






你是否曾为冗长的报告和海量的数据分析而头疼?
是否曾希望AI能像人类一样理解图像和文字背后的深层含义?
人工智能正在以超乎想象的速度发展,而国产AI领域最近传来重磅消息:Kimi发布了新一代多模态大模型K1.5,在多项测试中表现出色,直逼OpenAI的o1!
这究竟是怎样一款强大的模型?一起来看看!
硬核技术,实力说话
Kimi K1.5究竟有哪些过人之处?我们来划重点:
长上下文扩展
Kimi K1.5 将强化学习的上下文窗口扩展至 128k,通过部分展开(Partial Rollouts)技术显著提高了训练效率。这一技术通过重用先前的轨迹片段来生成新的轨迹,避免了从头生成完整轨迹的高计算成本。随着上下文长度的增加,模型在复杂推理任务上的表现持续提升,为解决更复杂的推理问题奠定了基础。
改进的策略优化
Kimi K1.5 采用了基于长链思维(Long-CoT)的强化学习公式,并结合在线镜像下降法(Online Mirror Descent)的变体进行策略优化。通过有效的采样策略、长度惩罚和数据配方优化,进一步提升了算法的性能。这一改进不仅提升了模型的表现,还为大规模 AI 模型向更复杂的任务挑战迈进了一步。
简洁的框架
Kimi K1.5 的设计摒弃了复杂的蒙特卡洛树搜索、价值函数和过程奖励模型等技术,是通过扩展上下文长度和优化策略,实现了强大的推理能力。使模型在长上下文推理中表现出色,同时具备规划、反思和修正的能力。
多模态能力
Kimi K1.5 在文本和视觉数据上进行了联合训练,能同时处理文本和视觉信息,具备跨模态推理的能力。在多个基准测试中,Kimi K1.5 的多模态推理能力表现出色,例如在 MathVista 测试中达到 74.9 的通过率。
Long2Short 技术
Kimi K1.5 提出了一种将长链思维模型的推理能力迁移到短链思维模型的方法,包括模型融合、最短拒绝采样、DPO(成对偏好优化)和 Long2Short RL(强化学习)。这些方法显著提高了短链推理模型的性能和 Token 效率。
性能炸裂,硬刚OpenAI
光说不练假把式!Kimi K1.5在多项权威测试中表现优异,甚至可以和OpenAI的o1正面PK!
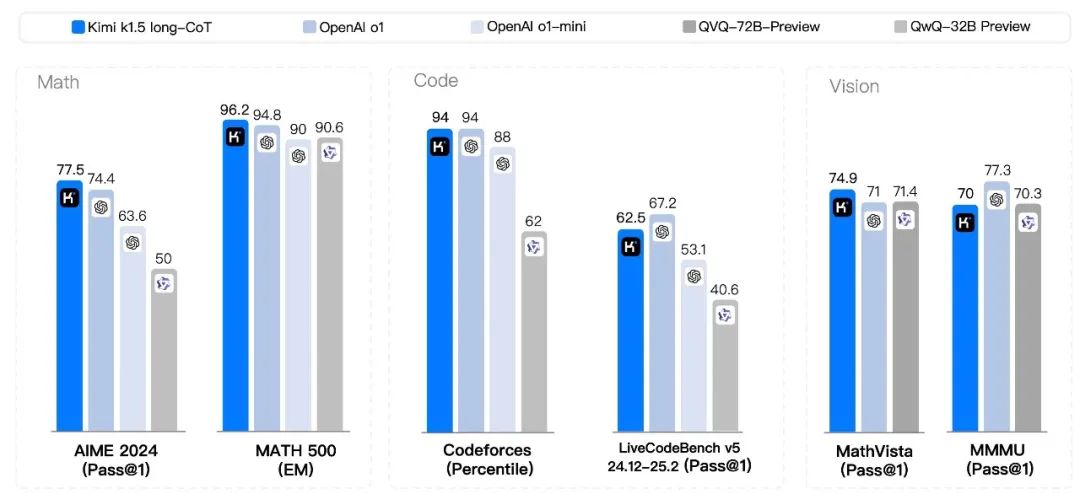
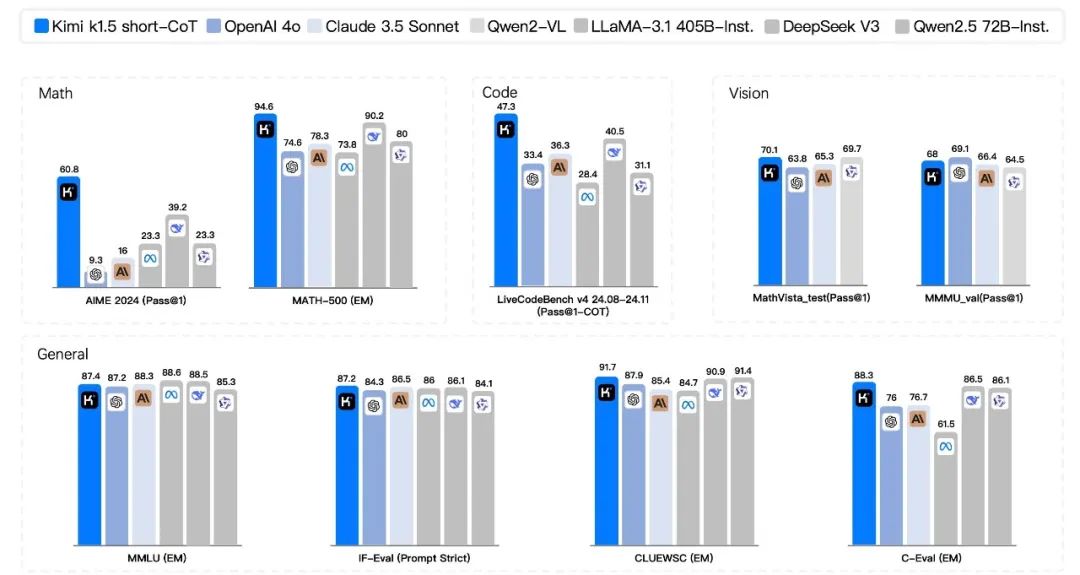
数学推理测评
-
