好。
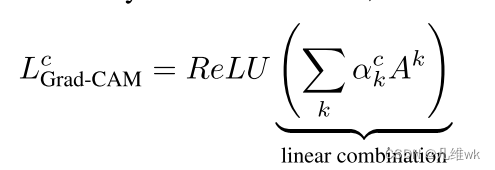
3. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks
本文仅仅发表在Arxiv.org上。
3.1 动机
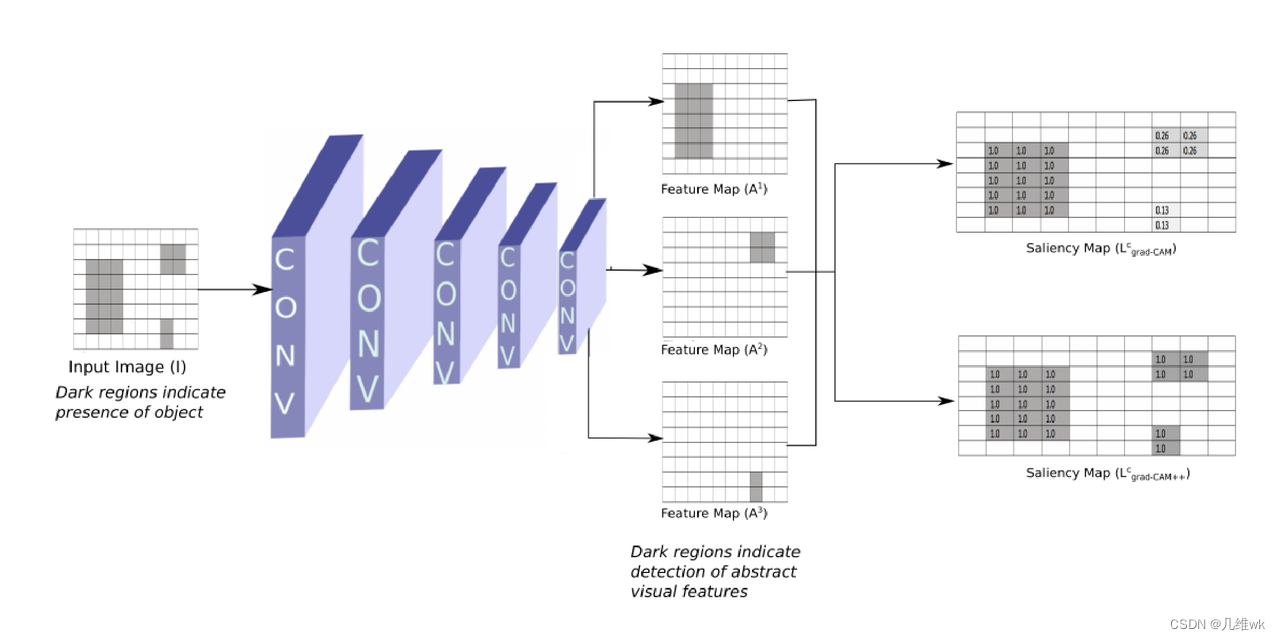
本文目的很简单,就是要基于Grad-CAM来提高其的性能,让CAM激活的位置更加准确,像素更加精确。对于多个目标,也要解决Grad-CAM激活单一的问题。
从直觉上来看,与Grad-CAM方法对比,Grad-CAM++方法的提高表现如下:
3.2 本文方法
从CAM到Grad-CAM再到Grad-CAM++三个CAM的方法总结如下:
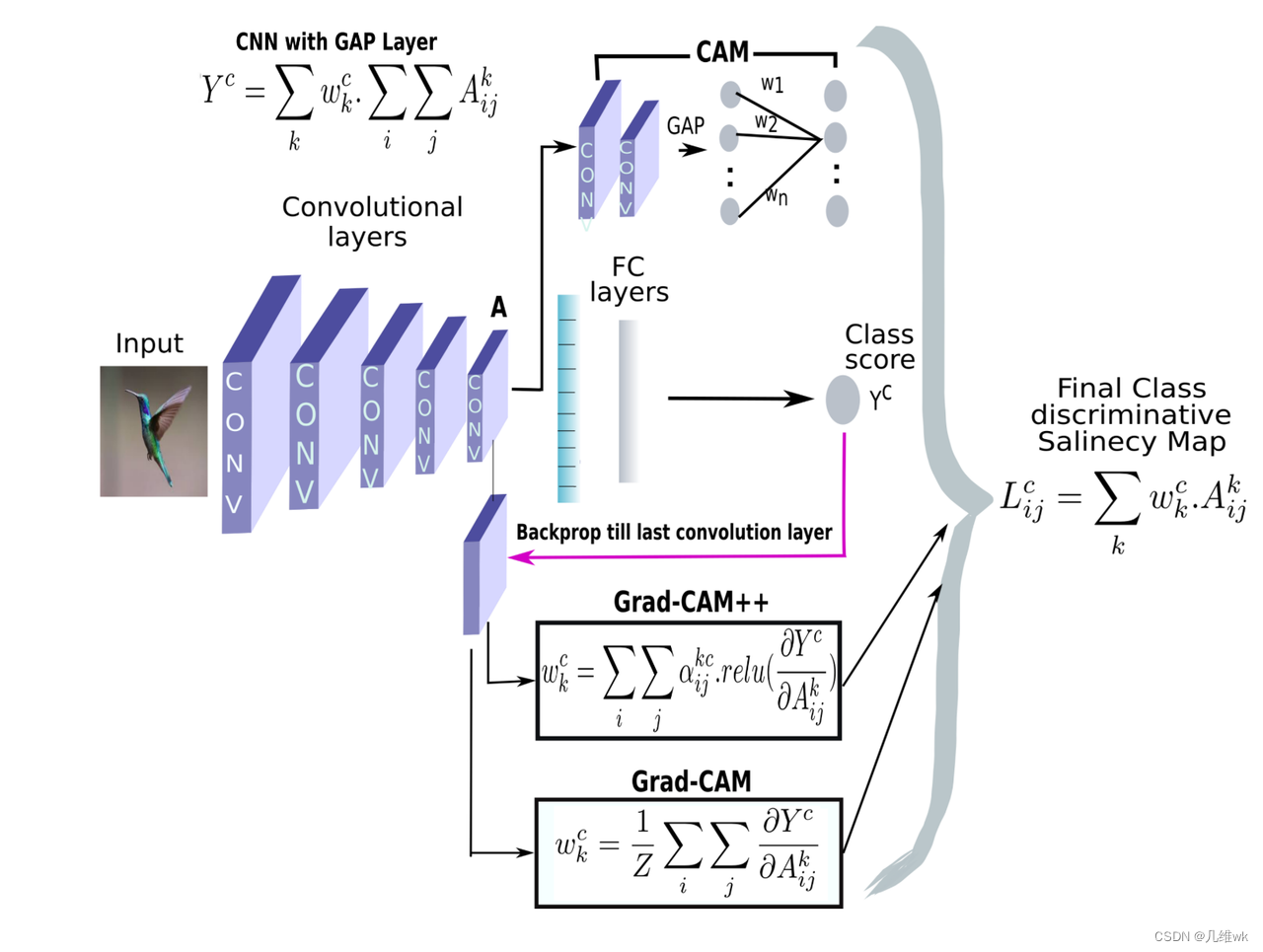
其实最大的区别就是Grad-CAM++在获得权重时,并不是使用全局平均池化,而是使用一个权重来代替,对于对应Ak的梯度的每一个元素会有一个权重与其相乘再相加获得最终的权重,而不是之前直接的平均池化,如下:
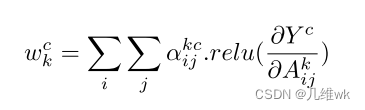
那么这篇文章的关键其实也就是怎么求这个每个元素的权重。
这个权重的获得是受到CAM和Grad-CAM的启发,他们这两个工作都基于有一个基本假设,那就是类别c获得的分数Yc满足下面的式子:
