







一、encoder
1. 输入
输入分为两部分,input embedding和positional encoding,下面具体讲一下。
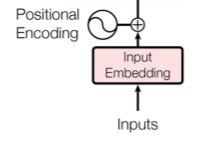
1.1 input embedding
这里和大多数nlp任务一样,将文字转为embedding,操作上具体来说就是将字/词映射为已有的vocab。假设映射后的input embedding的size为 (max_len, embedding_dim)。
1.2 positional encoding
self-attention并不能像rnn一样捕捉到序列的顺序信息,在nlp中序列顺序信息是非常重要的,所以我们通过positional encoding将顺序信息加入到input embedding中。在上面的架构图中可以看到,二者是矩阵相加,这就意味着二者的size是相同的,即 (max_len, embedding_dim)。
文中给出的计算positional encoding公式如下,其中PE的下标pos表示所在行,2i和2i+1表示所在偶数列和奇数列。代码实现如下。
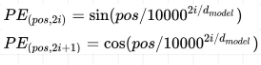
class Positional_Encoding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









