







kafka 高吞吐设计分析
说明
- 本文基于 kafka 2.7 编写。
- @author blog.jellyfishmix.com / JellyfishMIX - github
- LICENSE GPL-2.0
概括
支撑 kafka 高吞吐的设计主要有以下几个方面:
- 客户端 producer 和 consumer:
- 端到端压缩。
- producer 异步发送。
- producer 内存池设计。
- 服务端 broker:
-
网络 nio 主从 reactor 设计模式
-
顺序读写。
-
零拷贝。
-
客户端 producer 和 consumer
- producer 开启压缩后是批量压缩,broker 不解压没有解压消耗,consumer 批量拉取并解压,实现端到端压缩。
- producer 异步发送,业务线程执行 send 发送消息时,只是向内存中暂存消息就执行结束了。producer 有 sender 线程负责循环在积累一定条数(可配置)消息后,批量发送至服务端 broker。
- producer 内存池设计,消息的暂存使用了堆外内存,减小 gc 管理内存的压力。同时通过内存池的复用,节约重复向操作系统申请内存的开销。
服务端 broker
网络 nio 主从 reactor 设计模式
- nio 主从 reactor 模式和 tomcat, netty 类似。nio 主从 reactor 模式请见文章: https://blog.csdn.net/weixin_43735348/article/details/128445926