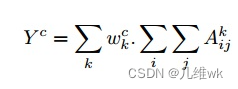
这个式子就是最后一层卷积的线性求和的运算,那么我们其实想获得的就是中间的权值来获得CAM,原始的CAM获得它就是把最后的FC的权重直接拿出来,Grad-CAM是求了梯度然后求全局平均池化,那么本文其实是下面这样获得这个权重:
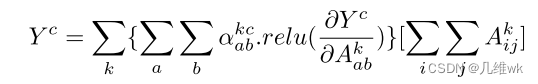
对上面这个式子两边求偏导,则有(保持一般性,将relu先去掉):
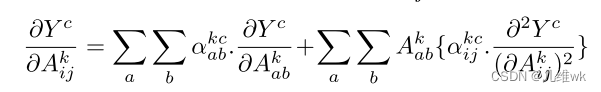
再求一次偏导:
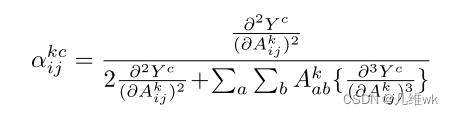
整理一下:
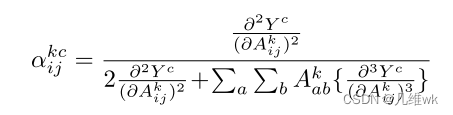
那么实际上,Grad-CAM++的激活图权重如下:
[图片]
至此,明白了Grad-CAM++的激活图权重的来源。
从这个式子来看,如果前面这一坨刚好等于1/Z,那么Grad-CAM++就退化为Grad-CAM,Grad-CAM的激活图权重如下:
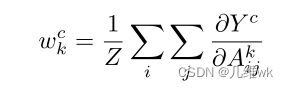
上面的那个二阶导数计算,原则上Yc可以是任意的结果,但Yc必须是个光滑函数(因为只有光滑函数的各阶导数都存在)。但是实际上Yc不一定是一个光滑函数,这里需要把倒数第二层的输出经过一个指数函数,这样再获得Yc,它就是一个无限可微的函数了,也就可以求高阶倒数了。