AIME 2024 测试:在 AIME 2024 测试中,Kimi K1.5 的 Long-CoT 模式达到了 77.5 的通过率,Short-CoT 模式也达到了 60.8 的通过率。
-
MATH-500 测试:在 MATH-500 测试中,Kimi K1.5 的 Long-CoT 模式取得了 96.2 的准确率,Short-CoT 模式也有 94.6 的准确率。
代码生成测评
-
Codeforces 测试:在 Codeforces 测试中,Kimi K1.5 达到了 94 百分位的排名。
-
LiveCodeBench 测试:在 LiveCodeBench 测试中,Kimi K1.5 的 Short-CoT 模式达到了 47.3 的通过率。
视觉多模态测评
-
MathVista 测试:在 MathVista 测试中,Kimi K1.5 达到了 74.9 的通过率。
-
MMMU 测试:在 MMMU测试中,Kimi K1.5 的 Long-CoT 模式达到了 70的通过率,Short-CoT 模式也有 68 的通过率。
理性看待,优劣并存
虽然Kimi K1.5表现出色,但我们也需要理性看待其优势与局限:
优势
-
强大的多模态推理能力:Kimi K1.5 在多模态任务上表现出色,能够处理复杂的视觉和语言信息,实现跨模态的推理和理解。
-
高效的强化学习框架:其独特的强化学习框架和 Long2short RL 技术,使得模型在长推理和短推理任务上都能取得优异的性能。
-
与 OpenAI o1 竞争力相当:在多项测试中,Kimi K1.5 与 OpenAI o1 相比毫不逊色,甚至在某些方面略有优势。
局限
-
对数据的依赖:尽管 Kimi K1.5 在性能上取得了显著提升,但仍然依赖大量的高质量数据进行训练,数据的质量和多样性对模型的性能有着重要影响。
-
计算资源需求高:训练和运行 Kimi K1.5 需要大量的计算资源,这对于一些小型企业和研究机构来说可能是一个挑战。
-
模型的可解释性:与许多深度学习模型一样,Kimi K1.5 的决策过程和推理逻辑仍然难以解释,这在一些对可解释性要求较高的应用场景中可能会受到限制。
Kimi K1.5的发布,无疑是中国AI领域的一次重要突破。
让我们共同期待,Kimi K1.5能为我们的生活带来更多惊喜!

















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