- 采用主从 reactor 的原因: acceptor 线程专门负责建立连接, selector 线程。acceptor 和 selector 线程资源隔离,且两个资源各自可以根据压力扩展线程数。
顺序读写
- kafka 写日志文件的时候用的是追加消息的形式,只在文件尾部顺序写消息。读时在文件头部顺序读取消息。不涉及修改消息,所以不需要随机写。
- 这样的设计即使用的是传统机械硬盘,访问速度也快。操作系统和硬件对顺序写和顺序读有优化,具体采用的是后写和预读(读时连带读出附近的页)。另外机械硬盘磁针寻址也对顺序读写更友好,对于机械硬盘大概顺序写比随机写快 3 个数量级。
零拷贝
- 非零拷贝发送数据过程: 用户执行系统调用读磁盘,用户态切换成内核态。硬盘上的数据通过 DMA 读入内核空间后,cpu 拷贝至用户空间,切换回用户态。执行网络 IO 系统调用,用户态切换成内核态,cpu 拷贝数据至内核空间(socket 缓存),通过 DMA 写入网卡。
- 存在两次 cpu 拷贝和两次内核态用户态切换浪费。
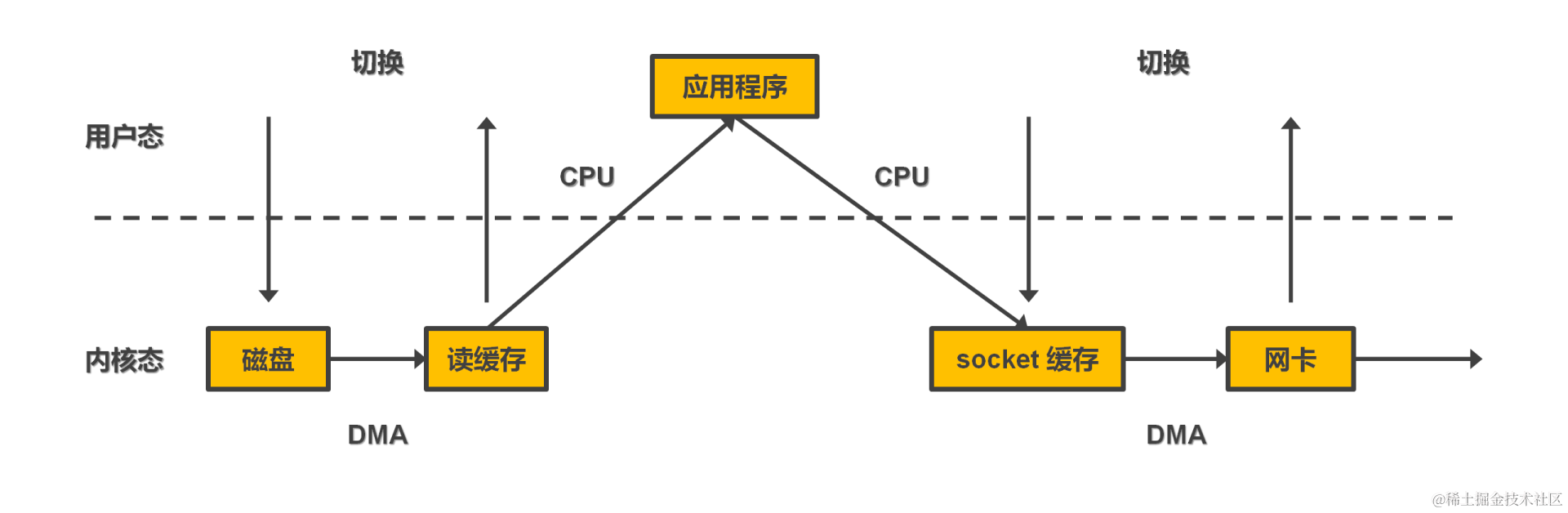
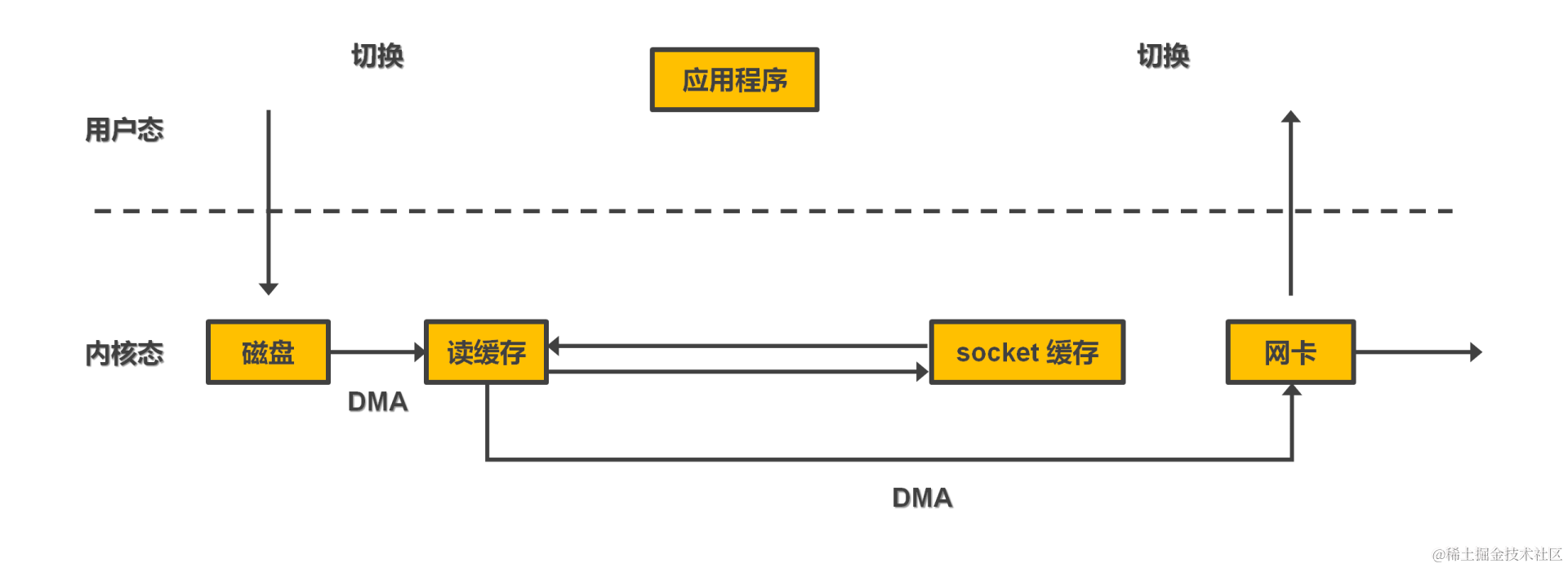
- 零拷贝基于操作系统提供的系统调用 – sendfile()。用户执行系统调用切换至内核态,DMA 从硬盘拷贝数据至内核空间,socket 缓存写入内核空间中数据的地址等描述信息。由 DMA 把数据从内核空间传递至网卡。这样可节约两次 cpu 的拷贝开销。
















 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