这样整个计算的关键在于怎么求里面的二阶导数。求得过程如下:
- 先简单的把导数第二层经过了一个exp函数,也就求出了Yc的一阶偏导;
Sc的一阶偏导在pytorch这样的框架里就很容易能得到了。
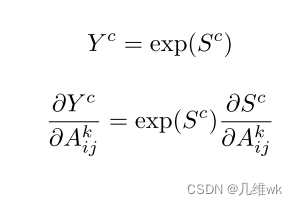
- 接着求二阶偏导和三阶偏导:
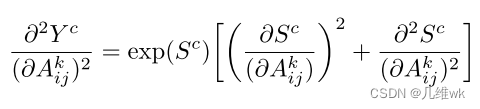
二阶偏导有些复杂,不过有ReLU为激活函数,假设ReLU为f(x),实际上它是不可导的,但是可以根据下面的式子来计算它的导数:

这样,刚才的二阶导后面的那一项就变为零:
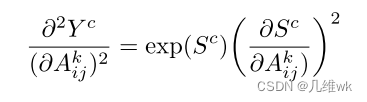
类似的我我们可以求三阶偏导:
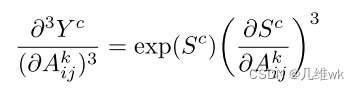
- 最终带入原来求CAM权重中的像素权重的式子,如下:
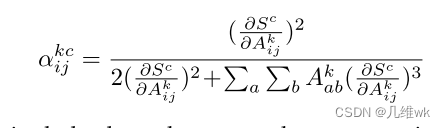
那么至此,上面的式子计算的就都是一阶偏导了,就不会存在高阶不可导的情况了。
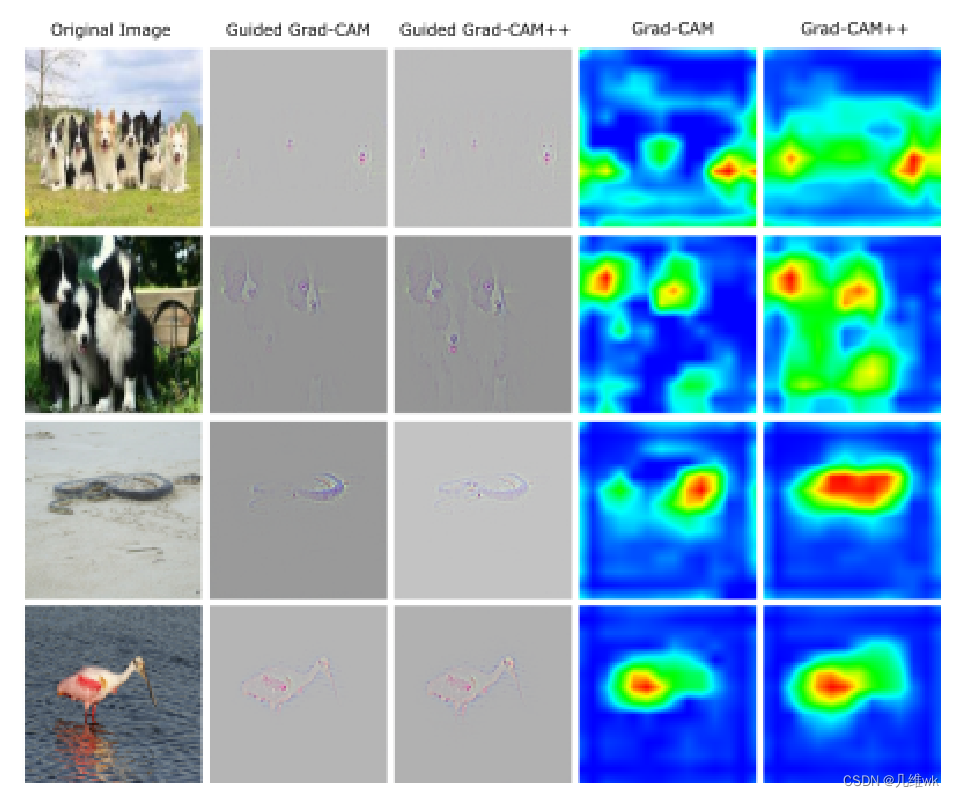
从论文里的一些结果来看,这样加了个权重,确实效果变好了,更加精细了:
4. Smooth Grad-CAM++:An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models
4.1 动机
本文其实就是对Grad-CAM++进行改进,Grad-CAM++存在显著图的清晰度不高、多目标定位不准确的问题,本文尝试解决这个问题。
4.2 方法
本文用到的方法比较简单,只是说Grad-CAM++只用到一层的特征图,而本文就用多层特征图来进行平均梯度,从而获得CAM。
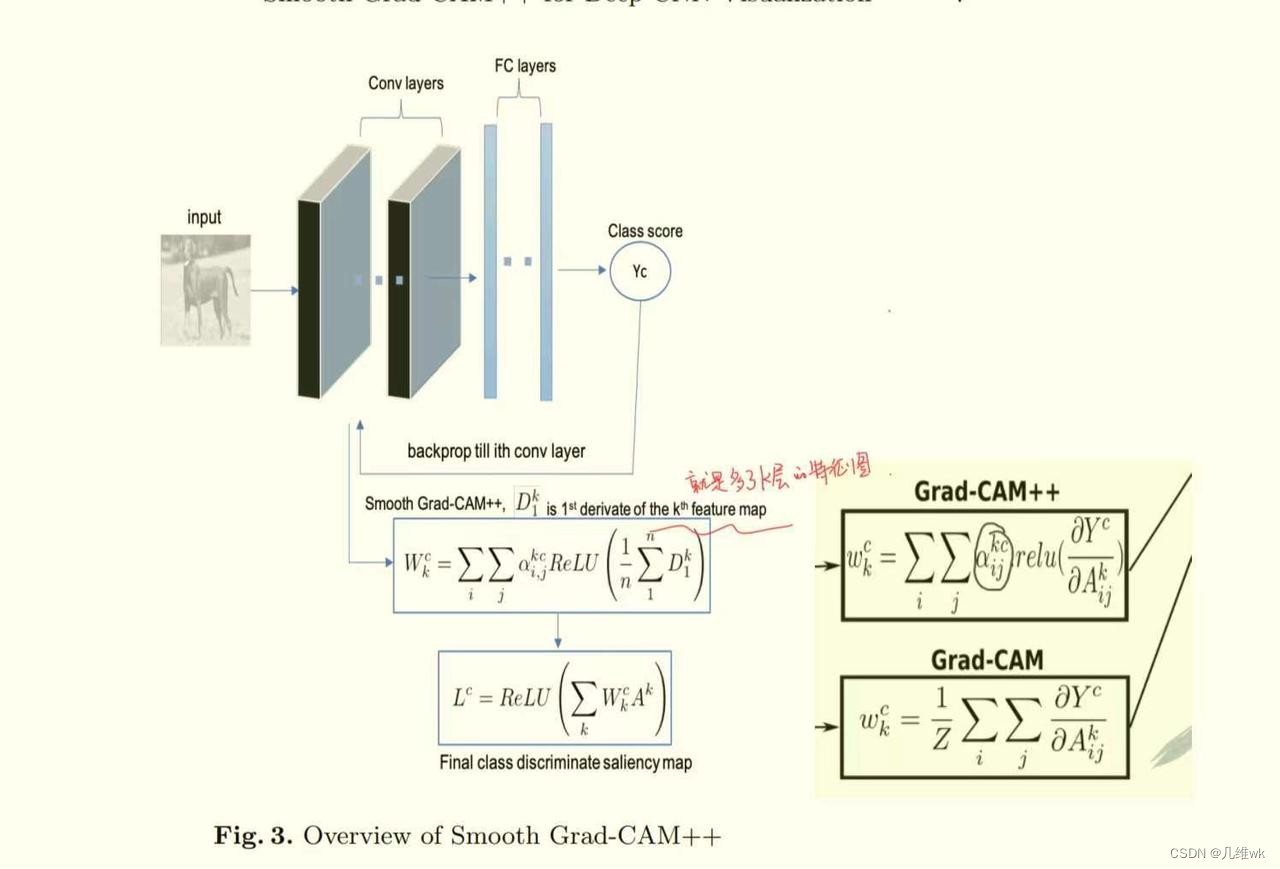
没有啥更多的内容了,感觉创新性很有限。
5. Score-CAM:Score-weighted visual explanations for convolutional neural networks
本文于2020年发表在CVPRworkshop里。
5.1 动机
本文工作的动机有如下几个:
- Grad-CAM依靠梯度,可能面对梯度饱和和梯度消失的问题(Sigmoid可能梯度饱和,ReLU可能梯度消失),这样就可能导致CAM激活目标的性能下降;
- 实际的网络中,可能出现权重较高的激活图对网络贡献较低的情况,所以直接加权激活图可能不能获得较好的CAM;
- 基于Mask的可视化方法更加符合人类直觉,通过将图像上的部分移除和保留直接来衡量该区域对于网络决策分数的影响,就可以生成CAM;
