







 pytorch应用1.con1d应用于文本数据,只对宽度进行卷积。如下图所示,max_length=7,word_embedding_dim=5,在使用con1d时,我们需要将75的permute成57的,因为con1d只会对文本数据的最后一维进行卷积,也就是说卷积窗口的高度等于word_embedding_dim,只会在宽度max_length方向上滑动。torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, paddin
pytorch应用1.con1d应用于文本数据,只对宽度进行卷积。如下图所示,max_length=7,word_embedding_dim=5,在使用con1d时,我们需要将75的permute成57的,因为con1d只会对文本数据的最后一维进行卷积,也就是说卷积窗口的高度等于word_embedding_dim,只会在宽度max_length方向上滑动。torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, paddin
一、pytorch应用
主要应用就是textcnn,以及bert下游任务中可以尝试,一般结构上con1/2d+relu+maxpool1/2d。
1.conv1d
应用于文本数据,只对宽度进行卷积。如下图所示,max_length=7,word_embedding_dim=5,在使用con1d时,我们需要将7 *5的permute成5 *7的,因为conv1d只会对文本数据的最后一维进行卷积,也就是说卷积窗口的高度等于word_embedding_dim,只会在宽度max_length方向上滑动。
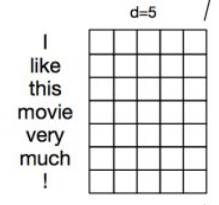
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
参数:
in_channels:词向量的维度
out_channels:卷积核数量,就是有多少个filter
kernel_size:卷积核的宽度(尺寸),实际上这里卷积核的高度默认in_channels,只需要输入一个int表示卷积核的宽度,所以卷积核的尺寸为in_channels*kernel_size
stride:滑动步长,默认1
padding:对输入的每一条边,补充0的层数
输入
(batch_size, word_embedding_dim, max_length)
对最后一维进行卷积,所以输入需要做permute将max_length放在最后一维
输出
(batch_size, out_channels, (max_length-kernel_size+2 *padding)//stride + 1)
下面举个栗子,可以自己动手算一下。
conv1 = nn< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









