







 文章探讨了噪声的分类、产生原因及其影响,介绍了噪声处理的理论和方法,包括数据层面的清洗(如直接删除法、KNN去噪等)、算法层面的主动学习(如不确定性和委员会选择)以及模型层面的鲁棒性增强(如错误样本权重调整和损失函数设计)。以SVM和AdaBoost为例,展示了如何通过调整权重和设计适应噪声的损失函数提高模型鲁棒性。
文章探讨了噪声的分类、产生原因及其影响,介绍了噪声处理的理论和方法,包括数据层面的清洗(如直接删除法、KNN去噪等)、算法层面的主动学习(如不确定性和委员会选择)以及模型层面的鲁棒性增强(如错误样本权重调整和损失函数设计)。以SVM和AdaBoost为例,展示了如何通过调整权重和设计适应噪声的损失函数提高模型鲁棒性。
3.1 噪声的分类、产生原因与影响
噪声分为属性噪声和标签噪声,产生原因如下:
- 特定类别的影响,类别相似产生噪声;
- 标注的人为影响,少数类样本更容易形成噪声;
- 训练集被恶意投毒;
3.2 噪声处理的理论与方法
噪声样本学习参考概率近似正确(PAC)理论,PAC的原理在于错误率被限制在某个极小的数值内就认为结果正确。
噪声的处理方法分为数据层面,算法层面和模型层面;数据层面:识别噪声,清洗后再训练模型;算法层面:使用算法对噪声过滤;模型层面:构造训练对噪声鲁棒的模型。
3.3 基于数据清洗的噪声过滤(数据层面
原理:假设噪声样本是分类错误的样本,消除或者纠正训练数据中的错误标签,变成普通分类问题。方法有直接删除法,基于最近邻的去噪方法,集成去噪法。
- 直接删除法
直接在数据集匹配错误样本删除掉。具体是把看起来比较可疑的实例或分类错误的训练实例删掉,判断错误实例可以使用边界点发现之类的数据挖掘方法。 - 基于最近邻的去噪方法
利用类似KNN的方法,k较小的时候噪声会导致近邻样本分类错误,当发现若干样本都是由同一邻居引起的那么邻居可能是噪声;除了KNN,CNN,RNN,ENN都有类似的应用。 - 集成去噪法
若干分类器的集成使用判断是否为噪声。
3.4 主动式噪声迭代(算法层面
数据清洗对于离群点的噪声的合适的但是有些噪声和错分样本没有明显差异,特别是分类边界的样本,因此引入了主动学习框架,其通过迭代抽样的方式将特定的样本挑选出来交给专家人工判断。
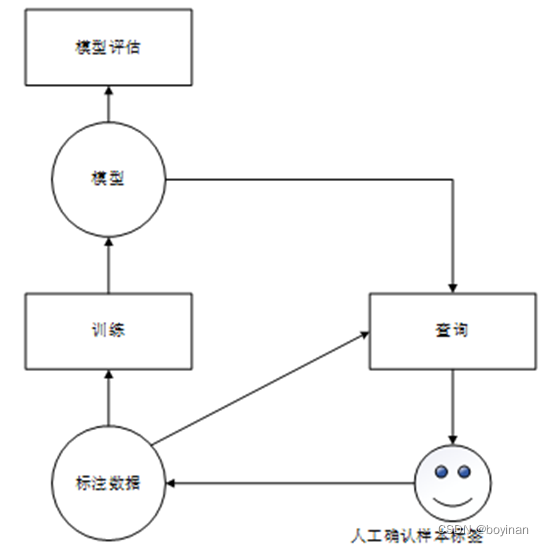
主动学习框架分为:训练和查询。
训练:利用学习算法对已标注样本学习获得分类器模型,利用这些样本提升未知噪声的检测效率。方法可以是监督学习,半监督学习。
查询:一部分样本来自于样例选择算法训练好的模型中的数据,另一部分来自于标注数据,选择后确认的样本加入训练数据集。
上述两部分的关键点在于如何选择样本供人工标注。
基于池的样本选择算法:通过选择当前基准分类器最不能确定其分类类别的样例进行人工标注;
基于流的样本选择算法:按照数据流的处理方式,在某个时间窗内采用基于池的样本选择算法。
两种算法的关键都在于基于池的样本选择算法,有基于不确定性采样的查询方式,基于委员会的查询方式,基于密度权重的查询方式。
- 基于不确定性采样的查询方式
将分类模型难以区分的样本提取出来,关键在于如何衡量是否难以区分,采用的方法为:最小置信度,边缘采样,熵。(具体内容 公式 - 基于委员会的查询方式
主动学习中采用集成学习作为分类器模型,选择策略考虑到每个基分类器的投票情况,通过基于投票熵和平均K-L三都选择样本。(具体内容 公式 - 基于密度权重的查询方法
难以区分的边界样本一般具有密度较大的特点,密度权重的查询方法考虑了样本密度的影响优先选择区域密度高的样本。 - 梯度长度期望,方差约简策略等。
3.5 噪声鲁棒模型(模型层面
在机制上可以从错误样本权重调整,损失函数设计等角度提升鲁棒性。
3.5.1 错误样本权重调整
例如以SVM为例,其目标学习函数是f(x)=wx+b,其中w是所有训练样本的权重向量,假如在训练时能自动调整权重便可以使得模型有鲁棒性。
本文选择的算法是AdaBoost算法,根据测试结果提升错误分类的样本权重,从而下一个训练器接受样本的时候会格外重视错误样本。(算法的具体过程 原理:正确的时候权重占比小,错误的时候权重占比大,在下一轮的迭代中会受到重视。
3.5.2 损失函数的设计
在损失函数中处理噪声,依赖于先验知识,无监督或半监督的学习。
1)选择噪声敏感算法为每个样本打分,典型的方法有KNN,SVM,AdaBoost等;
2)把置信度引入损失函数中(例如KNN的K 和 AdaBoost的一些算法改变 具体实例公式
3)不同的损失函数,例如0-1损失函数,绝对值损失,平均误差等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









