







简介
内存碎片——如下,在堆上分别按照16字节、8字节、16字节、4字节、8字节将该快内存申请走,白色区域是使用完之后释放回来的,但是蓝色区域的还没释放回来。此时空余的内存空间共有40字节,但是这个时候再想要申请大于16字节小于40字节的空间,却申请不出来。
内存碎片分为内碎片和外碎片:
内部碎片的产生:因为所有的内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址或者因为MMU的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配给客户。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44字节、48字节等稍大一点的字节,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。
外部碎片的产生:频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。假设有一块一共有100个单位的连续空闲内存空间,范围是0~99。如果你从中申请一块内存,如10个单位,那么申请出来的内存块就为0~9区间。这时候你继续申请一块内存,比如说5个单位大,第二块得到的内存块就应该为10~14区间。如果你把第一块内存块释放,然后再申请一块大于10个单位的内存块,比如说20个单位。因为刚被释放的内存块不能满足新的请求,所以只能从15开始分配出20个单位的内存块。现在整个内存空间的状态是0~9空闲,10~14被占用,15~34被占用,25~99空闲。其中0~9就是一个内存碎片了。如果10~14一直被占用,而以后申请的空间都大于10个单位,那么0~9就永远用不上了,变成外部碎片。

池化技术
用一个池子放较大一块内存,用的时候取,不用的时候换回来,用以降低内存申请和释放的消耗。
内存池(Memory Pool)是一种内存分配方式。通常我们习惯直接使用new、malloc等API申请分配内存,这样做的缺点在于:由于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能。内存池则是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存。这样做的一个显著优点是尽量避免了内存碎片,使得内存分配效率得到提升。
(1)针对特殊情况,例如需要频繁分配释放固定大小的内存对象时,不需要复杂的分配算法和多线程保护。也不需要维护内存空闲表的额外开销,从而获得较高的性能。
(2)由于开辟一定数量的连续内存空间作为内存池块,因而一定程度上提高了程序局部性,提升了程序性能。
(3)比较容易控制页边界对齐和内存字节对齐,没有内存碎片的问题。
(4)当需要分配管理的内存在100M一下的时候,采用内存池会节省大量的时间,否则会耗费更多的时间。
(5)内存池可以防止更多的内存碎片的产生
(6)更方便于管理内存
现代的很多开发环境都是在多核多线程的情况下,这样就会在申请内存的时候存在,激烈的锁的竞争问题。高并发内存池解决了如下的问题:
(1)内存碎片问题
(2)性能问题
(3)多核多线程下——锁的竞争问题。
一页4k,最大可以在内存池申请到128页的内存,超过128页的直接向内存获取一个最大页,也就是128页。
高并发内存池在一般情况下并不比malloc快,只是在并发的时候比malloc快。
ThreadCache——解决性能问题
线程缓存是每个线程所独有的,用于小于128k的内存进行分配。(大于128k的直接找系统申请,因为出现这样的场景其实并不多)每个线程都有自己的thread cache, 所以从这里获取内存无需加锁,这就保证了并发内存池的高效性。
每一个Thread_Cache都是一个哈希映射的自由链表,使用哈希映射一个存储不同大小数据块的内存块池,通过根据不同大小的对象,构建不同大小的内存的分配器,进行内存的高效分配。自由链表本质上就是一个指针数组,但是我们把每个指针都定义成了一个对象,所以也可以称其为对象数组,每个对象有两个成员,每一个对象是一个_freeList,_freeList后面有一个指针,指向了后面的内存对象块,_num记录了内存对象的个数。
此处图放大看更清晰-------->

CentralCache——解决多核多线程下,锁的竞争问题以及均衡资源
中心缓存是所有线程所共享的,Thread_Cache是按需从Central_Cache中获取的对象。Central_Cache周期性的回收Thread_Cache中的对象,避免了一个线程占用太多的内存,而其他线程的内存吃紧。达到内存分配在多个线程中更均衡的按需调度的目的。Central_Cache是存在竞争的,所以从这里取内存对象是需要加锁的,不过一般从这里取内存对象的效率比较高,所以这里的竞争不是很激烈。
Thread Cache资源分配不均衡,Central Cache是进行均衡的,避免某个Thread Cache使用资源太多了。Thread Cache当中闲置的内存对象个数超过了单次向系统申请的上限个数之后,就进行一定程度的回收。
在这里加的锁称为桶锁,也就对每个不同大小的SpanList分别加锁,这样如果一个线程要申请8Bytes和另一个线程要申请24Bytes是不会产生竞争的,大大减少了锁的竞争,这里也是提高性能的关键之所在。
Central_Cache下面挂的是一个个span,span是一些内存对象的集合,这些内存是以页为单位的,记录页号,页的数量,span中自由链表对象大小,以及内存对象使用的数量。
此处图放大看更清晰-------->