5.2 方法
前面动机提到了基于Mask的可视化方法的基本逻辑,其实该方法的关键就在于如何自动的生成有效的Mask。本文方法的关键也就在于如何生成Mask,其实只是简单地利用了特征图进行下采样,就作为Mask,具体的方法流程如下:
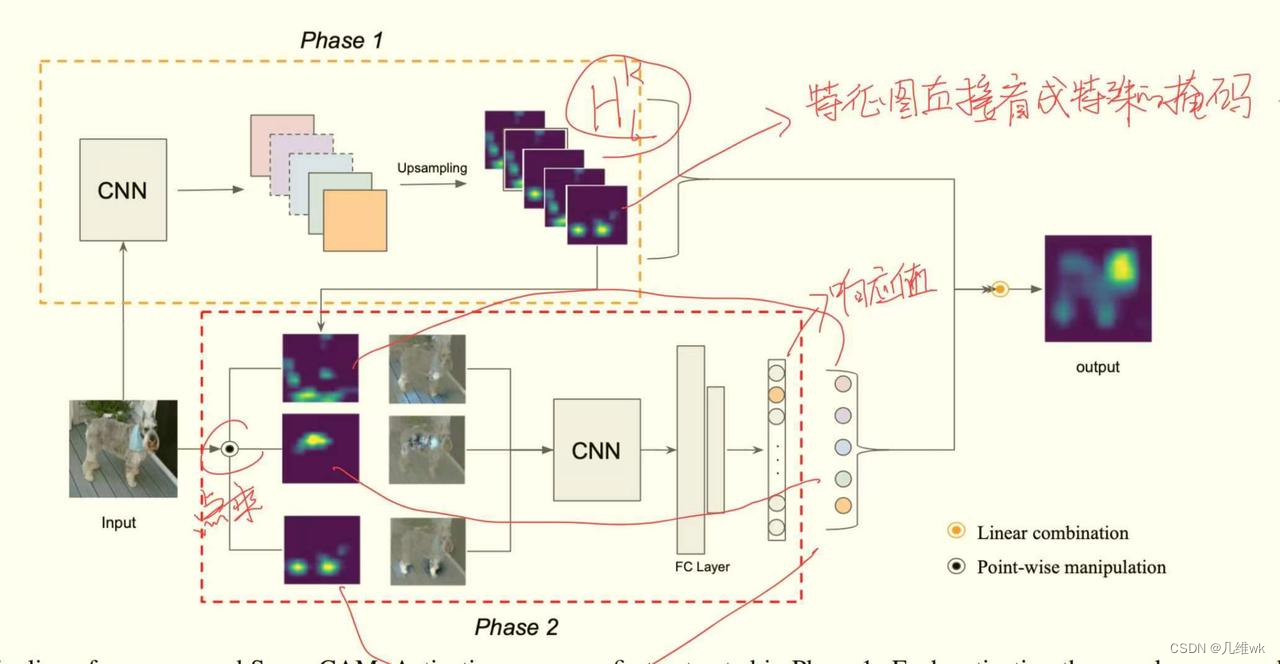
这个方法其实还是遵循经典CAM的范式,那就是加权特征图最后作为最终的类别激活图(CAM)。只不过本文获得权重的方法不依赖梯度,而是通过特征图Mask作用到原图之后网络输出的响应值作为权重。
这个做法很好理解,我们想要确定一个特征图的权重,只需要把这个特征图作为掩码来看特征图对应的图像的区域输入到网络的响应值是怎样的即可,比较符合常识,且完全不用考虑梯度。
效果也还不错:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/a08cc973bc6486d6526eeb6cefcdb255.png)
6. LayerCAM: Exploring Hierarchical Class Activation Maps for Localization
这篇文章在2021年发表在TIP上。本文提出的方法还算有创新性,但是内容并不多,所以这篇文章大量的篇幅都在分析Grad-CAM和Grad-CAM++的不足,以及LayerCAM的设计的来源和实验部分。
6.1 动机
用特征图的最后一层去做CAM,存在分辨率低、定位区域粗糙的问题,这限制了需要精确定位的弱监督任务的性能。
Grad-CAM和Grad-CAM++方法利用最后一层特征进行显著性图生成时激活小而粗糙,而浅层的特征有很大的空间分辨率,自然可以想到应用Grad-CAM到浅层特征,但是由于Grad-CAM存在假正激活的情况,所以直接使用还有问题。并且浅层的目标核背景特别多,一个特征图只给一个权重值不能避免激活出背景区域的噪声,也不能定位准确。

6.2 方法
本文的方法其实比较简单,一共分为三步:
- 获取k层特征图的每个像素的正梯度值,作为激活权重。
- 给k层特征图的每个像素值乘以激活权重。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/99c5566d555e3e24d1f5bf4ce773ffb1.png)
- k个特征图激活的结果线性相加。
结果看着确实比之前的方法都精细。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d1d4afc3b8c6d3567242d5527d525f9b.png)


















 2278
2278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