PageCache
页缓存是在Central_Cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的。CentralCache没有内存对象时,从PageCache分配出一定数量的Page,并切割成定长大小的小块内存,分配给CentralCache,同时PageCache会回收CentralCache满足条件的Span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
PageCache的映射规则和CentralCache的结构不同,span是以页为单位进行映射的,当Central_Cache中的内存满了之后,就会从Central_Cache中将内存还给Page_Cache,这是就需要页号,找到上一个页号和下一个页号,将其连接起来。
此处图放大看更清晰-------->

TLS——thread local storage
如何保证每个线程在使用高并发内存池的时候,各自拥有自己的线程缓存,而互相不干扰呢?
在这里我们使用——TLS, 线程本地存储就可以做到。它的使用非常之简单, 只要对变量的声明使用__declspec(thread)就可以了。
具体如下:
_declspec (thread) static ThreadCache* pThreadCache = nullptr;设计模式——单例模式
为了保证全局只有唯一的CentralCache和PageCache,所以这两个类都被设计成了单例模式。具体是用单例模式中的饿汉模式来进行创建的,这样的话这两部分在main含糊之前创建了。
为什么不用懒汉模式?
懒汉模式在第一次调用时才创建,多个线程第一次调用时,需要加锁,一加锁效率就会降低,所以不建议使用懒汉模式。
所以这里用的是饿汉模式,本身就是线程安全的,它在main函数之前就创建,而线程是在main函数之后才创建的,这样的话,就不用加锁了,也无需双重检查。
内存申请过程
此处图放大看更清晰-------->

小细节
(1)在PageCache获取内存时,会从1页的SpanList开始遍历,知道找到对应所需的页面大小的Span,如果没有的话,会找到第一个比它大的进行分割,比如需要一个2页的span,只找到了第一个比2页大的,也就是48页的span,PageCache会将48页的分割成2页的和46页,返回CentralCache2页的。然后将46页的挂会PageCahce对应46下标的spanlist中。
(2)之所以向系统申请最大页的span,原理同上,能这样能够容纳更多的需求。
(3)内存对齐和页面实现的进制,均尽可能地使用位运算,以提高效率。
(4)在CentralCache的每个Span都有一个使用计数,也就是_usecount,也就是对应Span中被ThreadCache拿走的内存对象个数,当_usecount为0时,会根据资源情况,将其还给PageCache进行页的合并。
(5)ThreadCache在向CentralCache获取内存时,存在线程安全问题,但是因为设计了桶锁的缘故,大大减少了锁的竞争。
内存释放过程
此处图放大看更清晰-------->

小细节
(1)PageCache的_idSpanMap中的映射关系会在页的分裂与合并中不断更新。
(2)向系统直接申请或者释放内存时,在Windows平台用的是 VirtualAlloc 和 VirtualFree。
项目测试
单元测试
第一步:在只实现了线程缓存类的时候对其进行单元测试,虽然其他类还没有实现,但是可以利用数据模拟现对其进行测试。
void UnitThreadCache()
{
ThreadCache tc;
vector<void* > v;
for (size_t i = 0; i < 21; ++i)
//为什么要申请21次内存?
//(num==20)让程序运行的时候既走if语句,也走一else语句,都试试(白盒测试)
{
v.push_back(tc.Allocte(7));//申请7个字节
}
for (size_t i = 0; i < 21; ++i)
{
printf("[%d]->%p\n", i, v[i]);
}
for (auto ptr : v)
{
tc.Deallocte(ptr, 7);
}
}
此时,虽然后面的模块没有实现,但是可以用数据模拟的方式,先验证该单元的功能和逻辑。
如果一个线程想要申请7个字节,那么会从中心缓存中一次性申请20个内存对齐的内存对象,虽然它只使用一个,但是之后再用的话,就不用再获取了,待20个使用完了,还需要再次使用7个字节的内存,就会再次从中心缓存中一次性申请20个内存对齐的内存对象。
如图左所示,7个字节内存对齐之后是的内存大小为8个字节的内存对象,所以第一次申请的时候前20个内存对象(对应下标[0,19])的是连续的,间隔是8个字节;下标为20的内存对象是第二次申请的,所以地址跟前20个是不连续的。
第二步:对处理内存对齐进行单元测试。
[1,128] 以8byte对齐 对应freelist[0,16) <--- 128/8 = 16
[129,1024] 以16byte对齐 对应freelist[16,72) <--- (1024-128)/16 + 16= 72
[1025,8*1024] 以128byte对齐 对应freelist[72,128) <--- (8*1024-1024)/128 + 72 = 128
[8*1024 + 1,64*1024] 以1024byte对齐 对应freelist[128,184)<---(64*1024 - 8*1024)/1024 + 128 = 184
根据边界值分析和等价类划分来测试每一种情况:

第三步:当内存池中的内存不够用的时候,回向对向系统申请一块最大限制的内存,并且对其进行分割。该函数在windows平台上调用VirtualAlloc借口进行申请。

第四步:调试,在对整个项目的内存申请以及释放过程进行测试时,运行崩溃了,具体如下图所示,在将内存对象pushfront的时候为nullptr了。

这个时候,进入调BUG状态,打开VS调试中的并行堆栈窗口,具体如下所示:

在这里显示其中的一个线程在调用函数ReleaseSpanToPageCache之后发生了崩溃。双击到该函数,发现span的_pagesize为越界了,具体如下:
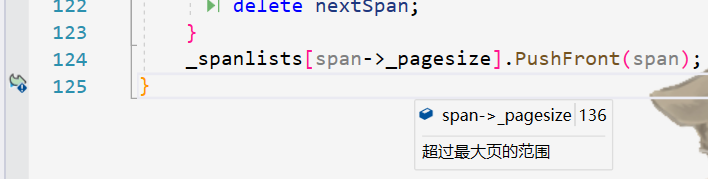
经过分析,是因为在ReleaseSpanToPageCache函数内部中主要实现了span的向前合并和向后合并,但是在合并过程中,忽略了控制合并之后的页面大小,也就是说,两个页面合并之后的页面大小超出了MAX_PAGES的大小,从而导致了越界崩溃的问题。
在发现问题所在之处以后,立马对函数进行了纠正,在合并过程中加入了对合并之后页面大小的控制。
性能测试及优化
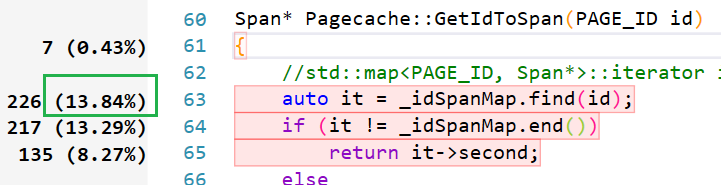
利用VS中的性能探查器对高并发内存池的性能进行检测,发现在查找储存在_idSpanMap的映射关系时所用到的find函数,消耗了大部分性能,因此还需要对此进行优化。

经查阅得知,map底层是红黑树实现的,因此它的find函数时间复杂度为O(logn),而unordered_map底层是哈希表实现的,因此它的find函数时间复杂度为O(1),因此,在这里我将存储映射关系的map换成了unorder_map。
性能优化之后,再次用性能探查器进行探查,发现find所消耗的性能大大下降。
malloc在多线程并发情况下进行对比
对比malloc进行测试,用malloc和ConcurrentMalloc,申请4个线程并发执行4轮,每轮申请或者释放10000次,对比其所申请内存的时间和释放的时间以及总时间,发现其性能高于maollc的范围在10%~30%左右。
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
size_t malloc_costtime = 0;
size_t free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(ConcurrentMalloc(16));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += end1 - begin1;
free_costtime += end2 - begin2;
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime);
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime);
printf("%u个线程并发concurrent_malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}
int main()
{
cout << "==========================================================" << endl;
BenchmarkMalloc(10000, 4, 10);
cout << endl << endl;
BenchmarkConcurrentMalloc(10000, 4, 10);
cout << "==========================================================" << endl;
return 0;
}运行结果如下:

项目的不足之处
1. 项目独立性不足:
当前实现的项目中我们并没有完全脱离malloc,比如在内存池自身数据结构的管理中,如SpanList中的span等结构,我们还是使用的new Span这样的操作,new的底层使用的是malloc,所以还不足以替换malloc,因为们本身没有完全脱离它。
解决方案:项目中增加一个定长的ObjectPool的对象池,对象池的内存直接使用brk、VirarulAlloc等向系统申请,new Span替换成对象池申请内存。这样就完全脱离的malloc,就可以替换掉malloc
2. 平台及兼容性:
(1)Linux等系统下面,需要将VirtualAlloc替换为brk等。(这是个小问题)
(2)x64系统下面,当前的实现支持不足。比如:id查找Span得到的映射,我们在改进之后使用的是unordered_map。在64位系统下面,这个数据结构在性能和内存等方面都是撑不住的,如果需要更进一步的话,可以考虑改进成基数树。















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









